大数据平台监控(二):Ganglia与Nagios的整合
基本介绍
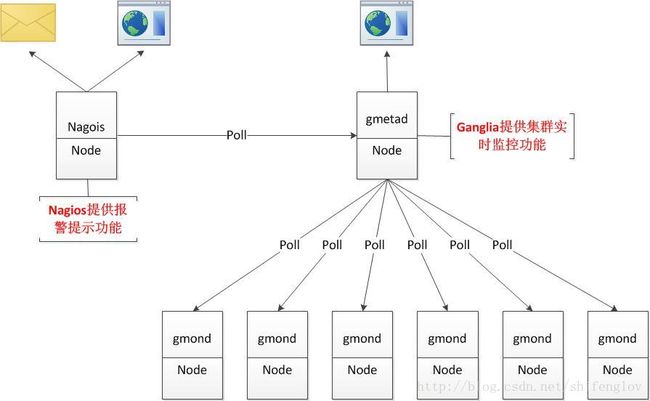
Ganglia:Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond、gmetad以及一个Web前端。主要是用来监控系统性能,如:cpu 、mem、硬盘利用率, I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
Nagios:Nagios是一款开源的电脑系统和网络监视工具,能有效监控Windows、Linux和Unix的主机状态,交换机路由器等网络设置,打印机等。在系统或服务状态异常时发出邮件或短信报警第一时间通知网站运维人员,在状态恢复后发出正常的邮件或短信通知。
架构
Ganglia的优势在于实时监控集群中的机器的各项指标,比如cpu,内存,磁盘,温度等数据,汇总成成各种图形化界面,并提供接口可供调用数据。而在出现问题的时候报警提示功能,相对较弱。
Nagios的优势在于出现问题之时可以提供强大的报警提示功能,但是在实时监控上,功能较弱,即使使用NRPE本地插件也不能提供强大的机器监控。
在集群运维中,有两种方式,第一种,当问题出现的时候能够得到报警提示,运维人员能够迅速出击解决问题,将损失减少到最少。第二种,在问题出现之前,找到可能出现的问题,解决问题,避免问题出现。
因此Nagios适合第一种场景,Ganglia适合第二种场景,两者结合能有效的解决各种场景。当然还有其他的监控报警软件,比如Monitorix,NetXMS,cacti,Zabbix等。
这里,我们选择最成熟的Ganglia和Nagios。
环境介绍
1. 集群中已经安装了Ganglia(安装过程可以参考我的上一篇博客http://blog.csdn.net/shifenglov/article/details/40587527)
2. 集群中已经安装了Nagios(安装过程可以参考这篇博客http://www.cnblogs.com/mchina/archive/2013/02/20/2883404.html)
安装思路
通过Nagios调用Ganglia的接口,获取整个集群的监控指标,如果超过设定的报警阀值,则予以报警提示。
安装过程
1. 复制check_ganglia.py脚本到nagios的执行目录中
如果有源码,则check_ganglia.py在ganglia-3.6.0/contrib/check_ganglia.py中
如果没有源码,则可以下载check_ganglia.py,很容易搜到
#cp check_ganglia.py/usr/local/nagios/libexec/
2. 修改service.cfg文件,配置相应的ganglia的监控服务
# vi/usr/local/nagios/etc/objects/services.cfg
define servicegroup { ##定义相应的服务组
servicegroup_name ganglia-metrics
alias Ganglia Metrics
}
define command { ##定义相应的获取ganglia监控数据的命令
command_name check_ganglia
command_line $USER1$/check_ganglia.py -h $HOSTNAME$ -m $ARG1$ -w $ARG2$-c $ARG3$
}
define service {
use generic-service
name ganglia-service
hostgroup_name rimi-servers
service_groups ganglia-metrics
notifications_enabled 0
}
define service {
use ganglia-service
service_description load_one
check_command check_ganglia!load_one!4!5
}
define service {
use ganglia-service
service_description cpu_idle
check_command check_ganglia!cpu_idle!30!15
}
define service {
use ganglia-service
service_description disk_free
check_command check_ganglia!disk_free!100!503. 修改gmetad配置,使其share监控数据
因为默认情况下,ganglia的gmetad服务不会share监控指标给网络上的其他机器,默认只能把数据传输到localhost,所以需要做相应的配置,使其可以share相应数据给其他机器。主要是考虑nagios的主机与ganglia的主机没在同一台机器上。
# vi /etc/ganglia/gmetad.conf
trusted_hosts 192.168.7.12 ##添加信任的主机IP4. 修改check_ganglia.py脚本的端口号和ip地址
因为check_ganglia.py脚本默认只会从localhost去获得ganglia中gmetad的监控数据,所以此处需要修改脚本,使其可以从集群中某一台主机获取监控指标
#vi/usr/local/nagios/libexec/check_ganglia.py
ganglia_host = '192.168.7.17' ##指定gmetad机器的IP地址
ganglia_port = 8651 ##指定gmetad机器的端口地址5. 修改check_ganglia.py脚本,监控只对大于等于设定值的情况可以进行报警提示,没有对等于小于的情况做报警提示(可以根据自己应用场景考虑是否修改脚本)
脚本之中,只对监控值大于设定值时做了报警提示,比如:
温度大于 50度,发出warning报警,大于80度时,发出critical报警
而相对小于设定值做报警的提示,则不能实现。比如:
当内存的空闲值小于 100M,发出warning报警,小于80M,发出critical报警
不能实现。
check_ganglia.py:
#!/usr/bin/env python
import sys
import getopt
import socket
import xml.parsers.expat
class GParser:
def __init__(self, host, metric):
self.inhost =0
self.inmetric = 0
self.value = None
self.host = host
self.metric = metric
def parse(self, file):
p = xml.parsers.expat.ParserCreate()
p.StartElementHandler = parser.start_element
p.EndElementHandler = parser.end_element
p.ParseFile(file)
if self.value == None:
raise Exception('Host/value not found')
return float(self.value)
def start_element(self, name, attrs):
if name == "HOST":
if attrs["NAME"]==self.host:
self.inhost=1
elif self.inhost==1 and name == "METRIC" andattrs["NAME"]==self.metric:
self.value=attrs["VAL"]
def end_element(self, name):
if name == "HOST" and self.inhost==1:
self.inhost=0
def usage():
print """Usage: check_ganglia \
-h|--host= -m|--metric= -w|--warning= \
-c|--critical= -o|--opposite=[-s|--server=] [-p|--port=] """
sys.exit(3)
if __name__ == "__main__":
##############################################################
ganglia_host = '192.168.7.17'
ganglia_port = 8651
host = None
metric = None
warning = None
critical = None
opposite = 0 ##增加一个参数,表示设定值取反,也就是当实际值小于等于设定值报警
try:
options, args = getopt.getopt(sys.argv[1:],
"h:m:w:c:o:s:p:",
["host=", "metric=", "warning=","critical=","opposite=", "server=","port="],
)
except getopt.GetoptError, err:
print "check_gmond:", str(err)
usage()
sys.exit(3)
for o, a in options:
if o in ("-h", "--host"):
host = a
elif o in ("-m", "--metric"):
metric = a
elif o in ("-w", "--warning"):
warning = float(a)
elif o in ("-c", "--critical"):
critical = float(a)
elif o in ("-o", "--opposite"):
opposite = int(a)
elif o in ("-p", "--port"):
ganglia_port = int(a)
elif o in ("-s", "--server"):
ganglia_host = a
if critical == None or warning == None or metric == None or host ==None:
usage()
sys.exit(3)
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ganglia_host,ganglia_port))
parser = GParser(host, metric)
value = parser.parse(s.makefile("r"))
s.close()
except Exception, err:
print "CHECKGANGLIA UNKNOWN: Error while getting value\"%s\"" % (err)
sys.exit(3)
if opposite == 1: ###根据传入参数做判断,等于1时,表示取反,等于0,不取反
if value <= critical:
print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value)
sys.exit(2)
elif value <= warning:
print "CHECKGANGLIA WARNING: %s is %.2f" % (metric, value)
sys.exit(1)
else:
print "CHECKGANGLIA OK: %s is %.2f" % (metric, value)
sys.exit(0)
else:
if value >= critical:
print "CHECKGANGLIA CRITICAL: %s is %.2f" % (metric, value)
sys.exit(2)
elif value >= warning:
print "CHECKGANGLIA WARNING: %sis %.2f" % (metric, value)
sys.exit(1)
else:
print "CHECKGANGLIA OK: %s is %.2f" % (metric, value)
sys.exit(0)相应的,也需要修改service.cfg配置文件:
defineservicegroup {
servicegroup_name ganglia-metrics
alias Ganglia Metrics
}
definecommand {
command_name check_ganglia
command_line $USER1$/check_ganglia.py -h$HOSTNAME$ -m $ARG1$ -w $ARG2$ -c $ARG3$-o $ARG4$ ##增加-o参数,表示是否取反
}
defineservice {
use generic-service
name ganglia-service
hostgroup_name rimi-servers
service_groups ganglia-metrics
notifications_enabled 0
}
defineservice {
use ganglia-service
service_description load_one
check_command check_ganglia!load_one!4!5!0 ##增加参数,表示正常
}
defineservice {
use ganglia-service
service_description cpu_idle
check_command check_ganglia!cpu_idle!30!15!1 ##增加参数,表示取反
}
defineservice {
use ganglia-service
service_description disk_free
check_command check_ganglia!disk_free!100!50!1##增加参数,表示取反
}启动并访问
配置完成之后,重启ganglia和nagios,访问nagios网站,看到相应的服务已经存在,比如cpu,内存,磁盘的检查。

问题解决
1、 配置完成之后,nagios拿到的数据显示是null
可能是check_ganglia.py脚本中的host和ip没有设置正确,应该设置成gmetad服务器的地址,默认是8651端口,gmond上传监控数据到gmetad的端口是8649,不要混淆了。
参考资料
Nagios的安装
http://www.cnblogs.com/mchina/archive/2013/02/20/2883404.html
原创文章,欢迎转载,转载请标明出处 http://blog.csdn.net/shifenglov/article/details/40658007