数据库
数据库
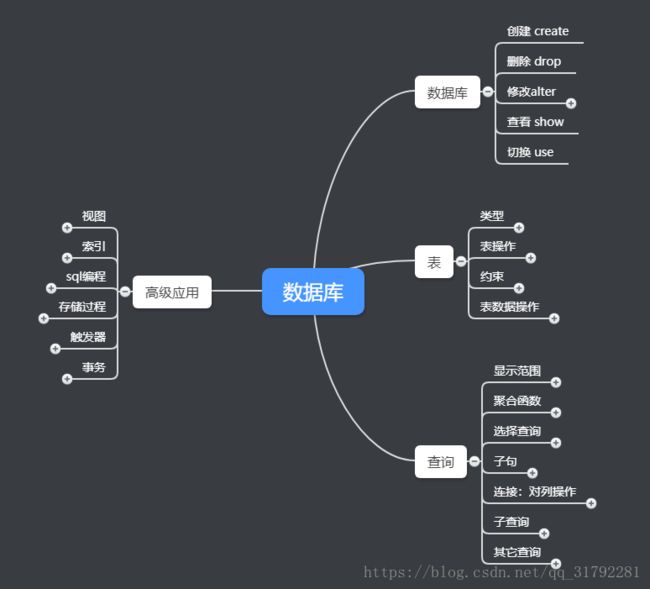
一、数据库
1、创建 create
create database school2、删除 drop
drop database school3、修改alter
设置编码
alter database school set CharacterEncoding=utf-84、查看 show
show databases5、切换 use
use school二、表
1、类型
1)数值
bit:0-1
int:- 2的31次方到2的31次方-1
bigint:- 2的63次方到2的63次方-1
float:存放小数,不推荐使用
numeric:小数,推荐使用这个2)字符串
char:定长,最大8000字符
char(10):前几个字符放数据,后面补空格。
varchar:变长,最大8000字符
varchar(10):使用多少,分配多少字符,注意要小于等于10
ntext:可变长度Unicode数据的最大长度为2的30次方-1 存储各种文字
text:可变长度非Unicode数据的最大长度为2的31次方-1 存储英文3)时间
datetime:表示日期,getdate()获取日期,年月日 时分秒.毫秒
timestamp:时间戳4)其它类型
- 图片:image
- 视频:binary
2、表操作
1)创建 create
create table student
(
sid int primary key,
sname varchar(20),
sage int
)2)删除 drop
drop table student3)修改 alter
删除列
alter table student drop column sage添加列
alter table student add sage int4)查看show
show tables3、约束
1)主键约束 primary key
(1)约束
create table student
(
sid int primary key,
sname varchar(20),
sage int
)(2)自增
mysql
create table student
(
sid int auto_increment primary key,
sname varchar(20),
sage int
)sql server
create table student
(
sid int identity(1,1) primary key,
sname varchar(20),
sage int
)2)外键约束 foreign key
create table course
(
cid int auto_increment primary key,
cname varchar(20),
ccredit int
)
create table sc
(
sid int,
cid int,
grade int,
primary key(sid,cid),
foreign key(sid) references student(sid),
foreign key(cid) references course(cid)
)3)唯一约束 unique
create table course
(
cid int auto_increment primary key,
cname varchar(20) unique,
ccredit int
)4)检查性约束 check
mysql使用check约束不起作用,会被直接忽略。
create table course
(
cid int auto_increment primary key,
cname varchar(20) unique,
ccredit int check(ccredit>=0.5 and ccredit<=5)
)5)默认约束 default
create table student
(
sid int auto_increment primary key,
sname varchar(20),
sage int,
ssex varchar(10) default '男'
)6)非空约束 not null
create table student
(
sid int auto_increment primary key,
sname varchar(20) not null,
sage int,
ssex varchar(10) default '男'
)4、表数据操作
1)添加 insert
普通插入
insert into student values(1,'wenxue',22,'男')查询插入
create table student2
(
sid int auto_increment primary key,
sname varchar(20) not null,
sage int,
ssex varchar(10) default '男'
)
insert into student2 select * from student2)修改 update
update student set sage=20 where sid=13)删除 delete
delete from student where sid=1三、查询
1、显示范围
1)行范围
all:显示所有记录,包括重复行,是默认值。
distinct:显示所有行,但不包括重复行。
select distinct cid from sctop:显示前n行,只在sql server中使用。
select top 5 * from student2)列范围
*:显示所有属性列。
属性集:显示所需要的属性列。
3)修改标题
直接给出列名
select sid 学号,sname 姓名 from studentas
select sid as 学号,sname as 姓名 from student=:仅sql server支持。
select sid=学号,sname=姓名 from student4)列值运算
select sname 姓名,sage+10 十年后的年龄 from student2、聚合函数
sum(列名):求数字列的总和。
select sum(sage) from studentavg(列名):对一个数字列计算平均值。
select avg(sage) from studentmin(列名):返回一个数字、字符或日期列的最小值。
select min(sage) from studentmax(列名):返回一个数字、字符或日期列的最大值。
select max(sage) from studentcount(列名):返回一个列的数据项数,一般会加distinct关键字,进行去重,不然和带*的基本没什么区别。
select count(sage) from studentcount(*):返回查询到的行数。
select count(*) from student3、选择查询
1)比较运算符
=、<、>
<=、>=、!=select * from student where sage>212)确定范围
between and、not between and--包含边界22、23
select * from student where sage between 22 and 233)确定集合
in、not in适用于可穷举所有元素的集合。
select * from student where ssex in ('男','女')4)字符匹配
like、not like用like进行模糊查询,搜索条件可用通配符。
| 通配符 | 含义 |
|---|---|
| % | 包含零个或多个字符的任意字符串 |
| _ | 任何单个字符 |
| [ ] | 代表指定范围内的单个字符,[ ]中可以是单个字符([abcdef]),也可以是字符范围([a-f]) |
| [^] | 代表不在指定范围的单个字符,[^]中可以是单个字符([^abcdef]),也可以是字符范围([^a-f]) |
select * from student where sname like 'wen%'5)空值
is null、is not nullselect * from student where sage is null6)多重条件
and、or、notselect * from student where sage=21 and sname like 'wen%'4、子句
1)分组 group by
select ssex 性别,count(ssex) 人数 from student group by ssex结果:

当完成数据结果的查询和统计后,可以使用having关键字来对结果进行进一步的筛选。
select ssex 性别,count(ssex) 人数 from student group by ssex having count(ssex)>2结果:
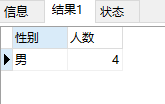
having与where比较:where子句是对整表中数据筛选满足条件的行,having子句是对group by分组查询后产生的组加条件,筛选满足条件的组,并且having子句中使用聚合函数,where子句中不能使用聚合函数。
统计每个专业的男女生人数
select sdep,ssex,count(*) from student group by sdep,ssex2)排序 order by
语法格式:
order by {order_by_expression [asc | desc]}- order_by_expression:指定要排序的列,可以指定多个列。
- asc:表示升序。
- desc:表示降序。
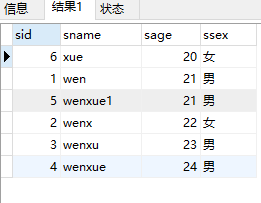
select * from student order by sage结果:
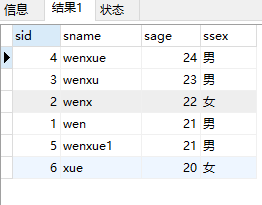
select * from student order by sage desc结果:
5、连接:对列操作
1)内连接
内连接把两个表的数据连接生成第三个表,第三个表中仅包含那些满足连接条件的数据行。语法格式:
select select_list from table1 inner join table2 on table1.column1=table2.column2或
select select_list from table1,table2 where table1.column1=table2.column2select sname,cid,grade from student inner join sc on student.sid=sc.sid
select sname,cid,grade from student,sc where student.sid=sc.sid结果:
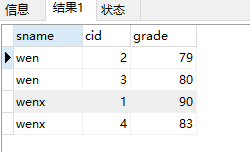
2)左外连接
左外连接是对join左边的表不加限制,返回左表所有行,即使右表没有匹配。

语法格式:
select select_list from table1 left [outer] join table2 on table1.column1=table2.column2select sname,cid,grade from student left join sc on student.sid=sc.sid结果:
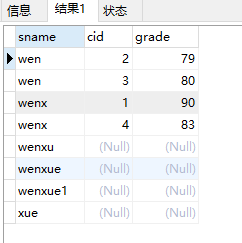
3)右外连接
右外连接是对join右边的表不加限制,返回右表所有行,即使左表没有匹配。
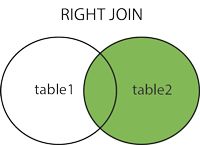
语法格式:
select select_list from table1 right [outer] join table2 on table1.column1=table2.column2select sname,cid,grade from sc right join student on student.sid=sc.sid结果:
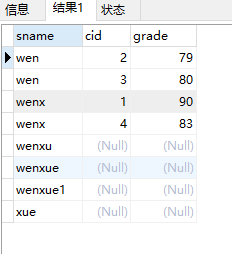
4)全外连接
全外连接对两个表都不加限制,所以两个表中的行都会包括在结果集中。

语法格式:
select select_list from table1 full [outer] join table2 on table1.column1=table2.column2MySQL中不支持 FULL OUTER JOIN
5)交叉连接
交叉连接也被称为笛卡儿乘积,返回两个表的成绩。语法格式:
select select_list from table1 cross join table2select sname,cid,grade from student cross join sc6、子查询
1)无关子查询
无关子查询不依赖于外部查询,它会在外部查询之前执行,然后共外部查询使用,无关子查询中不包含对于外部查询的任何引用。
(1)比较子查询
=、<>、<、>、<=、>=select cid,grade from sc where sid=(select sid from student where sname='wen')结果:
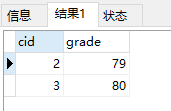
(2)some、any、all、in
all和any的常见用法是结合一个相对比较操作符对一个数据列子查询的结果进行测试,它们测试比较值是否与子查询所返回的全部或一部分值匹配。in的含义是等于子查询所返回的某个数据行。
all:子查询中所有值满足,总条件才满足。
--查询年龄最大的学生信息。
select * from student where age>=all(select age from student)any:子查询中任意一个值满足,总条件就满足。some是any的一个同义词。
--查询任何与网络专业学生同龄的学生的信息。
select * from student where age=any(select age from student where dept='网络')2)相关子查询
相关子查询:子查询的执行依赖于外部查询,多数情况下是子查询的where子句中引用了外部查询的表。
执行过程:子查询为外部查询的每一行执行一次,外部查询将子查询引用的列的值传给子查询,如果子查询的任何行与其匹配,外部查询九返回结果行,再回到第一步,直到处理外外部表的每一行。
(1)比较子查询
--查询成绩比该课的平均成绩低的学生的学号、课程号、成绩
select sid,cid,grade from sc a where grade<(select avg(grade) from sc b where b.cid=a.cid)(2)exists
通过逻辑运算符exists或not exists检查子查询所返回的结果集是否有行存在。
--查询选修了2号课程的学生信息
select * from student where exists (select * from sc where cid=2 and student.sid=sc.sid)7、其它查询
1)联合查询:对行操作
联合查询可以将两个或更多查询的结果组合为单个结果集,该结果集包含联合查询的全部行。
规则:所有查询的列数和列的顺序必须相同,数据类型必须兼容。
语法格式:
select_statement union [all] select_statement- select_statement:参与查询的select语句。
- all:在结果中包含所有行,包括重复行;如果没有指定,则删掉重复行。
--查询选修了1、2号课程的学生
select * from student where exists (select * from sc where cid=1 and student.sid=sc.sid)
union
select * from student where exists (select * from sc where cid=2 and student.sid=sc.sid)结果:

2)except、intersect查询
except运算符返回由except运算符左侧的查询返回、而又不包含在右侧查询所返回的值中的所有非重复值。intersect运算符返回左侧和右侧都返回的所有非重复值。(MySQL中都不支持)
四、高级应用
1、视图
视图是从一个或几个基本表(或视图)导出的表,是一条select语句执行后的结果集。用户可以定义若干视图。因此对用户而言,按ANSI/SPARC报告的观点,他的外模式是由若干基本表和若干视图组成的。
视图和基本表不同,视图是一个虚表,即视图所对应的数据不实际存储在数据库中,数据库中只存储视图的定义(存在数据字典中)。视图一经定义就可以和基本表一样被查询、被删除(DROP),也可以用来定义新的视图,但更新(增、删、改)操作将有一定限制。视图可以理解成一个数据库,只有内涵保存在数据库字典中,而无外延存储,其外延是在使用时动态地生成的或计算出来的。
1)创建视图
SQL建立视图的语句格式为:
Create view 视图名 as select 语句;2)删除视图
视图可以删除,语句格式为:
Drop view 视图名3)查询视图
视图定义后,用户可以如同基本表那样对视图查询。
4)更新视图
对视图的更新最终要转换成对基本表的更新(这里的更新,指INSERT,UPDATE和DELETE三类操作)。在关系数据库中,并非所有的视图都是可更新的,也就是说,有些视图的更新不能唯一地有意义地转换成对基本表的更新。
5)视图的优点
视图的概念具有很多优点,主要有:
a)视图对于数据库的重构造提供了一定程度的逻辑独立性;
b)简化了用户观点;
c)视图机制使不同的用户能以不同的方式看待同一数据;
d)视图机制对机密数据提供了自动的安全保护功能。
2、索引
主键列会自动具有排序的结构,可以提高系统的性能,但是主键只能有一个,我们经常需要多个列具有排序结构,这时便有了索引,我们可以为非主键列建立排序结构,并且可以建立多个,用来快速检索表中数据。
1)创建索引
语法格式:
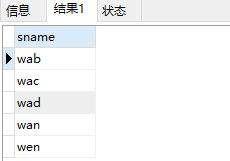
create [unique] [clustered | nonclustered] index index_name on {table_name | view_name}(column_name1,column_name2)create index index_sname on student(sname)当索引列为查询对象时,就会默认调用索引。如:
select sname from student结果:
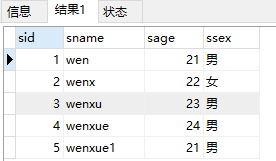
select * from student结果:
--学号升序,课程号降序建索引
create index index_sc on sc(sid asc,cid desc)2)查看索引
mysql
show index from studentsql server
exec sp_helpindex student3)删除索引
语法格式:
mysql
drop index index_name on table_namesql server
drop index table_name.index_name3、sql编程
1)变量
(1)局部变量
定义变量
declare i int unsigned default 0;为变量赋值
set i=1;(2)用户变量
mysql > SELECT 'Hello World' into @x;
mysql > SELECT @x;
+-------------+
| @x |
+-------------+
| Hello World |
+-------------+
mysql > SET @y='Goodbye Cruel World';
mysql > SELECT @y;
+---------------------+
| @y |
+---------------------+
| Goodbye Cruel World |
+---------------------+
mysql > SET @z=1+2+3;
mysql > SELECT @z;
+------+
| @z |
+------+
| 6 |
+------+ 2)参数
create procedure sp_page(agenum int)
begin
select * from user where age>agenum;
end
call sp_page(20)3)选择
(1)if语句
create procedure sp_ptage(agenum int,j char(1))
begin
if j='h' then
select * from user where age>agenum;
elseif j='e'then
select * from user where age=agenum;
else
select * from user where age
end if;
end
call sp_ptage(21,'h')
call sp_ptage(21,'e')
call sp_ptage(21,'l') (2)case语句
create procedure sp_pcase(agenum int,j char(1))
begin
case j
when 'h' then
select * from user where age>agenum;
when 'e' then
select * from user where age=agenum;
else
select * from user where age
end case;
end
call sp_pcase(21,'h')
call sp_pcase(21,'e')
call sp_pcase(21,'l') 4)循环
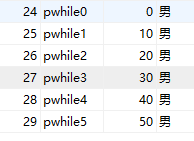
(1)while
while执行循环前进行检查是否满足条件。
create procedure sp_pwhile()
BEGIN
declare i int;
set i=0;
while i<6 do
insert into user(name,age,sex) values(concat("pwhile",i),i*10,'男');
set i=i+1;
end while;
end
call sp_pwhile()结果:
(2)repeat
repeat是执行操作后检查结果是否满足条件。
create procedure sp_prepeat()
BEGIN
declare i int;
set i=0;
repeat
insert into user(name,age,sex) values(concat("prepeat",i),i*10,'男');
set i=i+1;
until i>5
end repeat;
end
call sp_prepeat()效果:

(3)loop
loop在执行过程中,如果满足一定条件就使用leave语句退出循环。
create procedure sp_ploop()
BEGIN
declare i int;
set i=0;
myloop:loop
insert into user(name,age,sex) values(concat("ploop",i),i*10,'男');
set i=i+1;
if i>5 THEN
leave myloop; --退出循环
end if;
end loop;
end;
call sp_ploop()效果:

4、存储过程
1)介绍
存储过程:把一段相似性的sql语句封装起来,进行预编译,当要执行这一段sql语句的时候,通过调用该存储过程来实现会更加的快捷、方便。
2)创建存储过程
语法格式:
create procedure sp_name()
begin
select * from `user`;
end3)调用存储过程
call sp_name()4)删除存储过程
drop procedure sp_name5)查看存储过程
show procedure status4、触发器
1)介绍
出发i去是特殊的存储过程,不同的是存储过程需要使用call语句进行调用,而触发器不需要手动启动,只有当一个预定义的时间发生的时候,就会被mysql自动调用。具有四要素:
- 监视地点
- 监视事件
- 触发时间
- 触发事件
2)创建触发器
语法:
create trigger trigger_name
trigger_time trigger_event on table_name
for each row
begin
......
endtrigger_name:定义触发器的名称。
trigger_time:标识触发时机,取值为before或after。
trigger_event:标识触发事件,取值为insert、update和delete。
在begin...end;之间执行语句列表,不同语句用分号隔开,一般情况下mysql是以分号;作为结束执行语句,与触发器中需要的分行起冲突,为解决此问题可用delimiter $语句设置结束符号为$,$符号并不固定,可以按照自己需求设置。
示例:
delimiter $
create trigger mytrigger before delete on user for each row
begin
delete from card where userid=old.id;
end$
delimiter;
delete from user where id=193)删除触发器
drop trigger trigger_name4)查看触发器
show triggers5)触发数据
mysql中定义了new和old来表示触发了触发器的那一行数据。
- 在insert型触发器中,new表示将要(before)或已经(after)插入的数据。
- 在update型触发器中,old表示将要或已经被修改的原数据,new表示将要或已经修改后的新数据。
- 在delete型触发器中,old表示将要或已经被删除的原数据。
5、事务
1)示例
转账:李三要给赵四转账500元,有以下过程。
- 检测李三的账户余额大于500元。
- 李三: —>支出 500,李三 -500。
- 赵四: —->收到500,赵四 +500。
正常的流程走下来,李三支出500,赵四收到500,当然满足两人要求。如果李三扣了钱之后,系统出故障了呢?李三拜拜损失了500,而赵四也没收到属于它的500。事务的需求就在此,要使得整个过程要么都执行,要么都不执行。
2)四大特性
- 原子性:指一组操作序列,这些操作要么都成功执行,要么都不执行,它是一个不可分割的工作单位。
- 隔离性:在所有的操作没有执行完毕之前,其他会话不能够看到中间改变的过程。
- 一致性:事务发生前,和发生后,数据的总额依然匹配。
- 持久性:事务产生的影响不能够撤消,如果出了错误,事务也不允许撤消, 只能通过”补偿性事务”。
3)开启事务
开启事务命令执行后,变更会维护到本地缓存中,而不维护到物理表中。
begin;或
start transaction;4)提交事务
将缓存的数据变更维护到物理表中。
commit;5)回滚事务
放弃缓存中变更的事务。
rollback;6)使用
我们只需要把需要提交事务的语句放在开启事务和提交事务命令之间即可。
start transaction;
select balance from bank where id=3333;
update bank set balance=balance-500 where id=3333;
update bank set balance=balance+500 where id=4444;
commit;sql综合
create table student
(
sid int auto_increment primary key,
sname varchar(20) not null,
sage int,
ssex varchar(10) default '男'
)
create table student2
(
sid int auto_increment primary key,
sname varchar(20) not null,
sage int,
ssex varchar(10) default '男'
)
drop table student
create table course
(
cid int auto_increment primary key,
cname varchar(20) unique,
ccredit int
)
create table sc
(
sid int,
cid int,
grade int,
foreign key(sid) references student(sid),
foreign key(cid) references course(cid)
)
drop table course
drop table sc
insert into student values(1,'wen',21,'男'),(2,'wenx',22,'男'),(3,'wenxu',23,'男'),(4,'wenxue',24,'男')
insert into student values(5,'wenxue1',21,'男')
insert into student(sname) values('xue')
insert into student2 select * from student
update student set sage=20 where sid=1
delete from student where sid=1
select sid 学号,sname 姓名 from student2
select sid as 学号,sname as 姓名 from student2
select sname 姓名,sage+10 十年后的年龄 from student2
select * from student
select sum(sage) from student
select avg(sage) from student
select min(sage) from student
select max(sage) from student
select count(distinct sage) from student
select count(*) from student
select * from student where sage>21
select * from student where sage not between 22 and 23
select * from student where ssex in ('男')
select * from student where sname like 'wen_'
select * from student where sage is null
select * from student where sage=21 and sname like 'wen%'
select ssex 性别,count(ssex) 人数 from student group by ssex
select ssex 性别,count(ssex) 人数 from student group by ssex having count(ssex)>2
select * from student order by sage
select * from student order by sage desc