Python爬虫练习笔记——爬取单个网页里的所有图片(入门)
最近闲着,想学一下爬虫 (^-^)V ——[手动比耶]
先从简单的练习开始吧~ 爬取单个网页里的所有图片,这个没有什么难点,因为不需要翻页哈哈哈哈。
我很喜欢一些文章中的配图,比如这篇,里面就会有很多电影中的经典截图。

第一步:分析网页
首先需要了解要爬取网站的页面,查看网页源代码。然后根据网页源代码的结构,想好代码的步骤和思路。
在网页中查看页面的源代码(F12)
-
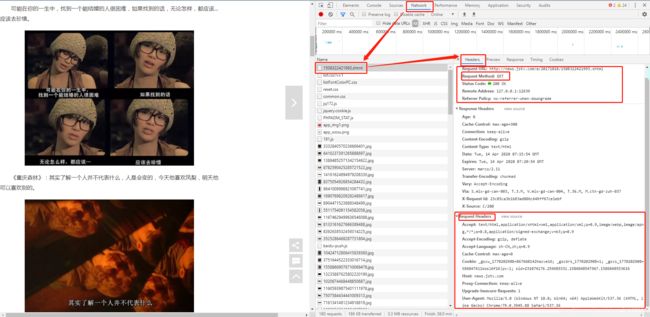
先来看一下页面的请求方式:
在开发者模式的Network里找到.html的请求,可以看到请求方式是GET请求,也没有带什么特殊的请求参数之类的~ 比较简单。
(如果没有看到.html的请求,刷新一下页面就出来了)
-
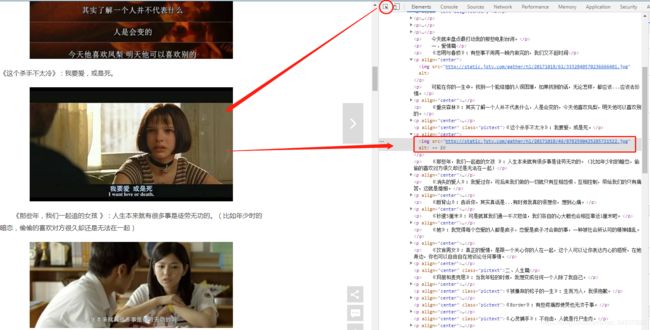
然后再看代码结构:
(不太熟悉html的小伙伴可以使用圈圈里的小箭头,点一下自己想要看的元素,然后右侧就会自动跳转到该元素对应的代码区域的~四不四很简单)结合“上下文”简单分析一下就会发现:(有种做阅读理解的感觉hhhhh)
① 这个网页里所有的图片都是放在src后面,src后面这个链接就是图片的地址
(可以复制下来在浏览器打开确认一下)
② 图片上方的描述语是放在class="pictext"的p标签里的
(曾打算过用这个描述语句作为爬下来的图片的名称的)
这样一来就很简单了
只需要先拿到网页的 HTML 代码,然后把页面里面所有src后面超链接的内容取出来就行了!
第二步:开始编程
1. 定义库
- 首先需要用 requests 库来发出一个网络请求:
import requests
- 然后需要用 BeautifulSoup 来解析和提取 HTML 数据
from bs4 import BeautifulSoup
这里也可以直接import bs4,但代码中每次用的时候都要写上包名bs4,如:bs4.BeautifulSoup 啥啥啥
而from bs4 import BeautifulSoup 是直接将BeautifulSoup 类导入到当前命名空间直接使用,不需要再带包名。因此建议用from bs4 import BeautifulSoup
- 最后需要还需要用 urllib.request 来将网络对象复制到本地文件
import urllib.request
感觉 urllib.request 和前面导入的 requests有点像呀~ 查了一下资料发现是这样:
通常而言,在我们使用python爬虫时,更建议用requests库,因为requests比urllib更为便捷,requests可以直接构造get,post请求并发起,而urllib.request只能先构造get,post请求,再发起。
但是将网络对象复制到本地文件这个功能需要通过 urllib.request.urlretrieve()函数来实现,所以两个库都导入了。
这个网页比较简单,导入这三个库就够用了~
2. 定义一个函数getMoviesImg()
① 获取网站数据:
res = requests.get(url,params=params,headers=headers) 这样获取到的结果是一个 HTTP 状态码。
需要用.text 方法再来获取一下这个结果里的文本信息。
有的网站对于反爬虫力度比较大,请求的时候可以构造一个请求头加上,请求头(Request Headers)在最前面开发者模式中的 Network 里就可以找到。
今天爬取的这个页面很简单,就直接 GET 请求 url 即可,可以啥都不带。
#获取网站数据
url = requests.get('http://news.jstv.com/a/20171018/1508322421993.shtml')
#url.encoding = 'utf-8' #如果需要用到页面中的汉字内容,则需要进行解码,否则中文会出现乱码
html = url.text
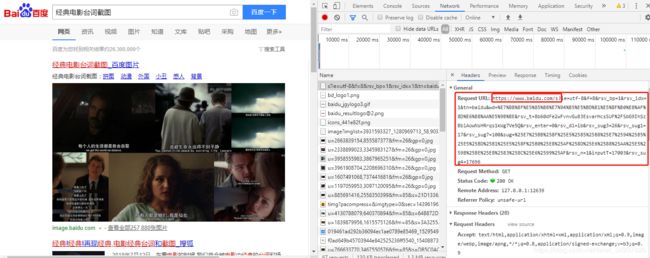
ps:比如这个页面↓,百度搜索“经典电影台词截图”,请求的url就是由问号 ? 前面基本的url地址和后面的一大堆参数组成的,这时候就需要用到 params 了。
② 解析网页:
BeautifulSoup4 是将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,之后就可以利用 soup 加标签名轻松地获取这些标签的内容了。
参考beautifulsoup菜鸟教程
BeautifulSoup(markup,'html.parser')
- markup 是被解析的html格式的内容
- html.parser表示解析用的解析器
#解析网页
soup = BeautifulSoup(html,'html.parser')
③ 获取所有标签内容:
完成了前面的工作,获取标签内容就变得很简单了~
#获取所有的img标签
movie = soup.find_all('img')
#获取src路径
for i in movie:
imgsrc = i.get('src')
- 扩展一下~
bs = BeautifulSoup(html,"html.parser")
print(bs.title) # 获取title标签的所有内容
print(bs.title.name) # 获取title标签的标签名称
print(bs.title.string) # 获取title标签的文本内容
print(bs.head) # 获取head标签的所有内容
print(bs.div) # 获取第一个div标签中的所有内容
print(bs.div["id"]) # 获取第一个div标签的id的值
print(bs.a) # 获取第一个a标签的所有内容
print(bs.find_all("a")) # 获取所有的a标签的所有内容
print(bs.find(id="u1")) # 获取id="u1"
for item in bs.find_all("a"):
print(item.get("href")) # 获取所有的a标签,并遍历打印a标签中的href的值
for item in bs.find_all("a"):
print(item.get_text()) # 获取所有的a标签,并遍历打印a标签的文本值
④ 将URL表示的网络对象下载到本地:
我这里用到的是 urlretrieve () 函数,它可以直接将远程数据下载到本地。
urlretrieve(url, filename=None, reporthook=None, data=None)
url:外部或者本地url,url中建议不要含有中文,否则容易出错。
finename:指定了保存本地路径(如果参数未指定,urllib会生成一个临时文件保存数据。)
reporthook:是一个回调函数,当连接上服务器、以及相应的数据块传输完毕时会触发该回调,我们可以利用这个回调函数来显示当前的下载进度。
data:指 post 到服务器的数据,该方法返回一个包含两个元素的(filename, headers)元组,filename 表示保存到本地的路径,header 表示服务器的响应头。
#将URL表示的网络对象复制到本地文件
urllib.request.urlretrieve(imgsrc , filename )
第三步:执行
run run run!
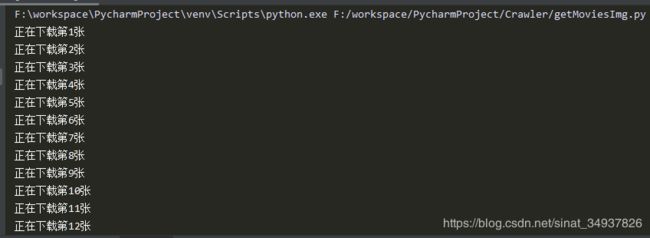
(最后有个无伤大雅的小报错,就不截图啦)
等它都跑完就可以在指定目录中看到网页里所有的图片啦~
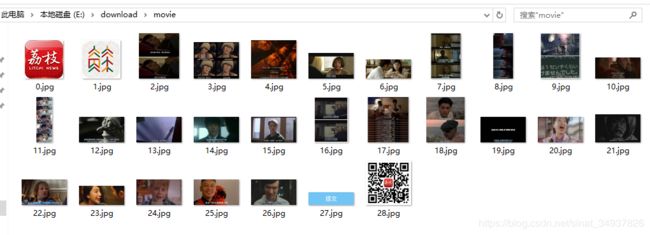
--------------------------------------------- 补充 ---------------------------------------------
第四步:优化一下吧
执行以后发现会存在两个问题:
- 网页中还有很多其它的图片,也是放在img标签里的,需要把这些图片过滤掉;
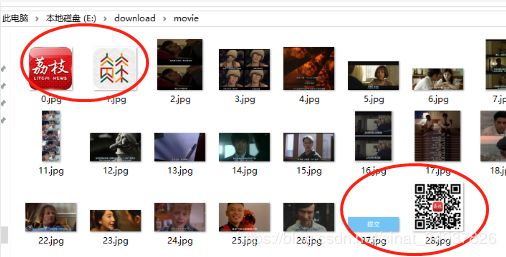
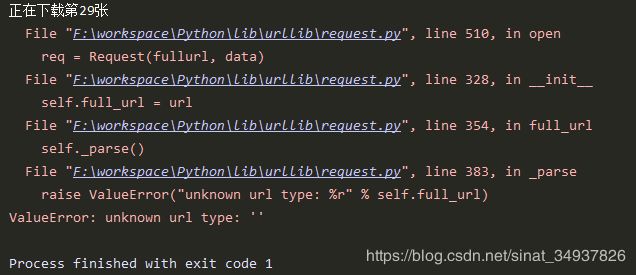
- 有一些src是空的,.urlretrieve()函数就会报错:
ValueError: unknown url type: ''。
想了一个比较简单的解决办法,就是只下载符合要求的src链接。
打印出所有的 src 路径,就会发现网页中所有想要的图片的链接路径都是以 “http://static.jstv.com/gather/hl/20171018/” 开头的。
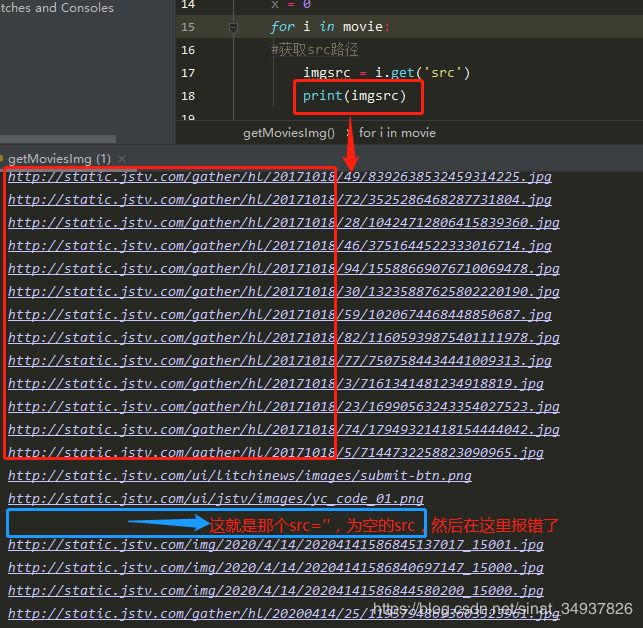
这样的话就可以用.startswith()函数判断之后再下载。
#判断图片src路径是否以指定内容开头(过滤页面中的其它不想要的图片)
if imgsrc.startswith('http://static.jstv.com/gather/hl/20171018/'):
……
改改改,runrunrun
多好看~~~
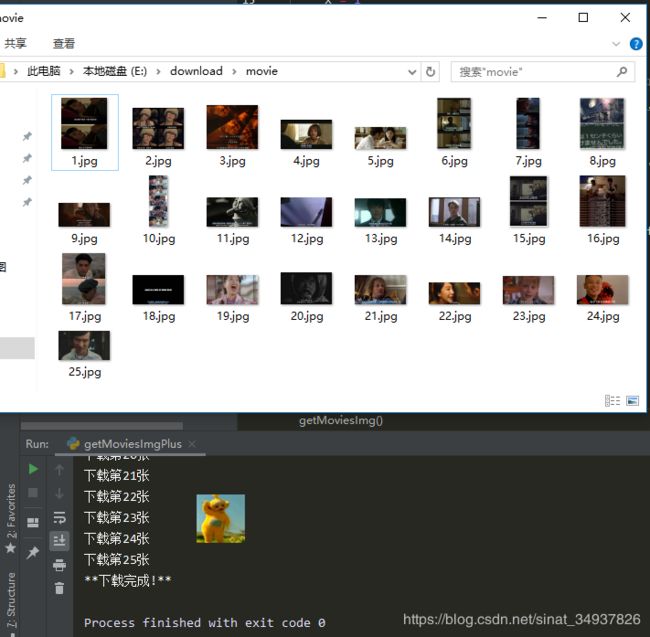
最后附上并没有多少行的完整代码:
import requests
import urllib.request
from bs4 import BeautifulSoup
def getMoviesImg():
url = requests.get('http://news.jstv.com/a/20171018/1508322421993.shtml')
#获取网站数据
html = url.text
#解析网页
soup = BeautifulSoup(html,'html.parser')
#获取所有的img标签
movie = soup.find_all('img')
x = 1
for i in movie:
# 获取src路径
imgsrc = i.get('src')
#判断图片src路径是否以指定内容开头(过滤页面中的其它不想要的图片)
if imgsrc.startswith('http://static.jstv.com/gather/hl/20171018/'):
# print(imgsrc)
#本地路径
filename = 'E:/download/movie/%s.jpg'%x
#将URL表示的网络对象复制到本地文件
urllib.request.urlretrieve(imgsrc , filename)
print('下载第%d张' % x)
x += 1
print('**下载完成!**')
getMoviesImg()
立两个小小的flag在这里:
- 下次想用网页里图片的描述作为对应图片下载后的名称。
- 以后再爬个好看的小说吧!
撒花!!!✿✿ヽ(°▽°)ノ✿