四千字从源码分析ConcurrentHashMap的底层原理(JDK1.8)
Map中用到最多的是HashMap,有关HashMap的介绍和底层源码的分析可以看我之前的文章。
java集合深入理解(五):HashMap、HashTable、TreeMap的底层源码分析和对比
HashMap有个很致命的问题就是他并非线程安全,因此在多线程环境下使用HashMap会出现问题,HashTable线程安全,但是它的效率太低了,ConcurrentHashMap就出现了,ConcurrentHashMap兼顾了线程安全和速度,下面就从底层源码出发来了解一下ConcurrentHashMap。这里用到的JDK版本是1.8。
目录
1.ConcurrentHashMap概述
2.ConcurrentHashMap的使用
3.ConcurrentHashMap的原理解析
4.ConcurrentHashMap初始化
5.put操作
6.扩容操作
7.get操作
8.remove操作
9.总结
1.ConcurrentHashMap概述
首先看一下官方对ConcurrentHashMap的介绍,这段介绍来自Java Platform SE8
A hash table supporting full concurrency of retrievals and high expected concurrency for updates. This class obeys the same functional specification as Hashtable, and includes versions of methods corresponding to each method of Hashtable. However, even though all operations are thread-safe, retrieval operations do not entail locking, and there is not any support for locking the entire table in a way that prevents all access.
英文好的同学直接看上面的英语介绍,下面是我蹩脚的翻译
一个支持检索时完全并发性和更新时高并发性的哈希表。这个类遵循与Hashtable相同的函数规范,并包含与每个Hashtable方法对应的方法版本。但是,即使所有操作都是线程安全的,检索操作也不需要加锁,并且不支持以阻止所有访问的方式锁定整个表。
简单来讲,和HashTable相比,ConcurrentHashMap效率更高,并且不会对整张表进行加锁,检索时也不需要加锁。
2.ConcurrentHashMap的使用
ConcurrentHashMap使用不难,注意ConcurrentHashMap传入的key和value不能为空,put操作为key和value均添加了@NotNull注解
![]()
ConcurrentHashMap的使用和其他的Map类集合相同,用的比较多的如put、get、remove。下面展示这些常见的用法:
ConcurrentHashMap cchashMap = new ConcurrentHashMap();
//put添加数据
cchashMap.put("1","java");
cchashMap.put("2","C");
cchashMap.put("3","C++");
System.out.println(cchashMap.get("1")); //java
System.out.println(cchashMap.size()); //3
cchashMap.remove("1");
System.out.println(cchashMap.size()); //2
//其中一种遍历方式
Iterator> iterator=cchashMap.entrySet().iterator();
while (iterator.hasNext()){
Map.Entry entry=iterator.next();
System.out.println(entry.getKey()+":"+entry.getValue());
} 3.ConcurrentHashMap的原理解析
ConcurrentHashMap做到了线程安全,其并发性通过CAS+synchronized锁来实现
ConcurrentHashMap底层和Hashmap一样通过数组+链表+红黑树的方式实现。
JDK1.8中的ConcurrentHashMap数据结构如下所示:
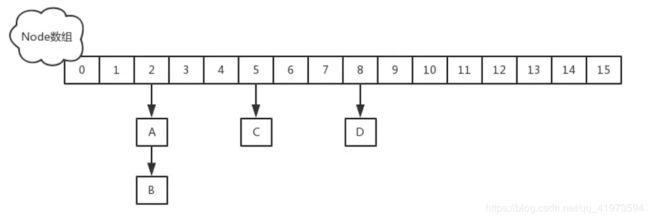
Node是ConcurrentHashMap中存放key、value以及key的hash值的数据结构:
static class Node implements Map.Entry {
final int hash;
final K key;
volatile V val;
volatile Node next;
//具体内部方法参照源码
} 当链表转化成红黑树时,用TreeNode存储对象
static final class TreeNode extends Node {
TreeNode parent; // red-black tree links
TreeNode left;
TreeNode right;
TreeNode prev; // needed to unlink next upon deletion
boolean red;
//具体方法见源码内部
} 在数组中,转变为红黑树后存放的不是TreeNode对象,而是TreeBin对象
static final class TreeBin extends Node {
TreeNode root;
volatile TreeNode first;
volatile Thread waiter;
volatile int lockState;
// values for lockState
static final int WRITER = 1; // set while holding write lock
static final int WAITER = 2; // set when waiting for write lock
static final int READER = 4; // increment value for setting read lock
//具体方法见源码内部
} 4.ConcurrentHashMap初始化
ConcurrentHashMap提供了五种构造方法:
//无参构造方法,创建一个concurrenthashmap对象
public ConcurrentHashMap() {
}
//传入初始容量的参数,如果传入的值非2的幂次方,tableSizeFor会将值修改为2的幂次方
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
//传入一个map集合,执行put操作
public ConcurrentHashMap(Map m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
//传入初试容量与负载因子后执行最后一个构造方法
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
//修改初始值和负载因子
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}ConcurrentHashMap的构造方法都没有实际对table进行初始化,对table的初始化会放在put时。
下面是初始化的代码,在初始化table中,就体现出了线程安全的一些操作,比如第六行代码使用CAS操作来控制只能有一个线程初始化table。
private final Node[] initTable() {
Node[] tab; int sc;
while ((tab = table) == null || tab.length == 0) { //如果表为空则执行初始化操作
if ((sc = sizeCtl) < 0) //如果sizeCtl小于0,说明此时有其他线程在初始化或扩展表
Thread.yield(); // 使当前线程由执行状态,变成为就绪状态,让出cpu时间
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //通过cas操作去竞争初始化表的操作,设定为-1表示要初始化了
try {
if ((tab = table) == null || tab.length == 0) {//如果指定了大小就创建指定大小的数组,否则创建默认的大小
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = tab = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc; //sizeCtl长度为数组长度的3/4
}
break;
}
}
return tab;
} 代码中sizeCtl是用来控制table初始化和扩容的,初始化时制定了大小,为数组的3/4。当其为负值时,表示表正在初始化或扩容。-1表示初始化,-(1+n)表示几个线程正在扩容
5.put操作
调用put方法后会跳转到putVal方法中执行其中的代码,简单来讲:第一次添加元素时,默认容量为16,当table为空时,直接将元素放在table上,如果不为空,则通过链表或红黑树的方式存放。链表转红黑树的条件为:链表长度大于等于8,并且table容量大于等于64。详细过程我已经在代码中注释出来。
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException(); //判断key和value是否为空
int hash = spread(key.hashCode());//计算key的hash值
int binCount = 0; //用来计算该节点的元素个数
for (Node[] tab = table;;) {
Node f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) //第一次put时进行初始化
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { //通过&运算计算这个key在table中的位置
if (casTabAt(tab, i, null,
new Node(hash, key, value, null)))
break; // 如果该位置没有元素,通过cas操作添加元素,此时没有上锁
else if ((fh = f.hash) == MOVED) //如果检测到hash值时MOVED,表示正在进行数组扩张的数据复制阶段
tab = helpTransfer(tab, f); //执行helpTransfer方法帮助复制,减少性能损失
else {
/*
*如果这个位置有元素就进行加锁,
*如果是链表,就遍历所有元素,如果存在相同key,则覆盖value,否则将数据添加在尾部
*如果是红黑树,则调用putTreeVal的方式添加元素
*最后判断同一节点链表元素个数是否达到8个,达到就转链表为红黑树或扩容
*/
V oldVal = null;
synchronized (f) {//加锁
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node e = f;; ++binCount) { //遍历链表,存在相同key则覆盖,否则添加元素到尾部
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node pred = e;
if ((e = e.next) == null) {
pred.next = new Node(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) { //如果是红黑树,则调用putTreeVal方法存入元素
Node p;
binCount = 2;
if ((p = ((TreeBin)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) //当一个节点中元素数量大于等于8的时候,执行treeifyBin
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
} 6.扩容操作
在上一段代码中我们可以看到,当一条链表中元素个数大于等于8时,会执行treeifyBin来判断是扩容还是转化为红黑树。
/*
*当table长度小于64的时候,扩张数组长度一倍,否则把链表转化为红黑树
*/
private final void treeifyBin(Node[] tab, int index) {
Node b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY) //如果table长度小于64
tryPresize(n << 1); //table长度扩大一倍
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) { //否则,将链表转为树
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode hd = null, tl = null;
for (Node e = b; e != null; e = e.next) {
TreeNode p =
new TreeNode(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin(hd)); //把头节点放入容器TreeBin中
}
}
}
}
} 再来看一下扩容的操作,扩容操作传入的参数是size,会通过size计算出一个c值,然后用c值和sizeCtl进行比较,直到sizeCtl大于等于c时,才会停止扩容。
private final void tryPresize(int size) {
//计算c的大小,如果size比最大容量一半还大,则直接等于最大容量,否则通过tableSizeFor计算出一个2的幂次方的数
//计算出的这个c会与sizeCtl进行比较,一直到sizeCtl>=c时才会停止扩容
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
//另sc等于sizeCtl
while ((sc = sizeCtl) >= 0) {
Node[] tab = table; int n;
//如果table为空则初始化,这里和初始化时代码一样
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node[] nt = (Node[])new Node[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
//如果c比sizeCtl要小或者table的长度大于最大长度才停止扩容
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
int rs = resizeStamp(n);
//如果正在扩容(sc<0),帮助扩容
if (sc < 0) {
Node[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//否则直接进行扩容
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
} 到这里put操作就算是结束了。
7.get操作
看完put后后面的操作就简单了,get操作不设计线程安全,因此不用加锁。首先通过hash值判断该元素放在table的哪个位置,通过遍历的方式找到指定key的值,不存在返回null
public V get(Object key) {
Node[] tab; Node e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //计算key的hash值
//如果table不为空并且table的容量大于0并且key在table的位置不等于空
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
//如果table上的key就是要找的key,返回value
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
} 8.remove操作
调用remove方法后会自动跳转到replaceNode方法中,删除节点的主要过程为首先判断table是否为空,再判断是否正在扩容,通过遍历的方式找到节点后删除。通过对单个链表或红黑树加锁的方式使得可以多线程删除元素。
public V remove(Object key) {
return replaceNode(key, null, null);
}
final V replaceNode(Object key, V value, Object cv) {
int hash = spread(key.hashCode());
for (Node[] tab = table;;) {
Node f; int n, i, fh;
//如果table为空或者发现不存在该key,直接退出循环
if (tab == null || (n = tab.length) == 0 ||
(f = tabAt(tab, i = (n - 1) & hash)) == null)
break;
//如果等于MOVED,表示其他线程正在扩容,帮助扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
boolean validated = false;
synchronized (f) {
//二次校验,如果tabAt(tab, i)不等于f,说明已经被修改了
if (tabAt(tab, i) == f) {
if (fh >= 0) {
validated = true;
for (Node e = f, pred = null;;) {
K ek;
//找到对应的节点
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
V ev = e.val;
//删除节点或者更新节点的条件
if (cv == null || cv == ev ||
(ev != null && cv.equals(ev))) {
oldVal = ev;
//更新节点
if (value != null)
e.val = value;
//删除非头节点
else if (pred != null)
pred.next = e.next;
//删除头节点
else
setTabAt(tab, i, e.next);
}
break;
}
//继续遍历
pred = e;
if ((e = e.next) == null)
break;
}
}
//如果是红黑树则按照树的方式删除或更新节点
else if (f instanceof TreeBin) {
validated = true;
TreeBin t = (TreeBin)f;
TreeNode r, p;
if ((r = t.root) != null &&
(p = r.findTreeNode(hash, key, null)) != null) {
V pv = p.val;
if (cv == null || cv == pv ||
(pv != null && cv.equals(pv))) {
oldVal = pv;
if (value != null)
p.val = value;
else if (t.removeTreeNode(p))
setTabAt(tab, i, untreeify(t.first));
}
}
}
}
}
if (validated) {
if (oldVal != null) {
//如果删除了节点,更新长度
if (value == null)
addCount(-1L, -1);
return oldVal;
}
break;
}
}
}
return null;
} 9.总结
ConcurrentHashmap通过cas和synchronized锁的方式实现了线程安全,通过一个Node
因为可以让多个线程同时处理,在ConcurrentHashmap中增加了一个sizeCtl变量,这个变量用来控制table的初始化和扩容,
sizeCtl :默认为0,用来控制table的初始化和扩容操作
-1 代表table正在初始化
-N 取-N对应的二进制的低16位数值为M,此时有M-1个线程进行扩容
其余情况:
1、如果table未初始化,表示table需要初始化的大小。
2、如果table初始化完成,表示table的容量,默认是table大小的0.75倍
第一次添加元素时,默认容量为16,当table为空时,直接将元素放在table上,如果不为空,则通过链表或红黑树的方式存放。链表转红黑树的条件为:链表长度大于等于8,并且table容量大于等于64。
以上是我对ConcurrentHashmap底层源码的总结,如果有任何问题可以在评论区反馈或者私信我,我都会回。欢迎关注我的同名微信公众号,目前处于起步阶段,大家一起学习一起进步!