python爬取上海期货交易所数据
一:爬虫的常规方法
爬虫的常用套路是table-tr(行)-th/td(元素)

'''
Created on Feb 28, 2017
@author: hcq908
'''
import csv
import os
# import re
from urllib.request import urlopen
from bs4 import BeautifulSoup
if __name__ == '__main__':
iCntTable = 0;
html = urlopen("https://en.wikipedia.org/wiki/Comparison_of_text_editors")
#html = urlopen("http://www.shfe.com.cn/bourseService/businessdata/summaryinquiry/index.html?paramid=trading_daily")
bsObj = BeautifulSoup(html, "html.parser")
oTables = bsObj.find_all("table")#选定第一个表格
for table in oTables:
iCntTable =iCntTable + 1;
print('处理第%d个表格 \n'%iCntTable)
#获取表格名称
#sTitleTag = table.find('caption');#标题只有一个,注意有的没有标题等
#print(sTitleTag)
# sMatchText = re.compile(r'<[^>]+>', re.S)
# sTextRemain = sMatchText.sub('', sTitleTag)
sTitleName= chr(iCntTable)+'.csv';
#路劲不存在是需要新建
sDir = './files';
if not os.path.exists(sDir):
os.mkdir(sDir)
sCSV_Path = os.path.join(sDir,sTitleName);
rows = table.find_all("tr")#tr为每一行的标签
print("rows:",rows)
with open(sCSV_Path, 'wt', newline='', encoding='utf-8') as csvFile: #创建可写文件
writer = csv.writer(csvFile)
for row in rows:#先按行处理
csvRow = []#创建列表存储每行数据
for cell in row.find_all(['td', 'th']):#再按列处理,搜索一行中每格的内容,td或th都可以
csvRow.append(cell.get_text())#将每格中的数据追加到列表
writer.writerow(csvRow)#写入一行
二:从js/dat等文件中把数据读出来
对于一些表格,数据本身并不是写在表格中的,表格只是用来做显示的,这个时候直接爬取url是拿不到数据的。
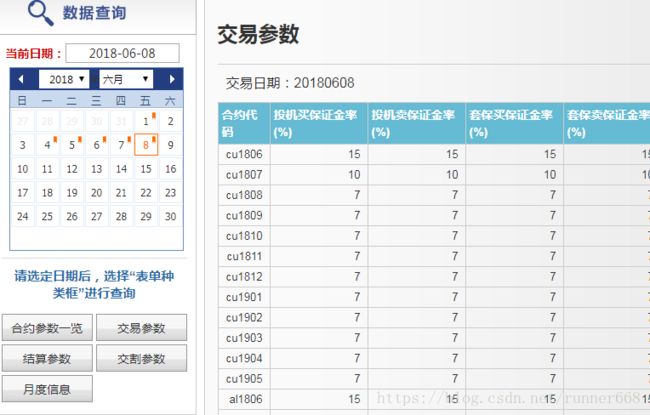
这种带查询的表格,数据其实是保存在别的url下,至于为啥我也不知道,我对前端了解的有限。
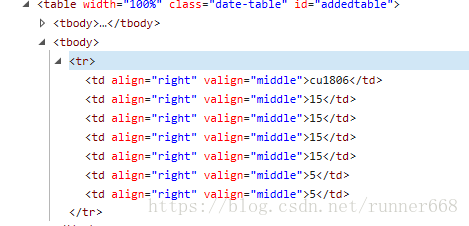
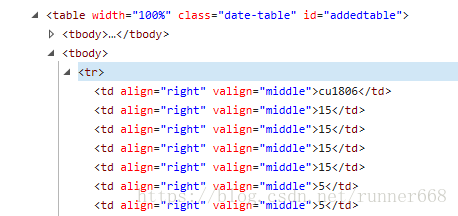
然后在F12下看一下表格的元素形式,发现table下都是tbody,并不是常见的形式。
2:尝试打印获得的内容
for page in range(1,2):
url='http://www.shfe.com.cn/bourseService/businessdata/summaryinquiry/index.html?paramid=trading_daily'
request=urllib.request.Request(url=url,headers={"User-Agent":random.choice(user_agent)})#随机从user_agent列表中抽取一个元素
try:
response=urllib.request.urlopen(request)
except urllib.error.HTTPError as e: #异常检测
print('page=',page,'',e.code)
except urllib.error.URLError as e:
print('page=',page,'',e.reason)
content=response.read().decode('utf8') #读取网页内容
print('get page',page) #打印成功获取的页码
print("content_size:",len( content))
print(content)
pattern=re.compile('')
#pattern=re.compile('')
body=re.findall(pattern,str(content))
print("body_size:",len(body))
pattern=re.compile('>(.*?)<')
stock_page=re.findall(pattern,body[0]) #正则匹配
stock_total.extend(stock_page)
time.sleep(random.randrange(1,4)) #每抓一页随机休眠几秒,数值可根据实际情况改动 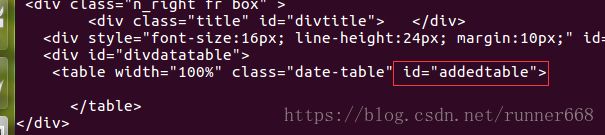
发现table下没内容,难怪抓不下来呢。
3:查找源(数据)
刷新网页
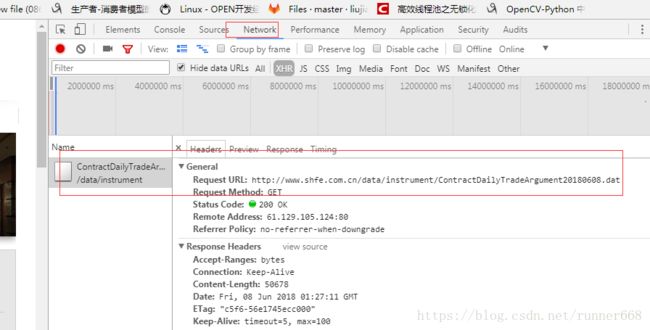
可以看到返回的数据是json字典形式
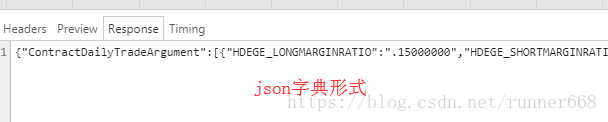
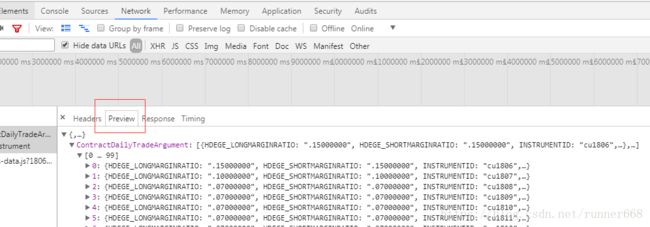
4 写脚本抓数据写入CSV文件
'''
Created on Feb 28, 2017
@author: hcq908
'''
import csv
import os
# import re
from urllib.request import urlopen
#from bs4 import BeautifulSoup
import json
if __name__ == '__main__':
iCntTable = 0;
html = urlopen("http://www.shfe.com.cn/data/instrument/ContractDailyTradeArgument20180608.dat")
html = html.read().decode("utf8").encode("utf8")
print(type(html))
#加载成json的字典形式
my_html = json.loads(html)
print(type(my_html))
#print(my_html[1:200])
print(my_html['ContractDailyTradeArgument'][0]['HDEGE_LONGMARGINRATIO'])
print(type(my_html['ContractDailyTradeArgument'][0]['HDEGE_LONGMARGINRATIO']))
a =my_html['ContractDailyTradeArgument'][0]['HDEGE_LONGMARGINRATIO'];
print(int(a[1:3]))
print(len(my_html))
date_a = []
#路劲不存在是需要新建
sDir = './my_data'
sTitleName = 'my.csv'
if not os.path.exists(sDir):
os.mkdir(sDir)
sCSV_Path = os.path.join(sDir,sTitleName);
with open(sCSV_Path, 'wt', newline='', encoding='utf-8') as csvFile: #创建可写文件
writer = csv.writer(csvFile)
writer.writerow(['HDEGE_SHORTMARGINRATIO','HDEGE_LONGMARGINRATIO','HDEGE_LONGMARGINRATIO','INSTRUMENTID',
'LOWER_VALUE','SPEC_LONGMARGINRATIO','SPEC_SHORTMARGINRATIO']) #写入一行
for i in range(len(my_html['ContractDailyTradeArgument'])):
date_b = []
date_b.append(my_html['ContractDailyTradeArgument'][i]['INSTRUMENTID'])
#print(my_html['ContractDailyTradeArgument'][i]['HDEGE_LONGMARGINRATIO'][1:3])
date_b.append(int(my_html['ContractDailyTradeArgument'][i]['HDEGE_LONGMARGINRATIO'][1:3]))
date_b.append(int(my_html['ContractDailyTradeArgument'][i]['HDEGE_SHORTMARGINRATIO'][1:3]))
date_b.append(int(my_html['ContractDailyTradeArgument'][i]['LOWER_VALUE'][1:3]))
date_b.append(int(my_html['ContractDailyTradeArgument'][i]['SPEC_LONGMARGINRATIO'][1:3]))
date_b.append(int(my_html['ContractDailyTradeArgument'][i]['SPEC_SHORTMARGINRATIO'][1:3]))
writer.writerow(date_b) #写入一行
对比网页数据和csv文件发现已经有点相似了吧,哈哈