spring data jpa 使用(二)
前面说过如果自定义Repository继承Repository接口那么会被纳入spring容器管理,而Repository接口只起到了标记的作用,不提供任何方法。但spring data还为我们提供了其他的一些接口,并且都有特定的功能。
1、CrudRepository
该接口继承自Repository,提供了一些常用的增删改查方法。
源码如下:
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
S save(S var1);//保存单个实体
//保存实体集合
Iterable save(Iterable var1);
T findOne(ID var1);//根据id查找实体
boolean exists(ID var1);//根据id判断实体是否存在
Iterable findAll();//查询所有实体,不用或慎用!
Iterable findAll(Iterable var1);//根据id查询所有实体,不用或慎用!
long count();//查询实体数量
void delete(ID var1);//根据id删除实体
void delete(T var1);//删除实体
void delete(Iterable var1);//批量删除实体
void deleteAll();//删除所有实体,不用或慎用!
} 实体类User:
@Entity
@Table(name = "t_user")
public class User {
@Id
@GeneratedValue(strategy=GenerationType.IDENTITY)
private Long id;
@Column(name="user_name")
private String userName;
private String password;
private String telephone;
private String email;
@Column(name="create_time")
private Date createTime;
@Column(name="modified_time")
private Date modifiedTime = new Date();
//映射必须定义个空构造器
public User() {
}
public User(String userName, String password, String telephone, String email, Date createTime) {
this.userName = userName;
this.password = password;
this.telephone = telephone;
this.email = email;
this.createTime = createTime;
}
get、set、toString方法
}自定义接口UserRepository:
public interface UserRepository2 extends CrudRepository<User, Long>{
}测试保存10条记录:
public class TestSpringDateJpa3 {
ApplicationContext applicationContext ;
@Before
public void before(){
applicationContext =
new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
}
/*
* CrudRepository save():保存单个实体或者实体列表
*/
@Test
public void test1(){
UserRepository2 userRepository = applicationContext.getBean(UserRepository2.class);
List list = new ArrayList();
for(int i = 0;i < 10;i++){
User user = new User("mm"+i, "123456", "1356778876"+i, "mm"+i+"@qq.com", new Date());
list.add(user);
}
//保存实体集合
userRepository.save(list);
}
} 结果:控制台输出10条insert语句
查看数据库t_user表,十条记录以及保存。
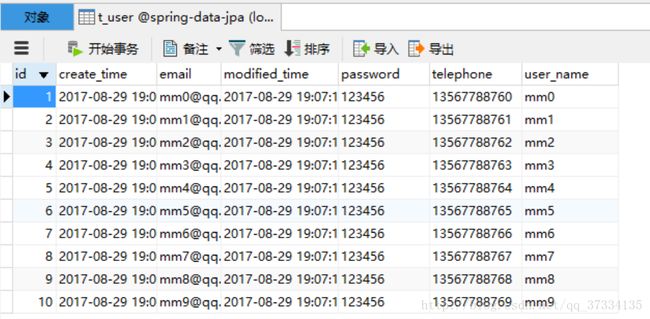
测试删除和查找后五条记录:
/*
* CrudRepository delete():删除单个实体,删除实体列表,根据id进行删除
* findOne(id):根据id查询用户信息,返回单个实体
* findAll():查询所有实体信息,返回实体集合
*/
@Test
public void test2(){
UserRepository2 userRepository = applicationContext.getBean(UserRepository2.class);
List list = new ArrayList();
for(int i = 6;i <= 10;i++){
User user = userRepository.findOne(new Long(i));
userRepository.delete(user);
}
} 结果:控制台输出5条查询语句和5条删除语句
查看数据库t_user表只剩id为1-5的用户记录。
2、PagingAndSortingRepository
该接口继承自CrudRepository接口,但是多了下面两个查询方法
Iterable findAll(Sort sort); //排序
Page findAll(Pageable pageable); //分页查询(含排序功能)
关于Pageable接口:封装了分页信息和排序信息
通常使用它实现类PageRequest
有三个重载的构造方法(介绍两个常用的):
PageRequest(int page, int size);// 分页信息
PageRequest(int page, int size, Sort sort);//分页,排序信息
Sort的构造方法运行传入多个Order对象
Order可以根据指定属性进行排序(升序或者降序)
Page封装了查询结果信息继承Slice,Slice则又继承Iterable ,也可以理解为是list的一个子集。
有很多实用的方法
int getTotalPages();
long getTotalElements();
int getNumber();
int getSize();
int getNumberOfElements();
List<T> getContent();
boolean hasNext();
...重新添加为10条数据
UserRepository2接口继承PagingAndSortingRepository而不再继承CrudRepository接口,源码中的注释如下:
A page is a sublist of a list of objects. It allows gain information about the position of it in the containing
entire list.
接下来进行分页查询测试
UserRepository2 接口:
public interface UserRepository2 extends PagingAndSortingRepository<User, Long>{
}测试:
/*
* PagingAndSortingRepository 带排序的分页查询
*/
@Test
public void test4(){
UserRepository2 userRepository = applicationContext.getBean(UserRepository2.class);
//页数从0开始,2表示第三页,所以下标是(3-1)*4=8
int page = 1;
int size = 4;
Order order1 = new Order(Direction.DESC, "id");
Sort sort = new Sort(order1); //可以传入多个order
//(当前页,每页显示条数,排序对象)
//排序相关的,Sort封装了排序的信息
//Order是针对某一属性进行升(降)序
Pageable where = new PageRequest(page, size, sort);
Page results= userRepository.findAll(where);
for (User user : results) {
System.out.println(user);
}
System.out.println("总记录数:"+results.getTotalElements());
System.out.println("当前页:"+results.getNumber());
System.out.println("总页数:"+(results.getTotalPages()));
System.out.println("当前页面的list:"+results.getContent());
System.out.println("当前页面记录数:"+results.getNumberOfElements());
} 查询结果:
User [id=6, userName=mm5, password=123456, telephone=13567788765, [email protected]]
User [id=5, userName=mm4, password=123456, telephone=13567788764, [email protected]]
User [id=4, userName=mm3, password=123456, telephone=13567788763, [email protected]]
User [id=3, userName=mm2, password=123456, telephone=13567788762, [email protected]]
总记录数:10
当前页:1
总页数:3
当前页面的list:[User [id=6, userName=mm5, password=123456, telephone=13567788765, [email protected]], User [id=5, userName=mm4, password=123456, telephone=13567788764, [email protected]], User [id=4, userName=mm3, password=123456, telephone=13567788763, [email protected]], User [id=3, userName=mm2, password=123456, telephone=13567788762, [email protected]]]
当前页面记录数:43、JpaRepository
该接口继承自PagingAndSortingRepository另外还有个QueryByExampleExecutor,里面的方法跟前面的类似,而用前面介绍的接口提供的方法基本都能实现。
4、JpaSpecificationExecutor
JpaSpecificationExecutor是独立于Repository子类之外的接口,提供了带查询条件的分页查询。通常项目中使用常常会继承CrudRepository和JpaSpecificationExecutor接口。
T findOne(Specification<T> spec);//查询单一满足条件对象
List<T> findAll(Specification<T> spec);//查询满足条件的集合
long count(Specification<T> spec);//满足条件的记录数
List<T> findAll(Specification<T> spec, Sort sort);//带排序
Page<T> findAll(Specification<T> spec, Pageable pageable);带排序和分页(重点)
Specification对象封装了查询条件,通常使用匿名内部类来创建对象,如下:
Specification spec = new Specification() {
public Predicate toPredicate(Root root, CriteriaQuery criteriaQuery, CriteriaBuilder criteriaBuilder) {
return null;
}
} - root:代表查询的实体类(重点),通过get方法获得查询属性。
- criteriaQuery:可以从中得到Root对象,即告知jpa Criteria查询要查询哪一个实体类,还可以添加查询条件。
- criteriaBuilder(重点) 用于创建Criteria相关对象的工厂,当然可以从中获取Predicate对象。
比如:查询条件为email不为空,可以写成
Path path = root.get("email");
Predicate predicate = cb.isNotNull(path);
return predicate让UserRepository同时实现这两个接口
public interface UserRepository2 extends JpaRepository<User, Long>,JpaSpecificationExecutor<User>{
}测试:
public class ExecutorMain {
/*
* 带查询条件的分页查询
*/
public static void main(String[] args) {
ApplicationContext applicationContext =
new ClassPathXmlApplicationContext("classpath:applicationContext.xml");
UserRepository2 userRepository = applicationContext.getBean(UserRepository2.class);
int page = 1;
int size = 4;
Order order1 = new Order(Direction.DESC, "id");
Sort sort = new Sort(order1);
Pageable where = new PageRequest(page, size, sort);
Long id = 3l;
String username = "m";
String telephone = "135";
Specification spec =
getConditionSprec(id,username,telephone);
Page results = userRepository.findAll(spec , where);
for (User user : results) {
System.out.println(user);
}
System.out.println("总记录数:"+results.getTotalElements());
System.out.println("当前第几页:"+results.getNumber());
System.out.println("总页数:"+(results.getTotalPages()));
System.out.println("当前页面的list:"+results.getContent());
System.out.println("当前页面记录数:"+results.getNumberOfElements());
}
private static Specification getConditionSprec(final Long id,
final String username,final String telephone) {
return new Specification() {
public Predicate toPredicate(Root root, CriteriaQuery query, CriteriaBuilder criteriaBuilder) {
List list = new ArrayList();
if(id != null ){
//查询id大于传入的id的用户信息
list.add(criteriaBuilder.greaterThan((Path)root.get("id"),id));
}
if (username != null) {
//用户名模糊查询
list.add(criteriaBuilder.like((Path)root.get("userName"),username+"%"));
}
if (telephone != null) {
//电话号码模糊查询
list.add(criteriaBuilder.like((Path)root.get("telephone"),telephone+"%"));
}
return criteriaBuilder.and(list.toArray(new Predicate[list.size()]));
}
};
}
}