hadoop部署(伪分布式,分布式)
hadoop由三种模型:
1、单机模型:测试使用
2、伪分布式模型:运行于单机
3、分布式模型:real集群模型
一、伪分布式
hadoop基于java语言;
hadoop-2.6 —– jdk 1.6+
hadoop-2.7 —– jdk1.7+
1、安装hadoop并设置其所需的环境变量
解压安装包至如下目录
[root@server2 ~]# mkdir /bdapps
[root@server2 bdapps]# tar zxf jdk-7u79-linux-x64.tar.gz
[root@server2 bdapps]# ln -sv hadoop-2.7.3/ hadoop[root@server2 bdapps]# tar zxf jdk-7u79-linux-x64.tar.gz
[root@server2 bdapps]# ln -sv jdk1.7.0_79/ jdk在/etc/profie.d/hadoop.sh里面设置环境变量,设定hadoop的运行环境:

设置java运行环境:

![]()

2、创建hadoop进程的用户及相关目录
出于安全考虑,一般用特定用户来运行hadoop的不同守护进程,分别用yarn,hdfs,mapred来运行其相应进程。

创建数据目录和日志目录:
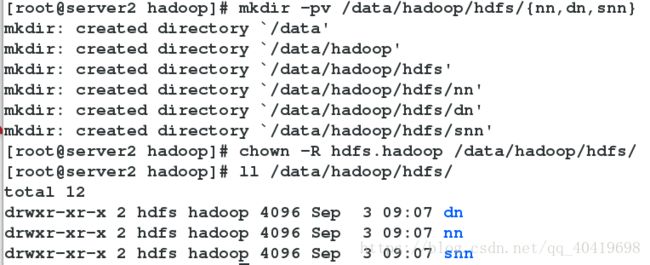
在安装目录下创建logs目录,并修改hadoop所有文件的属主属组。
![]()

3、配置hadoop
etc/hadoop/core-site.xml文件包含了NameNode主机地址,监听端口等信息,对于伪分布式模型来说,其主机地址为localhost,NameNode默认使用的端口为8020。
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:8020value>
<final>truefinal>
property>
configuration>etc/hadoop/hdfs-site.xml用于配置/HDFS的相关属性,例如数据块的副本参数,NN和DN用于存储数据的目录,=。数据块的副本对于伪分布式来说应该为1,而NN和DN用于存储数据的目录为前面专门为其创建的路径,前面的步骤也为SNN创建了相关目录,这里也一并设置其为启用状态。
```
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///data/hadoop/hdfs/nnvalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///data/hadoop/hdfs/dnvalue>
property>
<property>
<name>fs.checkpoint.data.dirname>
<value>file:///data/hadoop/hdfs/snnvalue>
property>
<property>
<name>fs.checkpoint.edits.dirname>
<value>file:///data/hadoop/hdfs/snnvalue>
property>
configuration>etc/hadoop/mapred-site.xml文件用于配置集群的MapReduce,framework,此处应该使用yarn,另外可使用的值还有local和classic,mapred-site.xml默认不存在,但有模块文件mapred-site.xml.template,将其复制成mapred-site.xml即可
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>etc/hadoop/yarn-site.xml用于配置YARN进程及YARN相关属性。首先要指明ResourceManager守护进程的主机和监听的端口,对于伪分布式模型来讲。其主机为localhost,默认端口为8032,其次需要指定ResourceManager使用的scheduler,一及NodeManager的辅助服务。
<configuration>
<property>
<name>yarn.resourcemanager.addressname>
<value>localhost:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>localhost:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>localhost:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>localhost:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>localhost:8088value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue>
property>
configuration>Hadoop的各守护进程依赖与JAVA_HOME环境,可通过前面的/etc/profile.d/java.sh来进行全局配置定义的JAVA_HOME变量即可,不过,如果向为Hadoop定义特点的JAVA环境,则需要编辑etc/hadoop/hadoop-env.sh 和 etc/hadoop/yarn-env.sh,将其JAVA_HOME配置成合适的值即可。如果需要堆内存值,也可以修改这两个文件。
slave文件:存储当前集群所有slave节点的列表,对于伪分布式来说,其值应为localhost。
4、格式化HDFS
在HDFS的NN启动之前需要先初始化其用于存储数据目录,如果hdfs-site.xml中dfs.namenode.name.dir属性指定的目录不存在,格式化命令会自动创建之;如果存在,请确保其权限设置正确,此时格式操作会清除其内部所有的数据并重新建立一个新的文件系统。
hdfs命令对于不同身份的用户来说可使用的命令不同
User Commands
dfs
fetchdt
fsck
version
Administration Commands
balancer
datanode
dfsadmin
mover
namenode
secondarynamenode需要以hdfs用户的身份执行如下命令
[root@server2 hadoop]# su - hdfs
[hdfs@server2 ~]$ hdfs namenode -format在屏幕上输出这样一句话表示格式化成功
![]()
在我们nn目录下也会出现映像文件(fsimage),用于将数据持久化

5、启动hadoop
hadoop2的启动可通过操作位于sbin路径下的专用脚本进行:
NameNode:sbin/hadoop-daemon.sh (start|stop) namenode
DataNode: sbin/hadoop-daemon.sh (start|stop) datanode
Secondary NameNode: sbin/hadoop-daemon.sh (start|stop) secondarynamenode
ResourceManager: sbin/yarn-daemon.sh (start|stop) resourcemanager
NodeManager: sbin/yarn-daemon.sh (start|stop) nodemanager启动HDFS服务
HDFS有三个守护进程,nameNode,dataNode,secondarynamenode,它们都可以通过sbin/hadoop-daemon.sh 脚本来启动或停止。以hdfs用户身份执行即可
![]()



现在我们就以上传文件了

可以看到,这里新建的目录属组为supergroup,并不是hadoop组,意味者我们之前加入hadoop组的用户对此目录没有写权限。要想其他用户对hdfs有写权限,则需要在hdfs-site.xml添加一项属性定义
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>递归显示目录


上传完文件我们就可以在dn目录下看到数据了,这是在本地文件系统路径下查看

使用dfs访问接口查看

由此可以说明任何分布式文件系统最终都应存储与本地文件系统路径上。
可以看到nn,snn下面出现了一些fsimage文件和edits文件
snn的功能是将fsimage文件从nn上拿出来放再本地,再将当前的EditLog取出来放在本地,然后将edits中的内容合并成为一个新的fsimage,再将这个新的fsimage发送给nn,将原来的fsimage覆盖掉。

启动YARN集群

6、WEB UI浏览
HDFS和YARN ResourceManager各自提供了web接口,通过这些接口可查看HDFS集群和YARN集群的状态信息,访问方式:
HDFS-NameNode :http://:50070
YARN-ResourceManager : http://:8088 注意:yran-site.xml文件如果yarn.resourcemanager.webapp.address属性的值如果定义成“localhost:8088“,则其只监听在127.0.0.1地址的8088端口上
我这里就设置的是localhost

所以可以看到8088端口监听在127.0.0.1上
![]()
将localhost修改为本地ip,重启resourcemanager就可以了
![]()


7、给hadoop提交程序并运行。
Hadoop-YARN自带了许多样程序示例,他们位于hadoop/share/hadoop/mapreduce目录里,其中 hadoop-mapreduce-examples-2.7.3.jar可以作为maoreduce程序测试。
[root@server2 mapreduce]# su - hdfs #因为运行程序时需要对dn节点进行操作,所于切换至hdfs用户
[hdfs@server2 ~]$ yarn jar /bdapps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar 我们可以通过此程序 做如下任务

例如:对/test/fstab 中的文件进行单词统计,将统计结果放在/test/fstab1下
[hdfs@server2 ~]$ yarn jar /bdapps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/fstab /test/fstab1最后由这样的字样输出就算是统计成功

可以看到统计结果

分布式:
dn磁盘无需工作于raid模式,自身就 存在repication机制。
snn与nn应该分开位于不同的节点上,否则没意义。
dn节点:datanode进程,nodemanager进程。
nn节点:namenode进程
snn节点:snn进程。
resourcemanager节点:resourcemanager进程
我们接下来配置有一个主节点和三个从节点的Hadoop-YARN集群,集群中的所有节点必须拥有唯一的主机名和IP地址,并且能够基于主机互相通信。
通过/etc/hosts文件进行解析 ,server3为主节点(NN,SNN,RM),有一个master别名名,server4(DN,NM),server5,server6为从节点
1、在每个节点的/etc/hosts文件上都进行如下的配置:
172.25.44.3 server3 master
172.25.44.4 server4
172.25.44.5 server5
172.25.44.6 server62、如果需要 master能够启动或停止整个集群,还需在master上配置用于运行各服务的用户(yarn,hdfs)能以密钥认证(passwordless)的方式通过ssh远程连接至各从节点。这里我们所有的节点上的所有进程都以hadoop身份运行。
在每一个节点上都创建hadoop用户
~]# useradd hadoop
~]# echo hadoop | passwd --stdin hadoop在master节点上:
[root@server3 ~]# su - hadoop
[hadoop@server3 ~]$ ssh-keygen -t rsa -P ''
[hadoop@server3 ~]$ for i in 4 5 6;do ssh-copy-id -i ./.ssh/id_rsa.pub hadoop@server${i};done3、设置各节点时间同步
各节点安装ntp包
~]# yum install ntp -yserver3:
server 172.25.44.250 iburst 其他节点:
vim /etc/ntp.conf
server 172.25.44.3在serevr3上启动服务:
[root@server3 ~]# /etc/init.d/ntpd start其它节点查看同步信息
~]# ntpdate server3
4 Sep 16:35:38 ntpdate[1498]: step time server 172.25.44.3 offset 0.549639 sec4、在各节点安装hadoop并配置所需的环境变量

配置hadoop运行环境
[root@server3 hadoop]# vim /etc/profile.d/hadoop.sh
export HADOOP_PREFIX=/bdapps/hadoop
export PATH=$PATH:${HADOOP_PREFIX}/bin:${HADOOP_PREFIX}/sbin
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
[root@server3 hadoop]# . /etc/profile.d/hadoop.sh配置java运行环境
[root@server3 bdapps]# vim /etc/profile.d/java.sh
export JAVA_HOME=/bdapps/jdk
export PATH=${PATH}:${JAVA_HOME}/bin:${JAVA_HOME}:/sbin
[root@server3 bdapps]# . /etc/profile.d/java.sh
创建存放数据目录,并修改其属性信息
主节点

从节点

在所有节点的安装目录下创建logs目录,修改logs目录的权限,并修改hadoop所有文件的属主属组。
[root@server3 bdapps]# cd hadoop
[root@server3 hadoop]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@server3 hadoop]# mkdir logs
[root@server3 hadoop]# chown -R hadoop.hadoop ./*
[root@server3 hadoop]# chmod g+w logs/配置hadoop
配置主节点:
配置core-site.xml ,指定nn的位置。

配置yarn-site.xml,指定ResourceManager的位置
<configuration>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:8030value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:8031value>
property>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:8033value>
property>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:8088value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.scheduler.classname>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacitySchedulervalue>
property>
configuration>配置hdfs-site.xml
<configuration>
<property>
<name>dfs.replicationname>
<value>2value> #这里我们定义两个副本
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///data/hadoop/hdfs/nnvalue>
property>
<property>
<name>fs.checkpoint.data.dirname>
<value>file:///data/hadoop/hdfs/snnvalue>
property>
<property>
<name>fs.checkpoint.edits.dirname>
<value>file:///data/hadoop/hdfs/snnvalue>
property>
configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>配置slave

配置从节点:
从节点只需配置hdfs-site.xml文件,其他的配置与主节点一致。
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///data/hadoop/hdfs/dnvalue>
property>
configuration>3、格式化HDFS
主节点
[root@server3 hadoop]# su - hadoop
[hadoop@server3 ~]$ hdfs namenode -format显示Storage directory /data/hadoop/hdfs/nn has been successfully formatted.表示成功
这时nn目录下已经有数据了

4、启动Hadoop进程
启动Hadoop-YARN集群有两种方法:一、在各节点分别启动需要启动的服务,二、在master上启动整个集群。
(1)分别启动
master节点需要启动HDFS的NameNode服务,以及YARN的ResourceManager服务,启动hdfs需要以hdfs身份进行,启动yarn需要以yarn身份进行,这里我们所有的进程都是以hadoop身份运行的。
[root@server3 ~]$ su - hadoop -c 'hadoop-daemon.sh start namenode'
[root@server3 ~]$ su - hadoop -c 'yarn-daemon.sh start resourcemanager'
各slave节点需要启动DataNode服务(hdfs身份)和NodeManager(yarn身份)服务
[root@server4 hadoop]# su - hadoop -c 'hadoop-daemon.sh start datanode'
[root@server4 hadoop]# su - hadoop -c 'yarn-daemon.sh start nodemanager'
(2)在master节点上控制整个集群
集群规模较大时,分别在各个节点上启动服务太过于繁琐和低效,为此,hadoop专门提供了start-dfs.sh和stop-dfs.sh来启动和停止整个hdfs集群,以及start-yarn.sh和stop-yarn.sh来启动和停止整个yarn集群。
在master节点上
[root@server3 ~]$ su - hadoop -c 'start-dfs.sh'
[root@server3 ~]$ su - hadoop -c 'start-yarn.sh'启动完成后就可以jps查看了


5、上传文件

在从节点上可以看到数据,因为之前定义了副本数为2,所以只有两个从节点上有数据,具体在哪个节点上由hadoop自行决定。
![]()
![]()
![]()
6、WEB UI浏览
可以看到50070和8088端口都已经监听。


查看Live Nodes,可以看待server4,server5上有数据,server6上没数据

当前Apps Subimitted为0

7、运行程序
[hadoop@server3 ~]$ yarn jar /bdapps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/fstab1 /test/haha
任务运行完成后
