大数据技术之复习Ⅰ
Linux
1、操作系统是什么
是现代计算机系统中 最基本和最重要的 系统软件
是 配置在计算机硬件上的第一层软件 ,是对硬件系统的首次扩展
2、操作系统的作用
主要作用是 管理好硬件设备,并为用户和应用程序提供一个简单的接口,以便于使用。
3、Linux的由来?
为解决连接主机的终端数量不够用的问题,而诞生的Unix操作系统,随之诞生的有B语言、C语言。
后来因为UNIX源代码私有化,为了教授学生操作系统运作细节,而诞生与UNIX兼容的操作系统MINIX
林纳斯为了访问大学主机上的新闻组和邮件,为了方便读写和下载文件,自行编写磁盘驱动程序和文件系统
林纳斯以GNU的bash当作开发环境,gcc当作编译工具,编写了Linux内核
后经 全世界网友的帮助,最终能够兼容多种硬件
4、Linux的内核版和发行版
内核版:
内核是系统的心脏,是运行程序和管理像磁盘和打印机等硬件设备的核心程序,
它提供了一个在裸设备与应用程序间的抽象层
稳定版特点:具有工业级强度,可以广泛地应用和部署
内核源码网址:http://www.kernel.org
发行版:
包括桌面环境、办公套件、媒体播放器、数据库等应用软件
常见地发行版本:
Ubuntu、Redhat、Fedora、openSUSE、Linux Mint、Debian、Manjaro、Mageia、CentOS、Arch
5、Linux和Windows的对比
费用:
Windows收费且很贵,Linux免费或少许费用
软件与支持:
大部分为收费软件,由微软官方提供支持和服务;
Linux开源自由软件,用户可以修改、定制和再发布,部分软件质量和体验欠缺
由全球所有地Linux开发者和自由软件社区提供社区提供支持
安全性:
Windows经常进行安全性系统更新
Linux相对Windows平台更加安全
使用习惯:
Windows上手容易,入门简单
Linux兼具图形界面操作和完全的命令行
新手入门较困难,熟练后效率极高
可定制性:
Windows封闭的,系统的可定制性很差
Linux开源,可定制性很强
应用场景:
桌面操作主要使用WindowsLinux支持百度、谷歌、淘宝等应用软件和服务,
是后台成千上万的Linux服务器主机。
世界上大部分软件和服务都运行Linux上的
6、Linux的文件和目录结构
/bin:存放最经常使用的命令
/sbin:存放的是系统管理员使用的系统管理程序
/home:存放普通用户的主目录
/root:是系统管理员的主目录
/lib:系统开机所需要的动态连接共享库
/etc:所有系统管理员所需要的配置文件和子目录
/usr:存放用户很多应用程序和文件,类似于Windows下的Program files目录
/boot:存放的是启动Linux时使用的一些核心文件:连接文件以及镜像文件
/proc:虚拟目录,系统内存的映射,可获取系统信息
/srv:存放一些服务启动后需要提取的数据
/sys:Linux 2.6内核新出现的一个文件系统sysfs
/tmp:存储一些临时文件
/dev:以文件形式存储所有硬件
/media:挂载例如U盘、光驱等设备到该目录下
/mnt:临时挂载别的文件系统
/opt:额外安装软件所摆放的目录
/var:存放经常修改的目录,包括日志文件
/selinux:控制程序只访问特定文件
/lost+found:一般情况下时空的,系统非法关机后,这里就存放了一些文件
7、VIM编辑器(三种模式)
一般模式
yy:复制光标所在行
y数字y:从光标所在行开始复制几行
dd:删除光标所在行
d数字d:从光标所在行开始删除几行
x:相当于del
X:相当于BackSpace
u:撤销上一步
p:粘贴
yw:复制一个词
dw:删除一个词
Shift + ^:移动到行头
Shift + $:移动到行尾
gg 或者 1+G:移动到页头
G:移动到页尾
数字 + G:移动到几行
编辑模式
i:在光标前键入
a:在光标后键入
o:在光标的下一行键入
I:在光标所在行行首键入
A:在光标所在行行尾键入
O:在光标所在行上一行键入
指令模式
:w 保存
:q 退出
:! 强制执行
/查找的词:n查找下一个,N往上查找
?查找的词:n查找上一个,N往下查找
:set nu 显示行号
:set nonu 关闭行号
ZZ(Shift+zz)没有修改直接退出,如果修改了文件保存后再退出
8、网络配置
8.1、查看IP
ifconfig
8.2、修改IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
8.3、查看主机名
hostname
8.4、修改主机
vim /etc/sysconfig/network
8.5、修改主机映射文件
vim /etc/hosts
8.6、关闭防火墙
临时关闭防火墙:service iptables stop
关闭防火墙自启:chkconfig iptables off
8.7、拓展
Service:
开启服务:service 服务名 start
关闭服务:service 服务名 stop
重启服务:service 服务名 restart
查看服务状态:service 服务名 status
Chkconfig:
查看自启配置:chkconfig
关闭服务自启:chkconfig 服务名 off
开启服务自启:chkconfig 服务名 on
查看服务开机自启状态:chkconfig 服务名 --list
9、Linux的命令
sync:将数据由内存同步到硬盘中
halt:关闭系统 =>shutdown -h now 和poweroff
reboot:重启系统,等同于shutdown -r now
man +命令:获得该命令的帮助信息
help +命令:获得Shell内置命令的帮助信息
pwd:显示当前工作目录的绝对路径
ls:列出目录的内容
ls -a 列出所有的文件(包括隐藏文件)
ls -l 长数据串列出,包括文件的属性与权限等等数据
cd 切换目录
cd 绝对路径/相对路径 切换路径
cd ~或者cd 切换到根目录
cd - 切换到上一次所在的目录
cd .. 返回当前目录的上一级目录
cd -P 跳转到实际物理路径,而非快捷方式路径
mkdir:创建一个新的目录
mkdir -p 创建多级目录
rmdir:删除一个空的目录
touch:创建空文件
cp source dest:复制source文件/目录—到—>dest目录
cp -r 目录 递归复制整个文件夹及其子文件
rm 移除文件或目录
rm -r 递归删除目录中所有内容
rm -f 强制执行删除操作
rm -v 显示指令的详细执行过程
mv 移动文件与目录或重命名
mv oldName newName 重命名
mv source dest 移动source 文件—到—>dest目录
cat 查看文件内容
cat -n 显示所有行的行号,包括空行
more 文件内容分屏查看器
space 向下翻一页
enter 向下翻一行
q 退出more
Ctrl + F 向下滚动一屏
Ctrl + B 返回上一屏
= 输出当前行的行号
:f 输出文件名和当前行的行号
less 分屏显示文件内容
space 向下翻一页
pageDown:向下翻动一页
pageUp:向上翻动一页
/字串:向下查找:n向下查找,N向上查找
?字串:向上查找:n向上查找,N向下查找
q:退出less
echo 输出内容到控制台
echo -e 支持反斜线控制的字符转换
\n 换行符
\t 制表符
head 显示文件头部内容
head 文件 查看文件头10行内容
head -n 5 文件 查看文件头5行内容
tail 输出文件尾部内容
tail 文件 查看文件后10行内容
tail -n 5 文件 查看文件后5行内容
tail -f 文件 实时追踪该文件的所有更新
> 和 >>
ll > 文件 列表内容写入文件中(覆盖)
ll >> 文件 列表内容追加到文件末尾
cat 文件1 > 文件2 将文件1的内容覆盖到文件2
echo "内容" >> 文件
ln 软链接
ln -s 源文件目录 软链接名:为指定文件创建一个软链接
rm -rf 软链接名:删除指定软链接
history 查看已经执行过历史命令
时间日期类:
date 显示当前时间
date +%Y 显示当前年份
date +%m 显示当前月份
date +%d 显示当前是哪一天
date "+%%Y-%m-%d %H:%M:%S" 显示年月日时分秒
date -d '1 days ago' 显示前一天时间
date -d '-1 days ago' 显示明天时间
date -s "yyyy-MM-dd hh:mm:ss" 设置系统当前时间
cal 查看日历
cal + 年份 查看指定年份的日历
useradd 添加新用户
useradd 用户名 添加新用户
useradd -g 组名 用户名:添加新用户到某个组
passwd 设置用户密码
passwd 用户名 为指定用户设置密码
id 查看用户是否存在
id 用户名 查看指定用户是否存在
cat /etc/passwd 查看创建了哪些用户
su 切换用户
su 只能获得用户执行权限,不能获得环境变量
su - 用户名 :切换到用户并获得改用户的环境变量及执行权限
userdel 删除用户
userdel 用户名:删除用户但保存用户主目录
userdel -r 用户名 删除用户和用户主目录
who 查看登录用户信息
whoami 显示当前用户名
who am i 显示登录用户及登录时间等信息
sudo 设置普通用户具有root权限
修改配置文件
vim /etc/sudoers
添加配置
用户名 ALL=(ALL) NOPASSWD:ALL
usermod 修改用户
usermod -g 组名 用户名 :修改指定用户的所属组
groupadd +组名:新增组
groupdel +组名:删除组
groupmod -n 新组名 旧组名 :修改指定组的组名
cat /etc/group 查看创建了哪些组
chmod [身份]+[权限] 文件
chmod u/g/o+r/w/x 文件 为用户/所属组/其他用户添加可读可写可执行的权限
chmod +x 文件:为所有用户添加可执行的权限
chmod 777 文件:为所有用户添加可读可写可执行的权限
chmod -R 777 文件 为目录下所有文件的所有者、所属组、其他用户具有可读可写可执行的权限
chown 改变所有者
chown 用户 文件:修改指定文件的所有者
chown -R 用户名:组名 文件 递归修改文件的所有者和所属组
chgrp 改变所属组
chgrp 组名 文件:修改指定文件的所属组
find 查找文件或者目录
find 范围 -name:按照指定的文件名进行查找
find 范围 -user:按照指定文件所有者查找
find 范围 -size:按照指定的文件大小查找
find 范围 -size +2048 查找大于2048字节的文件
find 范围 -size -2048 查找小于2048字节的文件
grep 过滤查找及"|"管道符
ls | grep -n 文件:查找某文件再目录列表的第几行
which 命令:查找命令在哪个目录下
gzip 文件 压缩文件,文件后缀为.gz
不能压缩目录,不保留源文件
gunzip 文件.gz 解压缩文件
不保留源文件
zip -r 递归压缩目录
可以压缩目录,保留源文件
unzip 文件.zip 解压缩文件到当前目录
unzip 文件.zip -d 目录 解压缩文件到指定的目录
保留源文件
tar -zcvf 压缩包名称 文件1 文件2:将文件1、文件2压缩到指定名称的压缩包中
-z 打包同时压缩
-c 产生.tar 打包文件
-v 显示详细信息
-f 指定压缩后的文件名
tar -zxvf 文件.tar.gz:解压到当前目录
-z 打包同时压缩【控制是否保存源文件】
-x 解包.tar文件
-v 显示详细信息
-f 指定压缩后的文件名
tar -zxvf 文件.tar.gz -C 目录:解压文件到指定目录
-z 打包同时压缩【控制是否保存源文件】
-x 解包.tar文件
-v 显示详细信息
-f 指定压缩后的文件名
df 查看磁盘空间使用情况
df -h 带计量单位
du 查看指定目录的磁盘占用情况
du -h /目录:查看指定目录的磁盘占用情况,默认为当前目录
-s 指定目录占用大小汇总
-h 带计量单位
-a 含文件
--max-depth = 1 子目录深度
-c 列出明细的同时,增加汇总值
mount/umount 挂载/卸载
mount [-t vfstype] [-o options] device dir 挂载设备
umount 设备文件名或者挂载点 卸载设备
-t vfstype:光盘或者光盘镜像:iso9660
DOS fat16 文件系统:vfat
Windows 9x fat32 文件系统:ntfs
Mount Windows 文件网络共享:smbfs
UNIX(LINUX) 文件网络共享:nfs
-o options:loop 把文件当成硬盘分区挂接上系统
ro 采用只读方式挂接设备
rw 采用读写方式挂接设备
iocharset:指定访问文件系统所用字符集
device:要挂接(mount)的设备
dir:设备在系统上的挂载点
ps 查看当前系统进程状态
ps aux | grep xxx 查看系统中所有进程
ps -ef | grep xxx 可以查看子父进程之间的关系
-a 选择所有进程
-u 显示所有用户的所有进程
-x 显示没有终端的进程
kill 终止进程
kill -9 进程号:通过进程号杀死进程
killall 进程名称:通过进程名称杀死进程,
pstree 查看进程树
-p 显示进程的PID
-u 显示进程的所属用户
top 查看系统健康状态
top -d 指令top命令每隔几秒更新,默认3秒
top -i:使top不显示任何闲置或者僵死进程
P:以CPU使用率排序,默认
M:以内存的使用率排序
N:以PID排序
q:退出top
netstat 显示网络统计信息和端口占用情况
netstat -anp | grep 进程号:查看该进程网络信息
netstat -nlp | grep 端口号:查看网络端口号占用情况
-n:拒绝显示别名,能显示数字的全部转换成数字
-l:仅列出有在listen的服务状态
-p:表示显示哪个进程在调用
crond 系统定时任务
service crond restart:重启crond服务
crontab 定时任务设置
crontab -e 编辑crontab定时任务
crontab -l 查询crontab 任务
crontab -r 删除当前用户所有的crontab任务
rpm -qa:查询所安装的所有rpm软件包
rpm -qa | grep 软件包:查询指定软件包的安装情况
rpm -e 软件包:卸载指定软件包
rpm -e --nodeps:不检查依赖卸载软件,依赖此软件包的软件将可能不能正常工作
rpm -ivh 软件包全名
-i install 安装
-v verbose 显示详细信息
-h hash 进度条
--nodeps 不检测依赖进度
yum -y [参数] 对所有提问都回答yes
install:安装rpm软件包
update:更新rpm软件包
check-update:检查是否有可用的更新rpm软件包
remove:删除指定的rpm软件包
list:显示软件包信息
clean:清理yum过期的缓存
deplist:显示yum软件包的所有依赖关系
Shell
1、什么是脚本,如何去编写一个脚本?
脚本【script】是一种批处理文件的延申,是一种纯文本保存的程序。
接收应用程序/用户命令,然后调用操作系统内核
编写脚本的步骤:
①vim 脚本名称.sh
②在脚本第一行标注使用的解析器:
#!/bin/bash 或者 #!/bin/ev bash echo "hello"③赋予脚本的执行权限
chmod +x 脚本名称.sh
④执行脚本:
sh + 脚本的相对路径/绝对路径
bash + 脚本的相对路径/绝对路径
⑤查看脚本的执行流程 bash -x 脚本.sh
⑥查看脚本的语法(常用来查看脚本语法错误):bash -n 脚本.sh
2、Shell的解释器有哪些?
查看Shell的解析器:cat /etc/shells
解析器有:
/bin/sh
/bin/bash
/sbin/nologin
/bin/dash
/bin/tcsh
/bin/csh
3、Shell的变量
系统变量:$HOME、$PWD、$SHELL、$USER
查看系统变量的值:echo $HOME/$PWD/$SHELL/$USER
显示当前Shell中所有变量的值
自定义变量
定义变量:变量=值
撤销变量:unset 变量
声明静态(只读)变量:readonly 变量,不能unset
定义全局环境变量:export 变量名
特殊变量
$n:$0表示脚本名称,$1-$9表示第一到第九个参数,大于十即:${10},${11}......
$#:获取所有输入参数个数
$*:代表命令行所有参数,把所有的参数看成一个整体
$@:代表命令行所有的参数,把每个参数区分对待
$?:表示最后一次执行的命令的返回状态,0:正确执行,非0即执行不正确
4、Shell的数组
定义数组:数组名=(值1 值2 "值3" 值4)
读取数组中指定下标索引值的元素:echo {数组名[下标索引值]}
读取数组中全部元素:echo "${数组名[*]}" 或者 echo "${数组名[@]}"
获取数组元素个数[数组的长度]:echo "${#数组名[*]}" 或者 echo "${#数组名[@]}"
遍历数组:
#!/bin/bash arr=(1 2 3 4 5 6 7) for i in ${arr[*]} do echo $i done
5、运算符
①$((运算式))或者$[运算式] + - * / % 加,减,乘,除,取余
②expr + - * / % 加 减 乘 除 取余
计算3+2
①expr 2 + 3 结果:5
②expr 2+3 结果:2+3
计算3 - 2
①expr 3 - 2 结果:1
②expr 3-2 结果3-2
计算(2+3)x4
①expr `expr 2 + 3` \* 4 结果:20
②S=$[(2+3)*4]
echo $S 结果:20
6、条件判断
两个整数比较:
= 字符串比较
-lt 小于(less than) -le 小于等于(less equal) -eq 等于(equal)
-gt 大于(greater than) -ge 大于等于(greater equal) -ne 不等于(not equal)
按照文件权限判断:
-r 是否可读(read) -w 是否可写(write) -x 是否可执行(execute)
按照文件类型进行判断
-f 文件存在并且是一个常规的文件
-e 文件存在
-d 文件存在并且是一个目录
23是否大于等于22:
[ 23 -ge 22 ]
echo $?
0 : 大于
文件是否可写:[ -w 文件 ]
目录中的文件是否存在:[-e 文件的目录]
多条件判断
[ condition ] && echo OK || echo notok
[ condition ] && [ ] || echo notok
7、流程控制语句
if
if [ 条件判断式 ]; then 程序 fi #———————————————————————————————————————————————— if [ 条件判断式 ] then 程序 elif [ 条件判断式 ] then 程序 else 程序 fi
case
case $变量名 in "值1") 程序1 ;; "值2") 程序2 ;; "值3") 程序3 ;; *) 默认执行程序 ;; esac
for
for (( 初始值;循环控制条件;变量变化 ))
do
程序
done
#————————————————————————————————————
for 变量 in 值1 值2 值3...
do
程序
donewhile
while [ 条件判断式 ]
do
程序
done8、函数
系统函数
自定义函数
[ function ] funname[()] { Action; [return int;] } #—————————————————————————————————— #计算两个输入参数的和 #!/bin/bash function sum() { s=0; s=$[ $1 + $2 ] echo "$s" }
9、Shell的文本处理工具
cut:在文件中负责剪切数据
-f:列号,提取第几列
-d:分隔符,按照指定分隔符分隔列
-c:指定具体的字符
sed:以模式空间,一次处理一行内容
-e 直接在指令模式上进行sed的动作编辑
-i 直接编辑文件
命令:a:新增,a的后面可以接字串,在下一行出现
d:删除
s:查找并替换
awk:以空格为默认分隔符将每行切片,切开的部分再进行分析处理
-F :指定输入文件拆分隔符
-v:赋值一个用户定义变量
sort:将文件排序
sort -n 按照数值的大小排序
sort -r 以相反的顺序来排序
sort -t 设置排序时所用的分隔字符
sort -k 指定需要排序的列
10、Shell的面试题
问题1:获取随机字符串(8位)
答案:
[jinghnag@hadoop101 datas]$ echo $RANDOM |md5sum |cut -c 1-8
问题1:使用Linux命令查询file1中空行所在的行号
答案:
[jinghnag@hadoop101 datas]$ awk '/^$/{print NR}' sed.txt
5
问题2:有文件chengji.txt内容如下:
张三 40
李四 50
王五 60
使用Linux命令计算第二列的和并输出
[jinghnag@hadoop101 datas]$ cat chengji.txt | awk -F " " '{sum+=$2} END{print sum}'
150
问题1:Shell脚本里如何检查一个a.txt文件是否存在?如果不存在则创建,并写入aaa?
#!/bin/bash
if [ -f a.txt ]; then
echo "文件存在!"
else
echo "文件不存在!"
echo "aaa" >> a.txt
fi
问题1:用shell写一个脚本,对文本中无序的一列数字排序
[jinghnag@hadoop101 ~]$ cat test.txt
9
8
7
6
5
4
3
2
10
1
[jinghnag@hadoop101 ~]$ sort -n test.txt|awk '{a+=$0;print $0}END{print "SUM="a}' 或者
[jinghnag@hadoop101 ~]$ sort -n test.txt | awk 'BEGAIN{a=0}{a+=$0;print $0}END{print "SUM="a}'
1
2
3
4
5
6
7
8
9
10
SUM=55
问题1:请用shell脚本写出查找当前文件夹(/home)下所有的文本文件内容中包含有字符”shen”的文件名称
[jinghnag@hadoop101 datas]$ grep -r "shen" /home | cut -d ":" -f 1
/home/jinghnag/datas/sed.txt
/home/jinghnag/datas/cut.txt11、Shell的课件总结
Hadoop
Hadoop主要是为了解决什么问题?
主要解决:海量数据的存储和海量数据的分析计算问题
hadoop发展史(简单了解)
Lucene框架是道格卡丁(Doug Cutting)开创的开源软件,用Java书写代码,实现与Google类似的全文搜索功能,它提供了全文 检索引擎的架构,包括完整的查询引擎和索引引擎。 2001年年底Lucence成为Apache基金会的一个子项目。 对于海量数据的场景,Lucene面对与Google同样的困难,存储数据困难,检索速度慢。 学习和模仿Google解决这些问题的办法:微型版【Nutch】 可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文) Google在大数据方面的三篇论文:GFS、MapReduce、BigTable GFS——————>HDFS MapReduce——>MR BigTable————>HBase 2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用了2年业余时 间实现了DFS和MapReduce机制,使Nutch性能提升。 2005年【Hadoop】作为【Lucene】的子项目【Nutch】的一部分正式引入Apache基金会 2006年3月份,MapReduce和Nutch Distributed File System(NDFS)分别被纳入到【Hadoop】项目中, Hadoop就此正式诞生,标志着大数据时代来临。 名字来源于Doug Cutting儿子的玩具大象
hadoop的发行版本【三大发行版】
Hadoop发行版本:Apache、Cloudera、Hortonworks
Apache版本最原始(最基础)的版本,对于入门学习最好。
Cloudera在大型互联网企业中用的较多。
Hortonworks文档较好。
Hadoop的优势【四高】

hadoop的组成和作用,各部分的作用(重点)
MapReduce:计算
Yarn:资源调度
HDFS:数据存储
Common:辅助工具
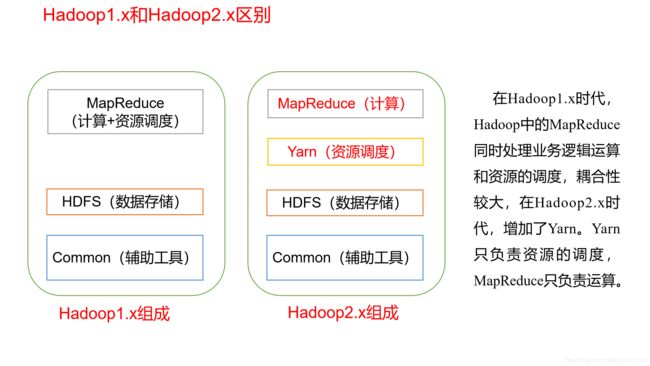
Hadoop1.x和hadoop2.x的区别?
Hadoop1.x:MapReduce(计算+资源调度)、HDFS(数据存储)、Common(辅助工具)
Hadoop2.x:MapReduce(计算)、Yarn(资源调度)、HDFS(数据存储)、Common(辅助工具)
hadoop环境搭建
1.克隆虚拟机
2. 编辑【/usr/】
修改克隆虚拟机的静态IP:【vim /etc/sysconfig/network-scripts/ifcfg-eth0】
3.修改主机名:【vim /etc/sysconfig/network】
4.关闭防火墙:【service iptables stop】 关闭防火墙 ——> 【chkconfig iptables off】 关闭防火墙开机自启
5.创建用户:【useradd 用户名】
6.修改密码:【passwd 用户名】
7.配置用户sudo(使用root)权限:【vim /etc/sudoers】
8.在/opt目录下创建存放Hadoop和JDK的压缩包的目录【software】和Hadoop、JDK解压压缩包的目录【module】
【sudo mkdir -p /opt/module /opt/software】
9.修改目录所有者:
【sudo chown -R 用户名:组名 /opt/module /opt/software】
10.使用sftp会话协议,将Hadoop和JDK的tar包存放在/opt/software
11.进入/opt/software目录,
【tar -zxvf hadoop-x.x.x.tar.gz -C /opt/module】
【tar -zxvf jdk-x.x.x.tar.gz -C /opt/module】
12.配置环境变量:【sudo vim /etc/profile】
13.使profile生效:【source /etc/profile】
14.测试JDK和Hadoop
【java -version】
【hadoop version】
Hadoop集群模式(完全分布式是重点,ssh,集群的开启和停止命令)
本地模式(单机模式)
伪分布式集群配置
伪分布式集群配置
Hadoop01 HDFSNameNode
DataNode YARN ResourceManager NodeManager完全分布式集群配置
完全分布式集群配置
Hadoop01 Hadoop02 Hadoop03 HDFSNameNode
SecondaryNameNode
DataNode DataNode DataNode YARN ResourceManager NodeManager NodeManager NodeManagerNameNode格式化:【bin/hdfs namenode -format】
群起:【bin/start-dfs.sh】【bin/start-yarn.sh】
群停:【bin/stop-dfs.sh】【bin/stop-yarn.sh】
单点启动:
namenode,datanode:【sbin/hadoop-daemon.sh start namenode/datanode】
resourcemanager、nodemanager:【sbin/yarn-daemon.sh start resourcemanager/nodemanager】
historyserver:【sbin/mr-jobhistory-daemon.sh start historyserver】
查看集群启动情况:【jps】
单点关闭:
namenode,datanode:【sbin/hadoop-daemon.sh stop namenode/datanode】
resourcemanager、nodemanager:【sbin/yarn-daemon.sh stop resourcemanager/nodemanager】
historyserver:【sbin/mr-jobhistory-daemon.sh stop historyserver】
设计一个集群,并简单说说配置和搭建流程(如果让你说如何搭建一个集群要大致能说出来)
需要修改的脚本文件及xml文件的位置在:【/opt/module/hadoop-x.x.x/etc/hadoop】目录下
配置JDK的环境变量的路径: hadoop-env.sh、yarn-env.sh、mapred-env.sh
export JAVA_HOME=/opt/module/jdk-x.x.x_xxx配置:core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml
core-site.xml
fs.defaultFS hdfs://hadoop01:9000 hadoop.tmp.dir /opt/module/hadoop-2.7.2/data/tmp fs.defaultFS hdfs://hadoop02:9000 hadoop.tmp.dir /opt/module/hadoop-2.7.2/data/tmp hdfs-site.xml
dfs.replication 1 dfs.replication 3 dfs.namenode.secondary.http-address hadoop03:50090 yarn-site.xml
yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop01 yarn.log-aggregation-enable true yarn.log-aggregation.retain-seconds 604800 yarn.nodemanager.aux-services mapreduce_shuffle yarn.resourcemanager.hostname hadoop02 mapred-site.xml
mapreduce.jobhistory.address hadoop01:10020 mapreduce.jobhistory.webapp.address hadoop01:19888 mapreduce.framework.name yarn
什么是SSH?使用的什么加密算法?
SSH 是Secure Shell 的缩写,是建立在应用层基础上的安全协议。为远程登陆会话和其他网络服务提供安全性的协议。
SSH (Secure Shell),在传输过程中,对数据进行加密
①首先要配置IP和主机的映射关系:/etc/hosts
②在随机节点上生成公钥和私钥
③通过【ssh-copy-id 主机名】将公钥分发给其他的节点。SSH使用的是非对称加密,对数据传输过程进行处理,分为私钥和公钥。
数据加密处理:通常使用公钥对数据进行加密,私钥进行解密
签名:使用私钥进行签名,公钥进行验签注意:基本不存在通过公钥退出私钥的可能
如何实现服务器之间得免密登录?
①修改主机映射文件:vim /etc/hosts
#主机IP 主机名 192.168.1.111 hadoop01 192.168.1.112 hadoop02 192.168.1.113 hadoop03②分别在集群中所有节点,通过如下命令
【ssh-keygen -t rsa -P ""】 或者 【ssh-keygen -t rsa】+三次回车
获得私钥和公钥。
通过【ssh-copy-id 主机名】+主机对应的密码 可以实现:ssh +主机名 免密登录指定主机
HDFS的组成架构、优缺点
NameNode:
①管理HDFS的名称空间
②配置副本策略
③管理数据块(Block)映射信息;
④处理客户端读写请求。
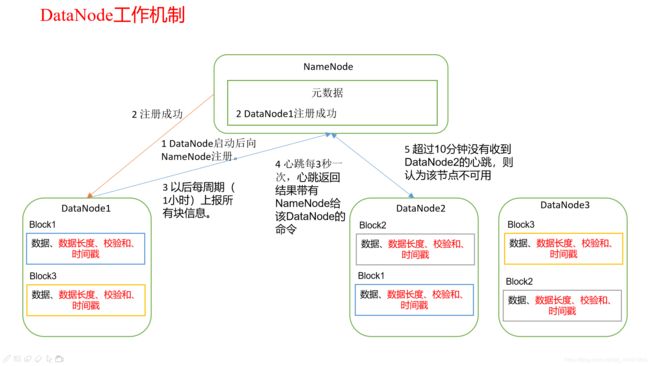
DataNode:就是一个Slave
①存储实际的数据块
②执行数据块的读/写操作。
Client:
①文件切分。文件上传HDFS时,Client将文件切分成一个一个的Block,然后进行上传
②与NameNode交互,获取文件的位置信息
③与DataNode交互,读取或者写入数据;
④Client提供一些命令来管理HDFS,比如NameNode格式化
⑤Client可以通过一些HDFS命令来访问HDFS,比如对HDFS增删查改操作。
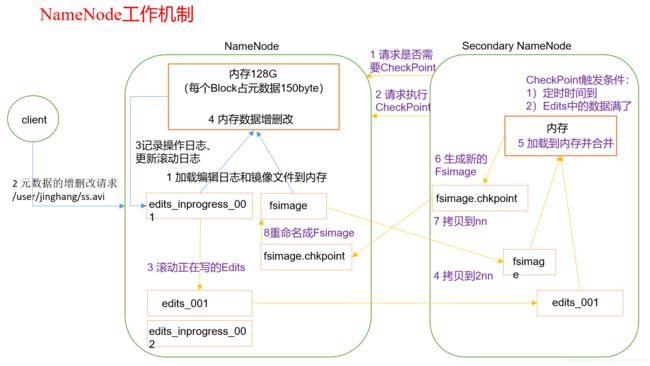
Secondary NameNode:并非NameNode的热备。当NameNode挂掉的时候,并不能马上替换NameNode并提供服务。
①辅助NameNode,分担其工作量,比如定期合并Fsimage和Edits,并推送给NameNode;
②在紧急情况下,可辅助恢复NameNode。
优点:①高容错性;②适合处理大数据;③可构建在廉价机器上,通过多副本机制,提高可靠性。
缺点:①不适合低延时数据访问;②无法高效的对大量小文件进行存储;③不支持并发写入,文件随机修改。
HDFS的块大小
128MB
如果块大小设置的过大,寻址时间虽然会减少,但是会增加数据传输时间,
如果块大小设置的过小,虽然会减少数传输的时间,但是会导致小文件的数量之多,增加寻址时间。
HDFS的命令、JAVA api操作
Hadoop fs | hdfs dfs 命令分类
本地文件 -> HDFS
-put 将本地数据上传至hdfs -copyFromLocal 将本地文件数据拷贝到hdfs -moveFromLocal 将本地文件数据移动到hdfs,成功后本地数据会删除 -appendToFile 追加一个本地文件到hdfs已经存在的文件末尾HDFS与HDFS之间
-ls 查看hdfs文件目录 -mkdir 在HDFS上创建目录 -rm 删除文件或者文件夹 -rmr 递归删除 -cp 从一个目录拷贝文件至另一目录 -mv 在HDFS目录中移动文件 -chown 修改文件所属用户权限 -chmod 修改文件所属读写权限 -du -h 文件夹暂用的空间大小 -df -h 查看系统分区情况 -cat 查看文件HFDS -> 本地
-get 从hdfs下载文件至本地 -getmerge 合并hdfs目录下的文件至本地 -copyToLocal 从hdfs拷贝文件至本地
HDFS数据的上传和下载流程(HDFS读写数据流程)
HDFS上传:
①客户端发出文件上传的请求,namenode接收请求,namenode会将是否可以上传的结果反馈给客户端。
②如果可以上传,namenode会根据所要上传的文件的大小配置副本策略,即datanode的数量。
③客户端会和datanode建立连接,datanode之间互相建立联系,并将准备好接收文件的信息反馈给客户端
④客户端的文件会在datanode上落盘。
HDFS下载:
①客户端发出文件下载的请求,namenode接收请求,namenode查找有没有要下载的文件,将结果反馈给客户端。
②如果可以上传,namenode的帮助下,客户端会与datanode建立连接,将文件下载合并。
HDFS默认副本集和存储策略是什么
如果客户端所在的主机就是集群中的节点,那么该节点就作为第一副本,
如果客户端所在的主机不是集群中的节点,那么就选择距离客户端所在的主机网络传输最近的节点作为第一副本
选择与第一副本节点同一机架上的随机节点作为第二副本。
选择其他机架上的随机节点作为第三副本。
NN和2NN之间工作机制
DN的工作机制
集群的安全模式
集群处于安全模式,不能执行重要操作(写操作),集群属于只读状态。但是严格来说,只是保证HDFS元数据信息的访问,而不保证文件的访问。集群启动完成后(大约30s),自动退出安全模式,
如果集群处于安全模式,想要完成写操作,需要离开安全模式。
相关命令:
查看安全模式状态:bin/hdfs dfsadmin -safemode get
进入安全模式状态:bin/hdfs dfsadmin -safemode enter
离开安全模式状态:bin/hdfs dfsadmin -safemode leave
等待安全模式状态:bin/hdfs dfsadmin -safemode wait
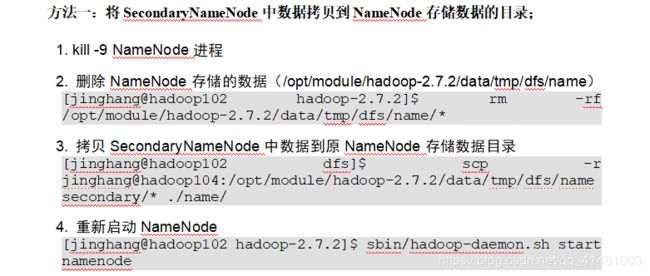
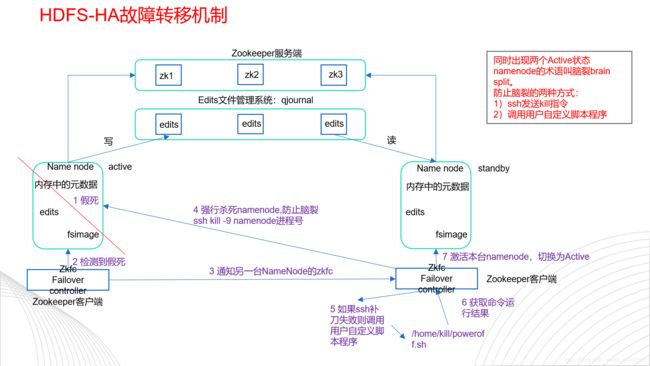
NameNode故障如何处理?


如何新节点的添加,旧节点的退役,黑名单白名单的作用分别是什么?
高可用的原理图(HDFS 的HA YARN 的HA)
MR的定义(干什么的)
2020-01-07 19:35
MapReduce是一个分布式运算程序的编程框架,是用户开发【基于Hadoop的数据分析应用】的核心框架
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上
MR的优缺点
优点:
①MapReduce易于编程
②良好的扩展性
③高容错性
④适合PB级以上海量数据的离线处理
缺点:
①不擅长实时计算
②不擅长流式计算
③不擅长DAG(有向图)计算
MR如何序列化
①自定义Bean对象实现序列化接口【Writable】
public class 类名 implements Writable{ private String 字段1; private String 字段2; private String 字段3; //无参构造 public 类名(){ } //toString()方法 @Override public String toString(){ return 字段1+"\t"+字段2+"\t"+字段3; } //getter和setter方法 //序列化方法 @Override public void write(DataOutput dataOutput) throws IOException{ dataOutput.writeUTF(字段1); dataOutput.writeUTF(字段2); dataOutput.writeUTF(字段3); } //反序列化方法 @Override public void readFields(DataInput dataInput) throws IOException{ 字段1=dataInput.readUTF(); 字段2=dataInput.readUTF(); 字段3=dataInput.readUTF(); } }②空参构造
public 类名(){ }③重写序列化方法、反序列化方法
序列化方法:
@Override public void write(DataOutput dataOutput) throws IOException{ dataOutput.writeUTF(字符串类型的字段); dataOutput.writeInt(整型类型的字段); dataOutput.writeDouble(双精度浮点型的字段); }反序列化方法:
@Override public void readFields(DataInput dataInput)throws IOException{ 字符串类型的字段=dataOutput.readUTF(); 整型类型的字段=dataOutput.readInt(); 双精度浮点型类型的字段=dataOutput.readDouble(); }④toString()方法
@Override public String toString(){ return 字段1+"\t"+字段2+"\t"+字段3; }
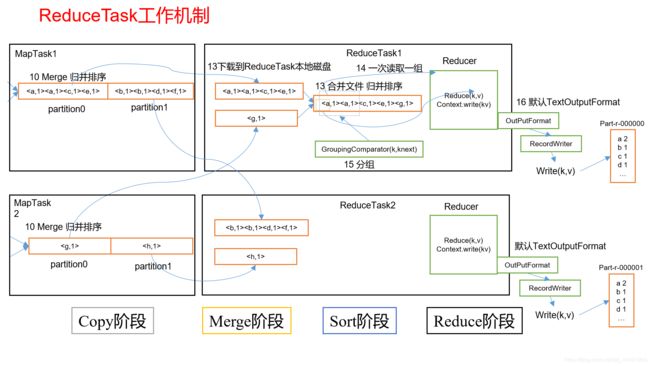
说说Mapreduce整体工作流程?
inputformat(系统的几个inputformat需要知道) - > mapper(干什么,怎么写) -> suffule(整个流程,作用) -> reduce(干什么,怎么写) -> outputformat(默认,和简单的自定义)

Shuffle过程中都做了什么?
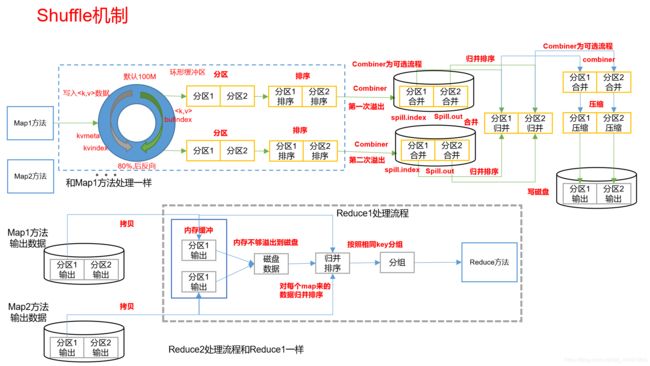
Combiner的作用是什么?
对每一个MapTask的输出进行局部汇总,以减小网络传输量

处理大量小文件的弊端?如果存在大量的小文件需要处理,有什么解决方案?
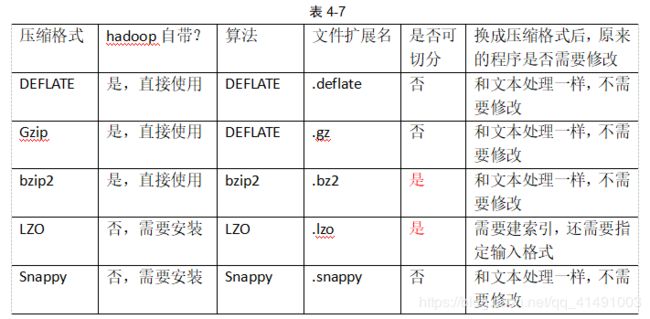
hadoop的压缩(几种压缩格式)
MR慢的原因?

MR的优化(快速过一下)
MapReduce优化主要从六个方面考虑:
①数据输入、②Map阶段、③Reduce阶段、④IO传输、⑤数据倾斜问题和⑥常用的调优参数。
①数据输入:
②Map阶段
③Reduce阶段
④IO传输
⑤数据倾斜问题
⑥常用的调优参数
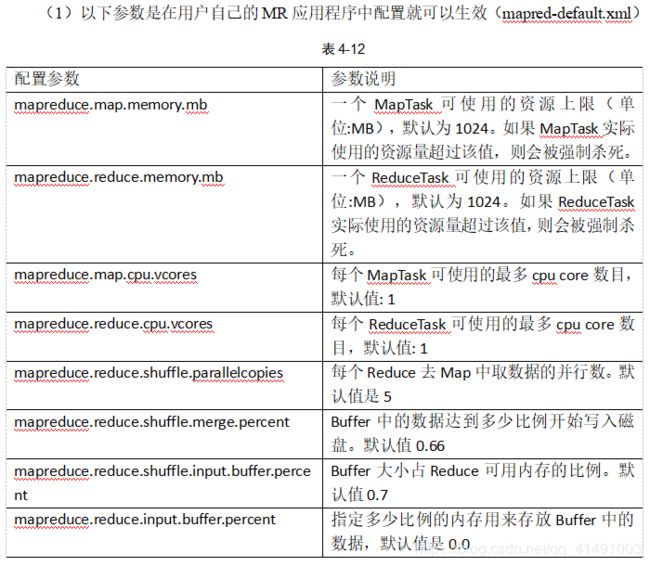
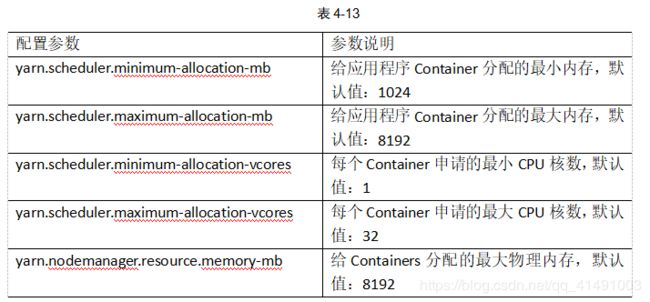
1. 资源相关参数
(2)、应该在Yarn启动之前就配置在服务器的配置文件【yarn-default.xml】中才能生效。
(3)、Shuffle性能优化的关键参数,应该在YARN启动之前就配置好【mapred-default.xml】
2、容错相关参数【MapReduce性能优化】









处理大量小文件的弊端?如果存在大量的小文件需要处理,有什么解决方案?
HDFS上每个文件都要在NameNode上建立一个索引,这个索引的大小约为150byte,小文件比较多的时候,就会产生很多的索引文件。弊端如下
①大量占用NameNode的内存空间
②索引文件过大使得索引速度变慢。
解决大量小文件的弊端:
①Hadoop Archive 高效的将小文件放入HDFS块中的文档存档工具,它能够将多个小文件打包成一个HAR文件,这样就减少了NameNode的内存使用。
②Sequence File 以二进制键值对形式将大批小文件合并成一个大文件。
③CombineFileInputFormat 将多个文件合并成一个单独的Split,并且会考虑数据的存储位置。
④开启JVM的重用,会减少45%的运行时间,一个Map在JVM上运行完毕,JVM会继续运行其他的Map。
具体设置:mapreduce.job.jvm.numtasks值在10-20之间。
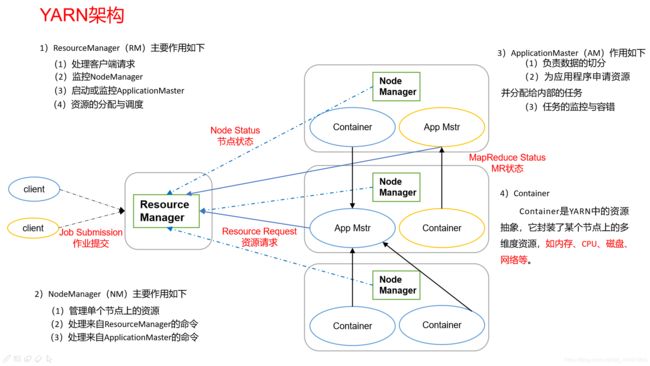
yarn资源调度器
是一个资源调度平台,负责为运算程序提供服务器运算资源,相当于一个分布式的操作系统平台。
而MapReduce等运算程序则相当于运行于操作系统之上的应用程序。
Yarn基本架构(组成、作用5.1)
Yarn工作机制(作业提交详细流程5.4)

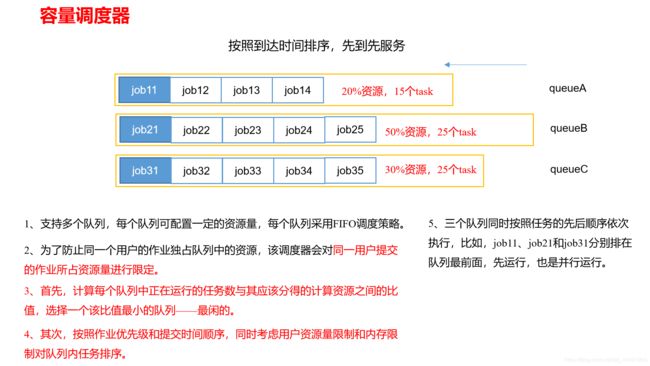
资源调度器(三种FIFO、Capacity Scheduler和Fair Scheduler)

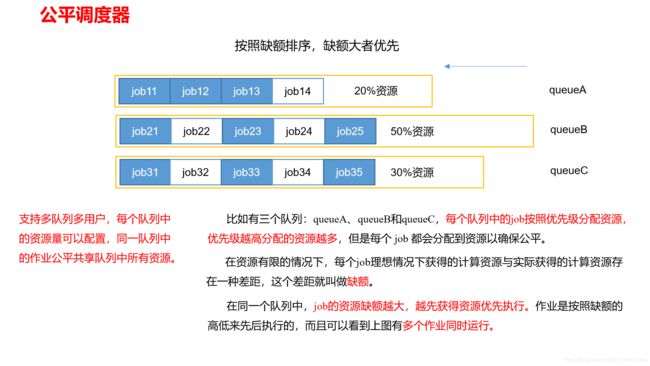
任务推测执行机制,意义?
Zookeeper
zookeeper特点?
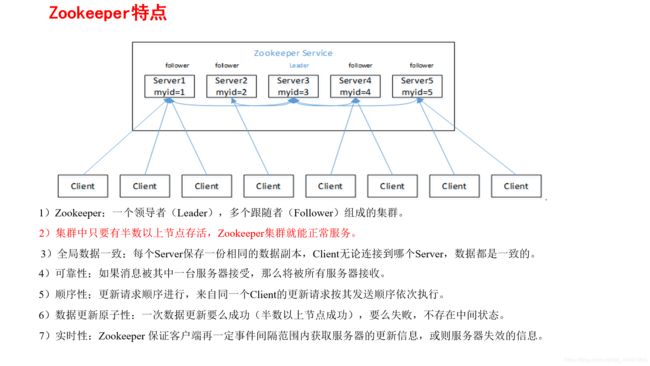
zookeeper的常用命令(增、删、改、查、观察者、其他命令)
Zookeeper客户端命令行操作 命令基本语法 功能描述 help 显示所有操作命令 ls path [watch] 使用ls命令来查看当前Zookeeper节点中所包含的内容 ls2 path [watch] 查看当前节点数据并能看到更新次数等数据 create 普通创建节点
create -s 节点路径 节点数据: 永久有序节点
create 节点路径 节点数据: 永久无序节点
create -e 节点路径 节点数据: 临时无序节点
create -e -s 节点路径 节点数据:临时有序节点
get path [watch] 获得节点的数据 set 设置节点的数据 stat 查看节点的状态 delete 删除节点【没有子节点的节点】 rmr 递归删除节点 history 查看历史命令 redo 该命令可以重新执行命令编号的历史命令,命令编号可以通过history查看
zookeeper集群的角色和作用,observer的使用场景以及如何配置?https://zhuanlan.zhihu.com/p/42067231
Leader:
Zookeeper集群工作的核心
事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性
集群内部各个服务器的调度者。
对于create、setData、delete等有写操作的请求,则需要统一转发给Leader处理,Leader需要决定编号、执行操作,这个过程称为一个事务。
Follower:
处理客户端非事务(读操作)请求,转发事务请求给Leader
参与集群Leader选举投票
Observer:(对于访问量比较大的集群,可以新增观察者角色)
观察者角色,观察Zookeeper集群的最新状态变化并将这些状态同步过来,对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器进行处理。
不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
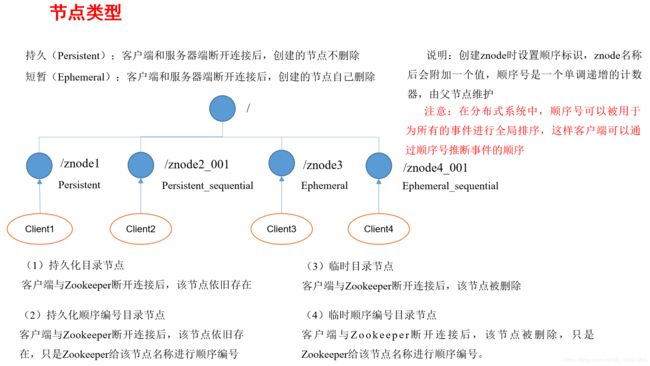
zookeeper节点类型有哪些?
请简述ZooKeeper的选举机制?
遵循半数机制:集群中半数以上机器存活,集群可用,所以Zookeeper适合安装奇数台服务器。
全新集群选举:(服务器中均没有数据)
假设有5台服务器:server1-5
启动服务器 投票次数 投票 票数 投票结果 状态 server1 1 自投一票 server1:0 投票无效 server1:LOOKING server2 2 server1,2:自投1票
server1:1
server2:1
投票无效 server1:LOOKING
server2:LOOKING
server1改投server2 server1:0
server2:2
server3 3 server1,2:投server3 server1:0
server2:0
server3:3
投票成功 server1:Follower
server2:Follower
server3:Leader
server4 4 server4:投server3 server1:0
server2:0
server3:4
server4:0
投票成功 server1:Follower
server2:Follower
server3:Leader
server4:Follower
server5 5 server5:投server3 server1:0
server2:0
server3:5
server4:0
server5:0
投票成功 server1:Follower
server2:Follower
server3:Leader
server4:Follower
server5:Follower
非全新集群选举:对于正常运行的Zookeeper集群,中途有机器(Leader)挂掉,需要重新选举时,选举 过程就需要加入数据ID、服务器ID和逻辑时钟。
①逻辑时钟小的选举结果被忽略,重新投票;(除去选举次数不完整的服务器);
②统一逻辑时钟后,数据ID大的胜出;(选出数据最新的服务器);
③数据ID相同的情况下,服务器ID大的胜出。(数据相同的情况下,选择服务器ID最大,即权重最大的服务器)
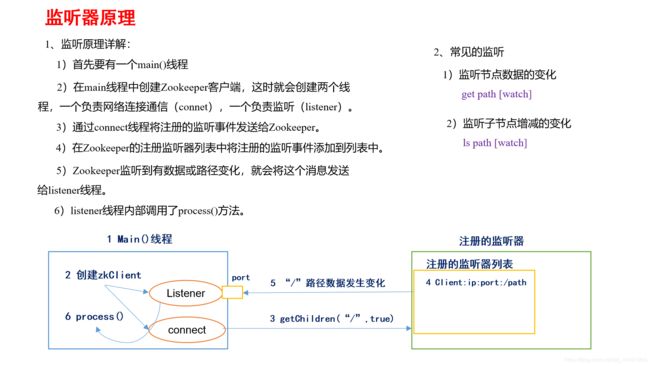
请简述zookeeper监听原理是什么?
请简述zookeeper数据的写流程?

ZooKeeper的部署方式有哪几种?集群中的角色有哪些?集群最少需要几台机器?
部署方式:单机模式、集群模式
角色:Leader和Follower
集群最少需要机器数:3