SparkStreaming 搭建《一》Win10可通用,供参考
是在本地windows配的,具体的如何配置其实要搞的麻烦事很多,多百度吧。
编译环境:
Spark2.3.1
scala2.11.8
jdk1.8
hadoop2.6.5
hive1.2.2
kafka1.1.0
Hbase1.4.5
一、新建工程:File-scala-idea
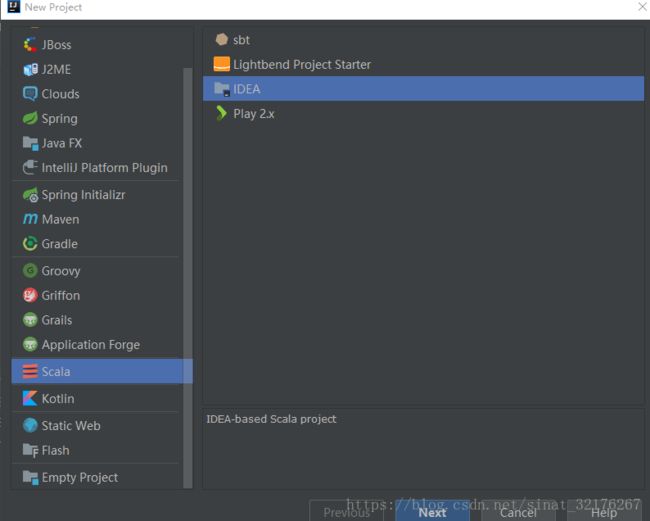
二、指定工程名称,JDK版本,Scala版本。
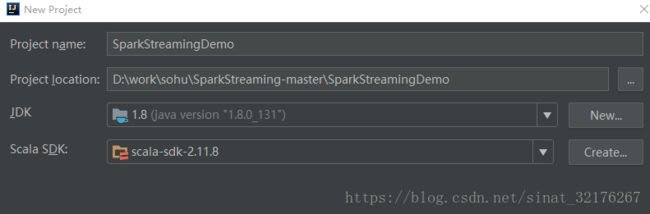
三、这里你看到的是scala项目,但是我们一般常用的是mvn项目,这里需要单击工程,右键选择添加框架,填写maven架构
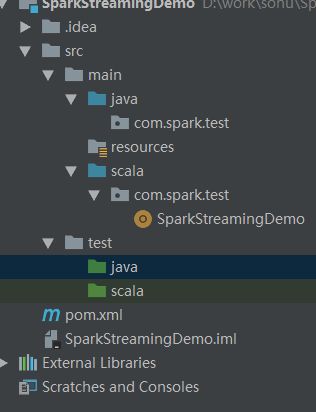
四、这里需要修改文件夹最好按照以下样式进行修改,点击Project Structuer仅供参考。
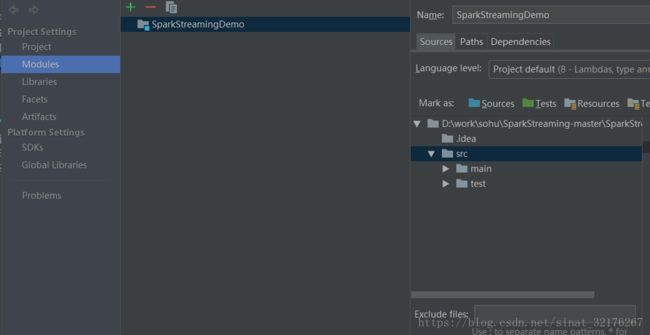
修改后的目录结构如下图:如果想替换该文件夹属性,点击上方的不同颜色的文件夹即可。
五、导入pom文件
2.2.0
2.11
org.apache.spark
spark-core_${scala.version}
${spark.version}
org.apache.spark
spark-streaming_${scala.version}
${spark.version}
org.apache.spark
spark-sql_${scala.version}
${spark.version}
org.apache.spark
spark-core_2.11
2.0.1
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.scala-tools
maven-scala-plugin
2.15.2
compile
testCompile
maven-compiler-plugin
3.6.0
1.8
1.8
org.apache.maven.plugins
maven-surefire-plugin
true
六、新建一个scala的wordCount测试类,试试搭建的环境是否正确,前提是要开启本地的hadoop环境。
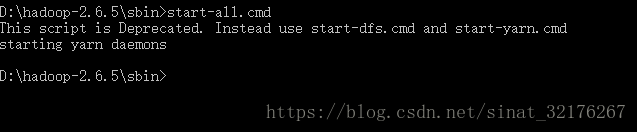
因为我的hadoop安装在本地的D盘。
新建测试类
package test
import org.apache.spark.{SparkConf, SparkContext}
object SecondarySort {
def main(args: Array[String]): Unit = {
//测试Spark Demo
val conf = new SparkConf().setAppName("wordCount").setMaster("local")
//创建Spark上下
val sc = new SparkContext(conf)
//从文件中获取数据
val input = sc.textFile("D:\\tmp\\spark.txt")
sc.setLogLevel("Warn")
def myfunc(a:String):String={
a + 's'//分成两组
}
// 2012,12,24,70
// 2012,12,25,10
// 2013,01,23,90
// 2013,01,24,70
// 2013,01,20,-10原始数据
val rdd = input.map(line=> line.split(","))
//groupByKey 把相同key的分组在一起 sortByKey false是逆序排序 以key的形式进行分组 sortBy的数据
//((2013,01),CompactBuffer(90, 70, -10))
//((2012,12),CompactBuffer(30, -20, 60, 70, 10))
.map(x=>((x(0),x(1)),x(3))).groupByKey().sortByKey(false)
.map(x => (x._1._1+"-"+x._1._2,x._2.toList.sortWith(_>_)))
//x._1 是(2013,01)得到的key是(2013,1)value是(90,70,-10) 因为key 是一个二元数组。
//读到的是 未加x._1的情况
// ((2013,01)2013-01,List(90, 70, -10))
//(2012-12,List(70, 60, 30, 10, -20))
//(2000-12,List(10, -20))
//(2000-11,List(30, 20, -40))
rdd.foreach(
x=>{
val buf = new StringBuilder()
//取出第二个字段里的数据然后进行添加。
for(a <- x._2){
//遍历每一个x._2然后在每一行进行遍历。
buf.append(a)
buf.append(",")
}
buf.deleteCharAt(buf.length()-1)
println(x._1+" "+buf.toString())
})
// (2013,01)2013-01 90,70,-10
// (2012,12)2012-12 70,60,30,10,-20
// (2000,12)2000-12 10,-20
// (2000,11)2000-11 30,20,-40
sc.stop()
}
}
测试数据如下:
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2012,12,21,30
2012,12,22,-20
2012,12,23,60
2012,12,24,70
2012,12,25,10
2013,01,23,90
2013,01,24,70
2013,01,20,-10
七、如果
在pom.xml中引入依赖后, 发现External Libraries只有jdk没有其他的jar, 在java代码中也无法用引入的类.
解决
在idea右侧的Maven Projects右击项目选择Reimport, 此时开始将jar导入到项目中, 但是这个加载过程又特别慢,填写如下图参数重启idea重新Reimport即可解决:
-DarchetypeCatalog=internal
最后完成......
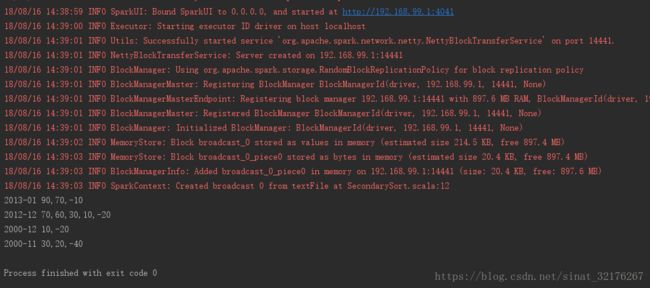
八、打印结果: