Hive鲜为人知的宝石-Hooks

本来想祝大家节日快乐,哎,无奈浪尖还在写文章。谴责一下,那些今天不学习的人。对于今天入星球的人,今天调低了一点价格。减少了20大洋。机不可失失不再来。点击阅读原文或者扫底部二维码。

 hive概述
hive概述
Hive为Hadoop提供了一个SQL接口。 Hive可以被认为是一种编译器,它将SQL(严格来说,Hive查询语言 - HQL,SQL的一种变体)转换为一组Mapreduce / Tez / Spark作业。 因此,Hive非常有助于非程序员使用Hadoop基础架构。 原来,Hive只有一个引擎,即MapReduce。 但是在最新版本中,Hive还支持Spark和Tez作为执行引擎。 这使得Hive成为探索性数据分析的绝佳工具。
基于mapreduce的hive,整个架构图如下:
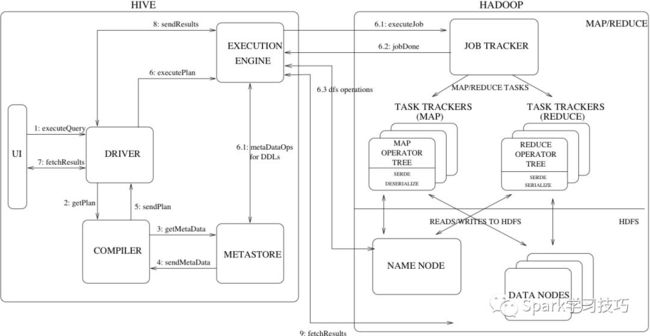
driver - 接收查询的组件。 该组件实现了会话句柄的概念,并提供了在JDBC / ODBC接口上的执行和获取数据的api模型。
编译器 - 解析查询的组件,对不同的查询块和查询表达式进行语义分析,最终通过从metastore获取表和分区的信息生成执行计划。
Metastore - 存储仓库中各种表和分区的所有结构信息的组件,包括列和列类型信息,读取和写入数据所需的序列化程序和反序列化程序以及存储数据的相应HDFS文件。
执行引擎 - 执行编译器创建的执行计划的组件。 该计划是一个stages的DAG。 执行引擎管理计划的这些不同阶段之间的依赖关系,并在适当的系统组件上执行这些阶段。
什么是hook
通常,Hook是一种在处理过程中拦截事件,消息或函数调用的机制。 Hive hooks是绑定到了Hive内部的工作机制,无需重新编译Hive。从这个意义上讲,提供了使用hive扩展和集成外部功能的能力。换句话说,Hive hadoop可用于在查询处理的各个步骤中运行/注入一些代码。根据钩子的类型,它可以在查询处理期间的不同点调用:
Pre-execution hooks-在执行引擎执行查询之前,将调用Pre-execution hooks。请注意,这个目的是此时已经为Hive准备了一个优化的查询计划。
Post-execution hooks -在查询执行完成之后以及将结果返回给用户之前,将调用Post-execution hooks 。
Failure-execution hooks -当查询执行失败时,将调用Failure-execution hooks 。
Pre-driver-run 和post-driver-run hooks-在driver执行查询之前和之后调用Pre-driver-run 和post-driver-run hooks。
Pre-semantic-analyzer 和 Post-semantic-analyzer hooks-在Hive在查询字符串上运行语义分析器之前和之后调用Pre-semantic-analyzer 和Post-semantic-analyzer hooks。
hive查询的生命周期
hive查询在hive中的执行过程。
Driver接受命令。
org.apache.hadoop.hive.ql.HiveDriverRunHook.preDriverRun() 读取hive.exec.pre.hooks决定要运行的pre-hooks 。
org.apache.hadoop.hive.ql.Driver.compile()通过创建代表该查询的抽象语法树(AST)来开始处理查询。
org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook实现了HiveSemanticAnalyzerHook,调用
preAnalyze()方法。对抽象语法树(AST)执行语义分析。
org.apache.hadoop.hive.ql.parse.AbstractSemanticAnalyzerHook.postAnalyze()会被调用,它执行所有配置的语义分析hooks。
创建并验证物理查询计划。
Driver.execute()已经准备好开始运行job调用org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext.run()方法去执行所有的 pre-execution hooks。org.apache.hadoop.hive.ql.hooks.ExecDriver.execute()执行该query的所有jobs
对于每个job都会执行org.apache.hadoop.hive.ql.stats.ClientStatsPublisher.run(),来为每个job发布统计信息。该间隔是由hive.exec.counters.pull.interval配置控制,默认是1000ms。hive.client.stats.publishers配置决定着运行的publishers。也可以通过设置hive.client.stats.counters来决定发布哪些counters。
完成所有task。
(可选)如果任务失败,请调用hive.exec.failure.hooks配置的hooks。
通过堆所有 hive.exec.post.hooks指定的hooks执行ExecuteWithHookContext.run() 来运行post execution hooks。
org.apache.hadoop.hive.ql.HiveDriverRunHook.postDriverRun()。请注意,这是在查询完成运行之后以及将结果返回给客户端之前运行的。
返回结果。
Hive Hook API
Hive支持许多不同类型的Hook。 Hook接口是Hive中所有Hook的父接口。它是一个空接口,并通过以下特定hook的接口进行了扩展:
1. PreExecute和PostExecute将Hook接口扩展到Pre和Post执行hook。
2. ExecuteWithHookContext扩展Hook接口以将HookContext传递给hook。HookContext包含了hook可以使用的所有信息。 HookContext被传递给名称中包含“WithContext”的所有钩子。
3. HiveDriverRunHook扩展了Hook接口,在driver阶段运行,允许在Hive中自定义逻辑处理命令。
4. HiveSemanticAnalyzerHook扩展了Hook接口,允许插入自定义逻辑以进行查询的语义分析。它具有preAnalyze()和postAnalyze()方法,这些方法在Hive执行自己的语义分析之前和之后执行。
5. HiveSessionHook扩展了Hook接口以提供会话级hook。在启动新会话时调用hook。用hive.server2.session.hook配置它。
6. Hive 1.1添加了Query Redactor Hooks。它是一个抽象类,它实现了Hook接口,可以在将查询放入job.xml之前删除有关查询的敏感信息。可以通过设置hive.exec.query.redactor.hooks属性来配置此hook。
栗子搞起
hive源码中实现了一些hook,具体有以下几个例子:
1.driverTestHook是一个非常简单的HiveDriverRunHook,它打印你用于输出的命令。
2. PreExecutePrinter和PostExecutePrinter是pre 和 post hook的示例,它将参数打印到输出。
3. ATSHook是一个ExecuteWithHookContext,它将查询和计划信息推送到YARN timeline server。
4. EnforceReadOnlyTables是一个ExecuteWithHookContext,用于阻止修改只读表。
5. LineageLogger是一个ExecuteWithHookContext,它将查询的血统信息记录到日志文件中。 LineageInfo包含有关query血统的所有信息。
6. PostExecOrcFileDump是一个post=Execution hook,用于打印ORC文件信息。
7. PostExecTezSummaryPrinter是一个post-execution hook,可以打印Tez计数器的摘要。
8. UpdateInputAccessTimeHook是一个pre-execution hook,可在运行查询之前更新所有输入表的访问时间。
栗子
下面写一个简单的 pre-execution hook,会在执行的时候输出Hello from the hook !!。
1. 创建一个工程。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>hive-hook-examplegroupId>
<artifactId>Hive-hook-exampleartifactId>
<version>1.0version>
project>
2. 添加hive-exec依赖。
hook的主要依赖就是hive-exec包。
<dependencies>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>1.1.0version>
dependency>
dependencies>
3.创建一个实现类。
该类要继承自
org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext
该接口只有一个方法。
public void run(HookContext) throws Exception;
我们的实现仅仅是输出一个字符串。
System.out.println("Hello from the hook !!");
完整的例子如下:
import org.apache.hadoop.hive.ql.hooks.ExecuteWithHookContext;
import org.apache.hadoop.hive.ql.hooks.HookContext;
public class HiveExampleHook implements ExecuteWithHookContext {
public void run(HookContext hookContext) throws Exception {
System.out.println("Hello from the hook !!");
}
}
4. 打包使用
打包
mvn package
使用
Start the Hive terminal and issue the following commands. Note that you have to
add jar target/Hive-hook-example-1.0.jar;
set hive.exec.pre.hooks=HiveExampleHook;
更多hivehook例子,请参考hive源码,路径:
https://github.com/apache/hive/tree/master/ql/src/java/org/apache/hadoop/hive/ql/hooks
后面,浪尖给出hive的hook在安全控制和metastore监控的hook案例。
[完]
推荐阅读:
重要 | mr使用hcatalog读写hive表
必读|spark的重分区及排序