从头开始讲Node.js——异步与事件驱动
自从Node.js出来之后,火得一塌糊涂,前端程序员在学,后台程序员也在学。
很久之前试着用node+express+mongoDB搭建过一个小型的网站,然后心得体会都写在了这几篇博客中:
MongoDB学习笔记之Mongoose的使用
javascript笔记之express初体验
Express中使用Jade
nodejs实战之简单实现服务器端(顺便讲一下URL)
Nodejs学习笔记之从bodyParse来看app.use()
当时写了很多很多,不过都是node的皮毛而已。这里还有很多很多。
more
现在写的这一篇不讲工程,不讲项目。就从头讲一下Node。
Node.js可以做什么
1.可以开发具有复杂逻辑的网站
2.开发具有社交网络的大规模web应用
3.Web Socket服务器
4.TCP/UDP套接字应用程序
5.交互式终端程序
6.命令行工具
7.带有图形界面的本地应用程序
8.单元测试工具
9.客户端javascript编译器
由此可见Node.js是无所不能的
Node.js特色
内置HTTP服务
Node.js 内建了 HTTP 服务器支持,也就是说你可以轻而易举地实现一个网站和服务器的组合。这和 PHP、Perl 不一样,因为在使用 PHP 的时候,必须先搭建一个 Apache 之类的 HTTP 服务器,然后通过 HTTP 服务器的模块加载或 CGI 调用,才能将 PHP 脚本的执行结果呈现给用户。而当你使用 Node.js 时,不用额外搭建一个 HTTP 服务器,因为 Node.js 本身就内建了一个。这个服务器不仅可以用来调试代码,而且它本身就可以部署到产品环境,它的性能足以满足要求。
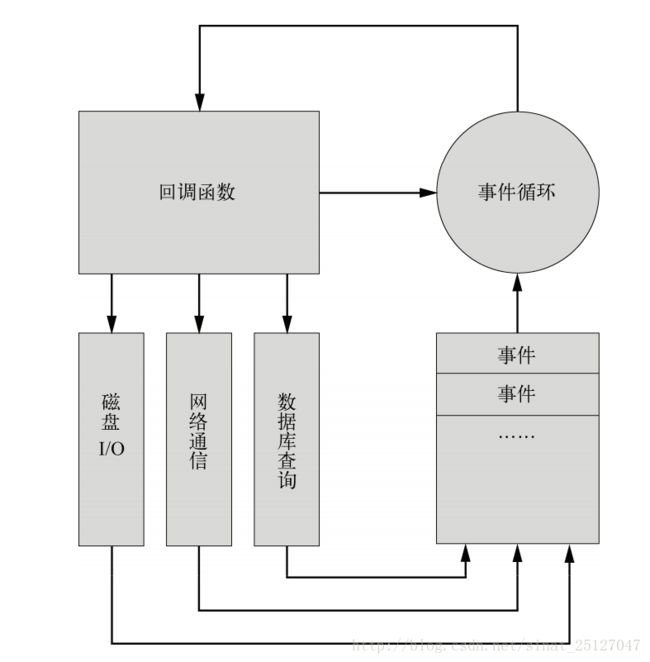
如图所示:
因此,创建一个node的HTTP非常简单。
var http = require('http')
http.createServer(function(req, res) {
res.writeHead(200, {
'Content-Type': 'text/html'
});
res.write('Node.js
');
res.end('Hello Node
');
}).listen(3000)
console.log('HTTP server is listen at port 3000');运行
显示结果
打开调试工具

确实可以看到返回的res。
用postman也可以测试
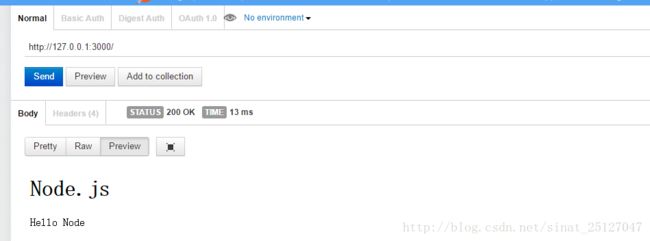
确实,node.js不需要部署服务器,不像PHP还需要Apache,之前觉得windows下配置PHP的环境很麻烦(后来用wamp包还好了一点)
所以Node.js麻烦之处在哪里呢?大概就是异步I/O与事件驱动了吧
异步I/O与事件驱动
Node.js 最大的特点就是采用异步式 I/O 与事件驱动的架构设计。
对于高并发的解决方案,传统的架构是多线程模型,也就是为每个业务逻辑提供一个系统线程,通过系统线程切
换来弥补同步式 I/O 调用时的时间开销。
**Node.js 使用的是单线程模型,对于所有 I/O 都采用异步式的请求方式,避免了频繁的上下文切换。**Node.js 在执行的过程中会维护一个事件队列,程序在执行时进入事件循环等待下一个事件到来,每个异步式 I/O 请求完成后会被推送到事件队列,等待程序进程进行处理。
例如,对于数据库请求,传统的思维是这样写的话。
后面的res.output()需要等到数据库查询完毕才能执行。
res = db.query('SELECT * from some_table');
res.output(); 以上代码在执行到第一行的时候,线程会阻塞,等待数据库返回查询结果,然后再继续处理。然而,由于数据库查询可能涉及磁盘读写和网络通信,其延时可能相当大(长达几个 到几百毫秒,相比CPU的时钟差了好几个数量级),线程会在这里阻塞等待结果返回。对于 高并发的访问,一方面线程长期阻塞等待,另一方面为了应付新请求而不断增加线程,因此 会浪费大量系统资源,同时线程的增多也会占用大量的 CPU 时间来处理内存上下文切换, 而且还容易遭受低速连接攻击。

看一下Node.js是如何解决这个问题的。
db.query('SELECT * from some_table', function (res) {
res.output();
}); 这段代码中 db.query 的第二个参数是一个函数,我们称为回调函数。进程在执行到 db.query 的时候,不会等待结果返回,而是直接继续执行后面的语句,直到进入事件循环。当数据库查询结果返回时,会将事件发送到事件队列,等到线程进入事件循环以后,才会调用之前的回调函数继续执行后面的逻辑。
如图所示,数据库查询和output同时进入事件循环队列。

Node.js 的异步机制是基于事件的,所有的磁盘 I/O 、网络通信、数据库查询都以非阻塞的方式请求,返回的结果由事件循环来处理。如图 描述了这个机制。Node.js 进程在同一时刻只会处理一个事件,完成后立即进入事件循环检查并处理后面的事件。
这样做的好处是CPU 和内存在同一时间集中处理一件事,同时尽可能让耗时的 I/O 操作并行执行。对于低速连接攻击,Node.js 只是在事件队列中增加请求,等待操作系统的回应,因而不会有任何多线程开销,很大程度上可以提高 Web 应用的健壮性,防止恶意攻击。

同步异步 ,阻塞与非阻塞
同步与异步
同步与异步同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。换句话说,就是由调用者主动等待这个调用结果。
而异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用。典型的异步编程模型比如Node.js
举个通俗的例子:你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下”,然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。
阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。
还是上面的例子,你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了,
当然你也要偶尔过几分钟check一下老板有没有返回结果。在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。
作者:严肃
链接:https://www.zhihu.com/question/19732473/answer/20851256
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
像java、python这个可以具有多线程的语言。多线程同步模式是这样的,将cpu分成几个线程,每个线程同步运行。
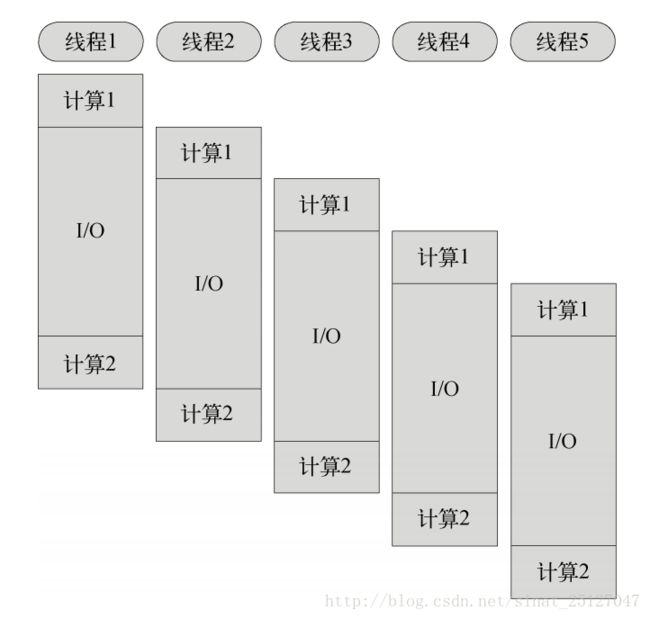
而node.js采用单线程异步非阻塞模式,也就是说每一个计算独占cpu,遇到I/O请求不阻塞后面的计算,当I/O完成后,以事件的方式通知,继续执行计算2。
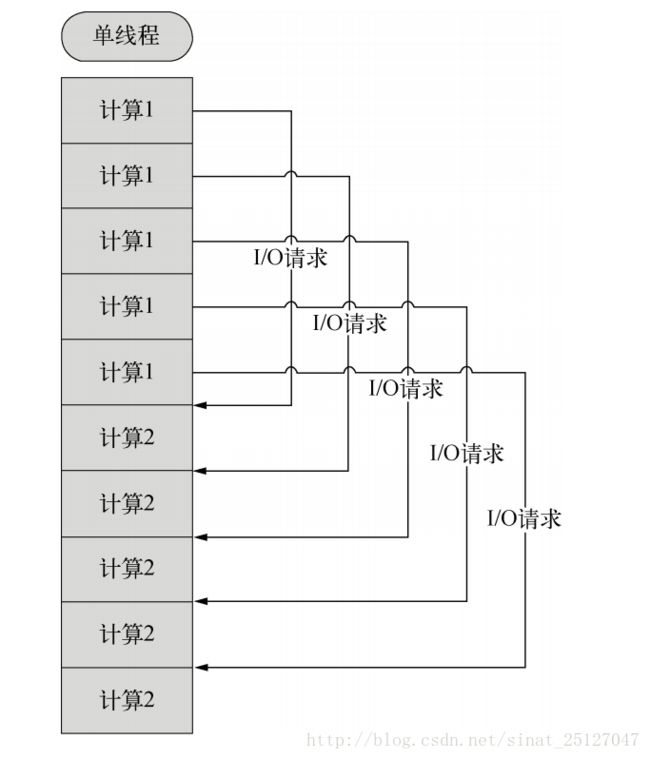
异步编程实战
回调函数方式
先看这一段代码,可以先想一下,它的执行结果是什么?
这段代码一共两个计算事件:读文件,打印“end”
一个I/O事件:读文件
var fs = require('fs');
fs.readFile('file.txt', 'utf-8', function(err, data) {
if (err) {
console.error(err);
} else {
console.log(data);
}
});
console.log('end');也就是流程图是这样的:
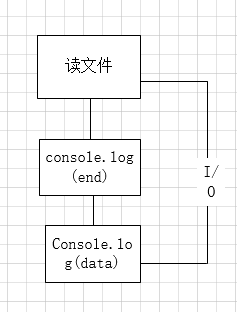
接下来我们看结果,确实是这样的
fs也提供了同步读取文件方式。
var fs = require('fs');
// var data = fs.readFile('file.txt', 'utf-8'); //undefined,end
var data = fs.readFileSync('file.txt', 'utf-8'); //content,end
console.log(data);
console.log('end');如果不采用fs.readFileSync,那么打印data的话就是undefined,因为我们没有将它写到回调函数中去,它就顺序执行,但是到执行到它这句话的时候文件读取(I/O)并没有结束,因此是undefined;
如果采用同步方式的话,console.log(data); 必须等待fs.readFileSync文件读取完毕才执行。虽然这样的方式并不可取,因为会存在等待时间。后面的事件都阻塞了。
Node.js 中,并不是所有的 API 都提供了同步和异步版本。Node.js 不鼓励使用同步 I/O 。
事件
还是从看代码开始,顺便说一下,这里的代码都是《Node.js 开发指南》里面来的,有些有少量的改动。
event.on 事件监听。
之前好像就总结过js里面关于事件监听的几种方法。
event.emit 发送事件。
下面这段代码,event.on就是在监听some_event的发生,一旦发生后,调用回调函数,打印(some_event occured)
var EventEmitter = require('events').EventEmitter;
var event = new EventEmitter();
event.on('some_event', function() {
console.log('some_event occured');
});
setTimeout(function() {
event.emit('some_event') //发送事件
}, 2000)运行这段代码,1秒后控制台输出了 some_event occured. 。其原理是 event 对象注册了事件 some_event 的一个监听器,然后我们通过 setTimeout 在2000 毫秒以后向 event 对象发送事件 some_event ,此时会调用 some_event 的监听器。
结果:
Node.js 的事件循环机制
Node.js 在什么时候会进入事件循环呢?
答案是 Node.js 程序由事件循环开始,到事件循环结束,所有的逻辑都是事件的回调函数,所以 Node.js 始终在事件循环中,程序入口就是事件循环第一个事件的回调函数。事件的回调函数在执行的过程中,可能会发出 I/O 请求或直接发射(emit )事件,执行完毕后再返回事件循环,事件循环会检查事件队列中有没有未处理的事件,直到程序结束。
图3-5说明了事件循环的原理。