Mysql的B+树索引
目录
MySQL索引机制
索引的本质
索引的目标
索引的工作流程
MySQL支持的索引的数据结构
hash索引
B+树索引
为什么MySQL选择B+树作为索引的数据结构
平衡二叉搜索树
使用平衡二叉搜索树的弊端
B-树(多路平衡树)
发散思考
为什么不是什么字段都适合添加索引
为什么MySQL推荐我们使用自增id作为主键索引
B+树(B-树加强版)
I/O能力强于B-树
排序能力强于B-树
基于索引的扫表更强
I/O能力更加稳定
MySQL存储引擎中索引的实际存在方式
MyISAM存储引擎
InnoDB存储引擎
回表查询
为什么辅助索引的最后一层对应的不是主键索引的数据域
自适应Hash索引
MySQL索引机制
第一个知识点:
索引的本质
数据结构(离散存储/硬盘级)
索引的目标
加速数据检索
索引的工作流程
1.由客户端传入要查询的值的条件中的关键字。
2.然后再索引中查找与关键字相等的节点。
3.通过节点找到该值所在的地址,获得要查询的值。
4.返回值给客户端。
MySQL支持的索引的数据结构
hash索引
hash索引的底层的实现使用的是数组,搜索值使用的是下标查询,时间复杂度为O(1)。
hash索引进行等值查询有很强的效率,但是当执行范围查询时效率不佳。
由下文的表可以看到MyISAM和InnoDB都不支持用户操作级别的HASH索引。
B+树索引
本文重点讨论的索引类型
为什么MySQL选择B+树作为索引的数据结构
讨论为什么使用B+树,可以先从另一种树形结构平衡二叉搜索树看起
平衡二叉搜索树
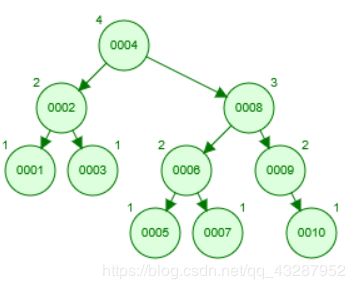
图中是一颗平衡二叉搜索树,其与普通的二叉树相比,相同数据下深度相对较低,但当数据量过大时其的深度仍会很大。
使用平衡二叉搜索树的弊端
二叉树过高,导致I/O次数过多
当数据量变大时,会导致二叉树过高,索引在搜索时每次都会与一个节点比较,然后输出一个结果用判断下一次比较左子树还是右子树,当树过高时,意味着过多的I/O次数。
空间利用率低
上文提到索引的本质时硬盘级的数据结构,硬盘最小的扇区为4k(对硬件不是很了解,有误请指正),所以一次I/O操作所分配的空间为4k或其倍数。而如果使用平衡二叉搜索树,每一个节点的的构造如下图所示:
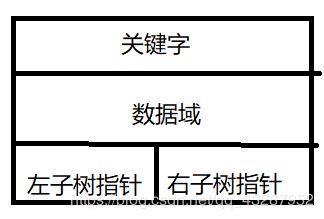
由图中可以看出一个这样的节点其所占的空间做多几百B的大小,但一次I/O分配了至少4KB的空间,所以空间利用率低。
那么平衡二叉搜索树存在这样的弊端,那B-树又是如何解决的呢?
B-树(多路平衡树)
我们先来看一下同样用B-树存储相同数据,其构造是怎么样的?

上图是一个子叉路最大为5的B-树(关于B-树的构造规则这里不过多赘述)
其子树指针所指向的数据范围为(左关键字,右关键字)——开区间
B-树满足一个公式:关键字数=子叉路数-1
由这张图我们可以发现仅仅只是将最大子叉路数设置为5时其一个节点就可以存储4个关键字。在实际的情况中,假设一次I/O操作所分配的空间为16K,一个平衡二叉搜索数的节点的大小为8B,则一个B-数节点可以放2000个关键字,那就会由2001个子叉路,每n层的存储量级为会成指数级上涨。这也就意味着这款树是一个矮胖的树,其深度会很低,实际应用中一般树的高度也就只有3-4层。当一个节点中所存的关键字多时,相同数据量下一棵树的高度也会随之边低,而一次I/O的空间使用率也会相应的提高。
发散思考
为什么不是什么字段都适合添加索引
之前和学长交流时,当时刚刚接触索引,认为为了让查询变快,只要添加索引就可以了,但是学长说索引会导致数据的增删改的速度变慢,所以索引的添加需要权衡。当时并不知道为什么索引会导致数据的增删改变慢,这次通过对索引底层机制的学习,有了更深的理解。
我们不难发现B-树是一棵绝对平衡树,它的所有叶子节点都在同一个水平线上,而为了让这棵树保证绝对平衡,需要利用子节点和根节点的变化来调节关键字的个树,这些变化需要消耗时间和性能,所以不适合为经常变动的字段添加索引。
为什么MySQL推荐我们使用自增id作为主键索引
当为一字段添加索引后,每次新增数据势必会导致其索引的结构变化,但是对于自增id来说一方面id的数据类型所占空间小,内容简单,可以有效控制树的高度,另一方面每次插入新数据时,id肯定时比树中所有的id的值大的,这样只需要变动它的最右子树的部分。基于这两点,可以将影响控制到最小。
B+树(B-树加强版)
B+树存储数据时其指针的数据范围为——[左关键字,右关键字)——左闭区间
同样是插入10个数据,下图是B+树(最大子叉路数为5)的构造

不难看出在B+树满足这个公式:关键字数=子叉路数
I/O能力强于B-树
在相同关键字数时子叉路数上B+数比B-树大1,随着高度增加,这个差距会逐渐拉大,但B+树的优势并不仅限于此。
对于上图的B+树来说,我们不难看出最后的那一层中存放了所有的数据,利用B+树这一特性,在实际的索引中节点只存放了关键字和指针域,其间并没有数据域。这样做就意味着磁盘分配相同的空间下,B+树中的结点可以存放比B-树更多的关键字,这样就使I/O次数变得更少了。
排序能力强于B-树
还是通过上图不难看出在最后一层的节点中所存放的数据域是依照关键字有序排列的,这样在获取数据时其顺序性也更强。
基于索引的扫表更强
对B+树进行扫表时只需要找到它的最后一层,然后线性的扫描这一层的数据就可以获取表中所有的值,而B-树无法避免节点的判断与回溯。
I/O能力更加稳定
对于B+树来说无论查询什么数据,每次都是从根节点开始扫描,经过相同的I/O次数后到达最后一层,获取值,所以不同数据的I/O次数相近。而B-树中不同数据所处的树的层数不同,I/O的次数差异较大。
MySQL存储引擎中索引的实际存在方式
MySQL存储引擎为插拔式(以插件形式)存在。
MyISAM存储引擎
在MyISAM中索引无主次之分,每个B+树索引都是独立的数据结构。所以在该引擎中不存在聚簇索引。
在该引擎中.myi中存储索引的结构,.myd存储地址与值的对照表(数据内容)。
InnoDB存储引擎
在InnoDB中所有的索引均存于ibd文件中。
主键索引是唯一的聚集索引——
数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同
在InnoDB中存储索引分为主键索引和辅助索引
存储索引以自增id为关键字,其最底层存放了所有的数据,而辅助索引中关键字为创建时指定的字段的每一个值,其底层存的是主表对应的id值。
回表查询
当查询调用辅助索引时,查询到对应的主键索引的id值,之后会再从主键索引的根节点开始进行查询,找出所存的值,这一过程被称为回表查询。
为什么辅助索引的最后一层对应的不是主键索引的数据域
因为如果对应的是主键索引的数据域,一旦主键索引的数据域中发生一点改动,所有的辅助索引都要跟着改动,造成更高的性能损耗。
自适应Hash索引
上文提到InnoDB不支持Hash索引时特别提了时用户操作级别的,因为InnoDB会自动使用自适应的Hash索引。
触发条件
当多次搜索路径出现高相似性时会使用自适应Hash索引将 这一部分的值的各个关键字各存入一个Hash表中。
这些hash表是存在数据库的缓冲区之中的,是临时性的。
目的:节省IO寻址路径
总结:这些是目前我所理解的关于索引机制的内容,如有错误,希望指正,虚心求教。