来源:https://content.pivotal.io/blog/scoring-as-a-service-to-operationalize-algorithms-for-real-time
如果您只使用数据科学进行一次性的、特别的分析,那么您就做错了。
毫无疑问,公司可以从这种一次性的数据科学实践中获益良多,而且大多数都是从这里开始的。然而,当数据科学能够以一种持续的方式在实时场景中应用时,会产生更多的价值。我们不能仅仅构建一个机器学习(ML)模型并分享其见解,我们必须进入下一步并将其操作化,使其成为我们业务流程的一部分并实时影响结果。例如,当我们可以实时记录人类的动作时,什么是可能的呢?——就像一个系统,它可以告诉你一个人正在以每小时30多英里的速度跑步或移动,而他们本不应该这样做,或者只是摔倒在地。
在这篇文章中,我们列出了基本组件——数据摄取、数据存储、模型训练和模型评分——用于实时数据科学和整个建模管道的操作,所有这些都是部署在关键云计算环境中的微服务。我们还讨论了为什么实时数据科学模型的运行是最关键的,从实时数据科学中获得最多的行业,并引入了以个性化的人类活动分类为中心的实时数据科学管道。
一、大数据科学模型
作为数据科学家,我们花费了大量的时间来准备和分析数据,构建机器学习模型,运行实验,编写一个成功的数据科学项目的代码。成功的数据科学项目的关键是模型运作化(Model operationalization)。
模型操作化是将数据科学管道(包括数据摄取、数据存储、模型训练和模型评分)实现到现实世界中并将其应用到实际数据的过程,在自动化的、低延迟的、影响人的业务活动中。预测模型需要互动、成长和活跃起来(通常是实时的),以真正引起变化和推动行动。模型操作化是数据科学工作流的全部价值所在。为此,生产就绪、高质量的代码是任何数据科学工作流的关键需求,必须采取关键步骤来加强数据流管道、嵌入数据验证检查、支持异常处理和确保模型验证。它们还应该在云本地堆栈上运行,以实现可靠性、可访问性和可伸缩性。
二、实时数据科学的应用
虽然有许多非实时数据科学用例,但实时数据科学是对许多应用程序的需求,包括物联网(物联网)、欺诈检测、风险计算、健康相关警报、网络分析、营销个性化、定制奖励程序等。
在物联网领域,我们的重工业客户努力实现零计划外停机,我们建立了针对高风险设备的预测模型。例如,关键数据科学团队最近与一个主要的油气客户合作,实现了泥浆马达故障预测模型。将这一预测模型运作化具有重大影响——据美国油气记者称,泥浆马达故障可能占到非生产时间的35%,每次事故的成本为15万美元。关键数据科学团队还解决了许多其他的IoT问题——利用传感器数据检测和跟踪喷气发动机的退化,汽车的预测维护,汽车驾驶员识别,虚拟机容量预测,连接的汽车管道等。
无论在哪个领域,企业都能在数据科学模型的运作化过程中实现巨大的价值,包括新的数据和恰当的响应——所有这些都是实时的。
三、实时数据科学:建立和评价一个个性化的活动模型
为了使数据科学能够实时运行,我们为整个实时数据科学堆栈创建了一个示例管道——数据摄入、数据存储、模型训练和模型评分。该管道使用Pivotal Cloud Foundry (PCF)、Pivotal Big data Suite、Spring Cloud数据流、Nodejs、RabbitMQ和基于python的开源机器学习来演示实时数据科学。该管道构建了一个定制的“个人活动识别模型”,该模型使用智能手机上的流式加速度传感器数据。为了将其应用到业务场景中,这条管道将允许我们评估和评分几乎所有流数据的feed,以驱动实时操作。
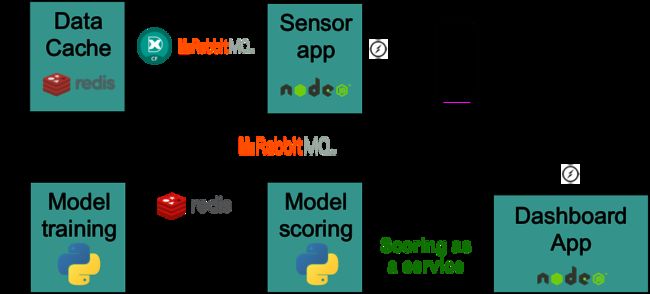
四、实时建模管道
在图1中,数据是通过移动电话和移动应用程序的加速度计创建的,它是任何IoT或类似应用程序流数据的代理。从那里,数据通过TCP通道以30Hz的频率通过WebSocket协议发送。该数据位于Node.js端点上。我们可以为这个feed选择一个更快的速率——30 Hz被确定为最优的,基于在操作之前的研究。从那里,数据移动到RabbitMQ。RabbitMQ是一个消息传递接口,它通过交换向其他服务发布数据。
为了开发我们的模型,我们首先需要一个小的数据缓存来进行训练。我们决定在Redis中缓存这些数据,但是我们可以使用Pivotal GemFire,它对于高容量和延迟敏感的系统特别有用。Redis本身并不使用来自RabbitMQ的数据,因此我们通过一个API调用部署Spring-XD流,以将来自RabbitMQ的数据传输到Redis。如图2所示,传输到Redis的数据是训练数据,它被用作特性工程和机器学习组件的输入,这些组件是用Python编写的,作为一个微服务( microservice),可以使用Ian Huston的Anaconda Python构建包部署到 Cloud Foundry。
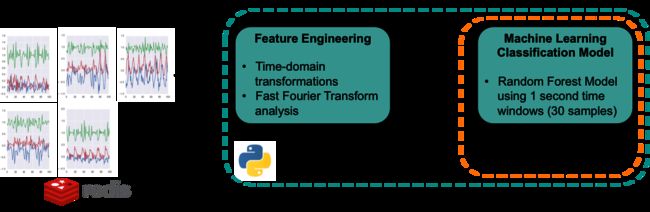
我们的训练服务从Redis开始每批训练。这些不是批处理数据上载,而是在体系结构的近实时部分中使用的特定时间序列数据组。然后,构建模型特征,并使用Python scikit- learning机器学习库对机器学习模型进行训练。
PCF训练应用流程包括特征工程阶段和模型训练阶段。使用Python包numpy和scipy执行特征工程。在特征工程中,应用一秒移动窗口,然后对每个窗口应用带通滤波器。对于每个窗口,使用时域汇总统计和频域傅里叶变换系数生成特征。最后,对数据进行随机森林模型训练,得到的模型存储在Redis中。
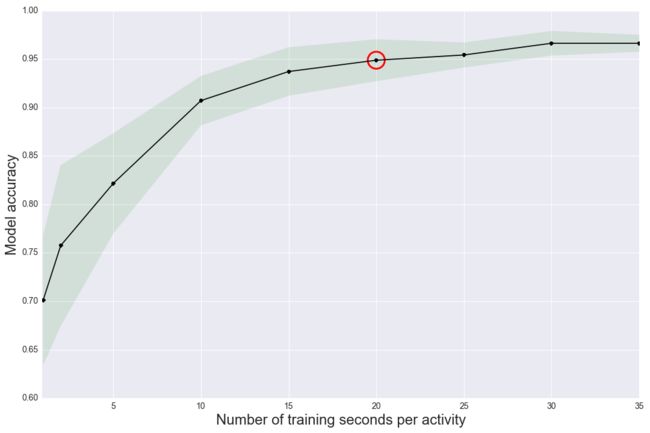
除了随机森林算法外,我们还测试了支持向量机、逻辑回归、朴素贝叶斯,但我们选择了随机森林模型进行操作,因为它在识别不同的人类活动方面表现得最好。在研发阶段拥有快速测试多个模型的能力是很重要的,因为每种方法都在准确性、计算时间和可解释性之间进行权衡。最后,我们为每个训练阶段选择了20秒,因为它在性能和实用性之间产生了最佳的权衡。
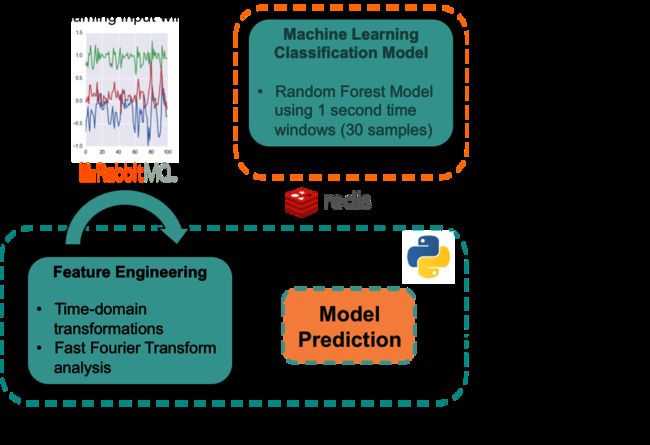
架构的实时组件如图4所示——模型得分应用程序。这个应用有两个组件。首先,特征工程组件由来自RabbitMQ的流输入窗口数据馈送,然后,这将馈送到预测组件。训练后的模型也从Redis中检索,并对每个1秒的窗口进行评分。最后,通过API调用访问计分应用程序,并应用上面描述的特性工程过程,并根据请求输出活动评分。使用这个API,任何外部应用程序都可以为特定用户请求当前的移动活动状态,并基于最高的分数获得最可能的状态。
五、Scoring-as-a-Service与云规模
通过将评分服务作为API提供,有两个突出的好处。首先,多个应用程序可以访问计分应用程序,即使是在初始系统范围之外的应用程序。其次,公开的API端点允许自治——应用程序可以通过自己的开发迭代集,而不需要部署其他应用程序。
通过在关键的云计算和弹性运行时服务中实现模型训练,我们也实现了一种高度可伸缩的方法。例如,当有更多的传感器需要训练,有更多的数据收集,或者有更多的实时查询时,我们可以扩展我们的管道,只需要生成更多的应用程序实例。