粗谈Java虚拟机5_垃圾回收
分代垃圾收集
堆中大部分的对象都是 朝生即死,典型的场景:在函数执行过程中产生的对象,在函数执行结束后,没有再被使用(引用)的对象已经没有任何的存在价值。为此,分代GC将堆内存进一步的划分为新生代和老生代两大块,从名字上就很好理解,新创建的对象必然是放在新生代,当新生代中的对象达到一定的年龄后便迁移到老年代,年龄随着每躲过一次GC便增长一岁。新生代中又划分出 1块Eden区、2块Survivor区(From和To各一块),新创建的对象在 Eden区 中分配内存空间,逃过 GC 后存活的对象拷贝到 Survivor区,达到一定年龄拷贝到老年代。Eden和Survivor之间大小默认比例为:8:1。

如上图所示,回收时将 Eden区 存活的对象,全部复制到 To区。而在 from区 的对象,根据年龄确定去向,年龄达到阈值 ( 默认15,可以通过-XX:MaxTenuringThreshold来设置 ),则移动复制到老年代,未达到阈值的复制到 To区 。接着 To区,From 角色互换,保证每次GC时,To 区都是干干净净的。当 Eden区 或 To区 内存不足时,需要老年代担保分配。
通过 JDK 自带的工具,也可以清晰的看到堆内存的 内存划分 和配置使用情况:
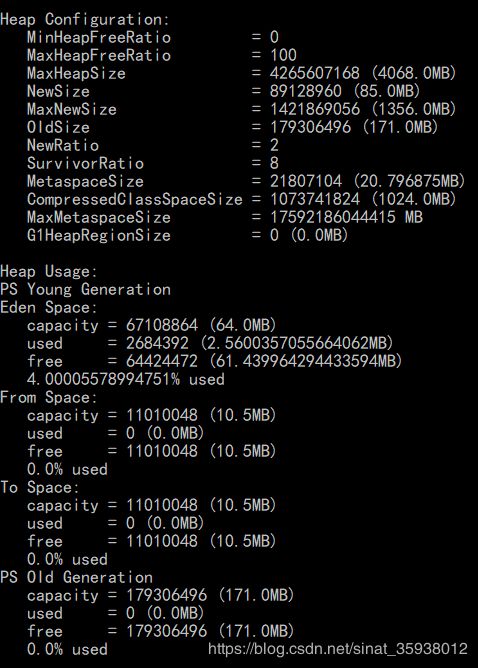
命令:jamp -heap pid;
JVM最大值,默认为物理内存的1/4或者1G,最小为2M;
JVM初始大小,默认为物理内存的1/64,最小为1M;
可达性分析算法
JVM 使用 可达性分析算法 确定堆内存中哪些对象可以回收。基本思路:通过一系列称之为 GCRoot 的对象作为起始点,向下搜索,搜索走过的路径称之为 引用链。当一个对象到 GC Roots 没有任何相连时,GC Roots到该对象不可达,则证明该对象是不可用的。
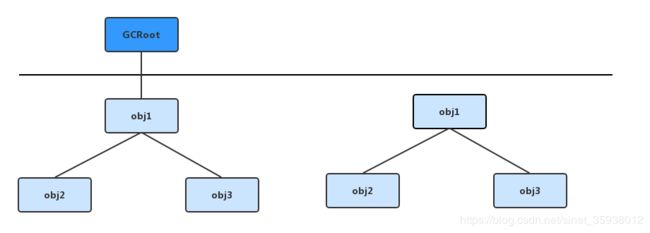
Java中可以作为GCRoot的对象有下面几种:
1.Jvm栈帧中引用的对象。
2.方法区中类变量引用的对象。
3.方法区中常量引用的对象。
4.本地方法栈中引用的对象。
其实很好理解 GCRoot对象,拿第一点和第四点来说,栈中引用的象,说明正在被执行使用,该对象和引用的对象都回收不得,做 GCRoot 再合适不过了。第二点和第三点,常量和变量的生命周期是和类绑定的,本身回收的条件就很苛刻。
枚举根节点
每个JVM线程都拥有一个JVM栈,一个栈由多个栈帧组成,一个栈帧代表一个方法。每次GC时,都需要扫描扫描所有栈来枚举出GCRoot对象,构成根集合。(这点和深入《理解JVM虚拟机》一书稍有出处,书中提到 当执行停顿下来后,并不需要一个不漏的检查完所有执行上下文和全局的引用位置,虚拟机应当是有办法得知哪些地方存放着对象引用 对此查阅了:找出栈上的指针/引用, JVM垃圾回收的根集合如何确定,JVM 之 OopMap 和 RememberedSet。得出结论:还是 每次GC时,都需要扫描所有栈来枚举出 GCRoot对象,构成根集合。这点比较合理,首先要明白几点:
1、本质上我们都是通过判断对象是否被使用(引用)来确定对象是否需要回收。对象之间的引用就像链子一样相扣,构成一条引用链。
2、其二,对象的成员变量,如果是基础类型的,在内存当中存储的是字面量,而引用类型的变量,存储的引用对象位于内存中的位置(偏移量、指针)。在进行可达性分析时,就需要得知成员变量是否是引用类型,才有必要向下搜索。Java中的对象头携带有Class对象的偏移量,可轻松得知成员变量的数据类型。如果在GC时无从得知类型,只能逐个猜测检查。

3、JVMGC 不受程序所控,无法预知何时GC,何地(哪个方法)暂停GC,如果每个方法都维护保存根对象,会是很大的资源浪费。所以只有等执行停顿后再扫描构建根集合。
老年代的对象引用新生代的对象怎么办?
跨代引用会有什么不好的影响?
假如,在对新生代 GC 时,某个对象被老生代引用,如果只扫描新生代,则会造成应该存活的对象被回收掉。反之,如果扫描老生代所有的对象就为了确认是否引用某个新生代对象,这样做太划不来了,而且老生代的内存空间本身就比新生代大。同样,如果每个对象去记录被引用对象的指针也划不来。
为了处理这种情况,在老生代有一种叫 card table的数据结构,来标记老年代的某一块内存区域中的对象是否持有新生代对象的引用,卡表的数量取决于老年代的大小和每张卡对应的内存大小,每张卡在卡表中对应一个比特位,当老年代中的某个对象持有了新生代对象的引用时,JVM就把这个对象对应的 Card 所在的位置标记为 dirty(bit位设置为1)。新生代 GC 时,只需要扫描 card 中为 dirty 的对象。摘自JVM调优:CardTable简介
回收算法
标记-清除算法
mark-sweep/mark-copy/mark-compact 三种回收算法 第一步都需要先标记出存活的对象。
标记清除算法实现简单,首先标记出存活的对象,再回收对象(复用或者清除未被标记的对象内存),会造成空间碎片。

标记-复制算法
标记存活的对象,再回收可回收对象,将剩下存活的对象复制到另外一块内存,保证之前的内存块全都可用。空间无碎片,需要复制,浪费2倍大小 ( 由具体的实现算法决定 ) 内存。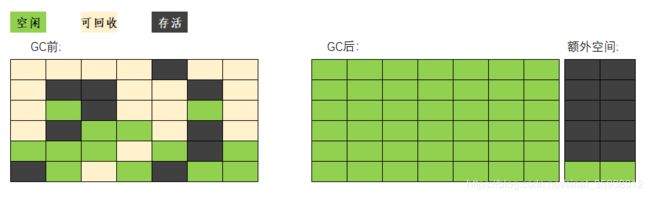
标记-整理/压缩算法
标记存活的对象,再回收可回收对象,将剩下存活的对象朝某一个方向复制移动。保证剩下的空间都是完整连续的。
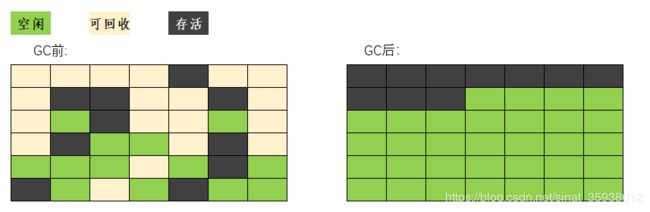
三种算法各有优缺点,由不同的垃圾收集器实现,处理不同区域的垃圾回收。分代式里,新生代常用的 mark-copy 算法 ,老年代使用 mark-sweep、mark_compact混合方法,一般情况下使用 mark-sweep算法,因为大家普遍认为老年代的对象存活时间长、存活率高,使用复制算法划不来,统计碎片率达到一定程度使用 mark-sweep算法。
垃圾收集器是标记存活的对象,不会标记回收的对象。
垃圾收集器
收集概念:
- 串行收集:所有垃圾收集事件都在一个线程完成,暂停用户程序线程。
- 并行收集:多条收集线程同时工作,暂停用户程序线程。
- 并发收集:多条收集线程和用户程序线程同时工作。
回收类型:
Minor garbage collection发生在新生代的 GC 行为,发生频繁,回收速度快。Major/Full garbage collection收集整个堆,耗时长。
Serial GC(-XX:+ UseSerialGC)
Serial 收集器实现简单,只使用 1 条线程来处理 GC 事件,只适合 CPU 配置较低的机器,多核 CPU 无法发挥优势。
Parallel GC(-XX:+ UseParallelGC)
并行GC,Serial GC 的多线程版。
-XX:ParallelGCThreads 垃圾收集器线程的数量
CMS(-XX:+ UseConcMarkSweepGC)
前面介绍的几种收集器,在收集阶段都会暂停用户线程。CMS 算法使用多个线程 并发 扫描堆 标记 查找可回收的未使用对象,执行步骤如下: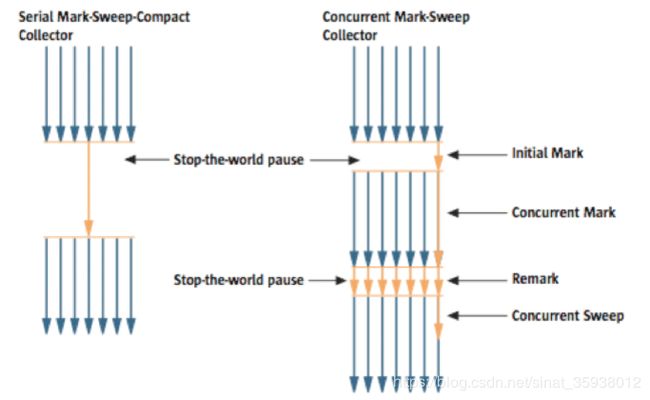
如图中所示,CMS收集器 在初始化标记和重新标记阶段仍需要 stop the world 。
- 初始化标记阶段,停止所有应用程序线程,标记 GC Roots 对象集(上面提到的 Jvm栈帧中引用的对象,静态对象等),恢复所有应用程序线程。
- 并发标记,使用一个或多个处理器,跟踪标记 GC Roots 引用链对象(对象图)。
- 重新标记,停止所有用户程序线程,找到并发标记阶段应用程序线程发生修改的遗漏对象,恢复所有应用程序线程。
- 并发清除,多线程回收对象。
CMS收集器的缺点:
- 采用
mark-sweep算法,会造成空间碎片。 - 浮动垃圾,由于应用程序线程和垃圾收集器线程是并发运行,因此在垃圾收集线程跟踪(标记存活)的对象,可能在随后的时间变得不可达(比如方法执行结束,不再被栈帧引用)。无法在本次垃圾收集回收掉,这些尚未被回收的不可达对象称为浮动垃圾。
- 比其他垃圾收集器使用更多的CPU和内存资源。
只收集老年代,默认不开启 CMS 收集器。
G1 (-XX:+ UseG1GC)
上面介绍的收集器都是整代收集,导致相当长的暂停时间。G1收集器比较优秀,将堆内存划分为多个大小相等的 region,以下图为例,整个堆内存被划分为 4068 块 1M 大小的region。
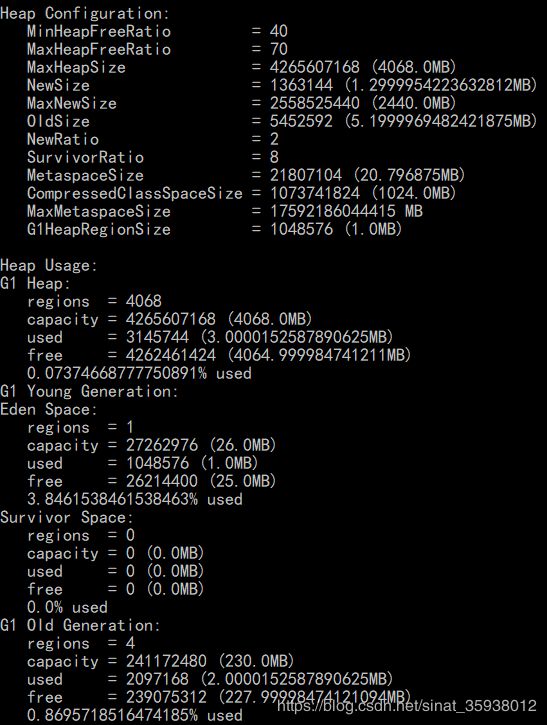
G1收集器 以 region 为收集单位,可设置 -XX:MaxGCPauseMillis=200( 默认200ms )要求 G1收集器 尽可能在规定的时间内完成 GC。设置得长点,多收点垃圾,短点就少收。G1 虽然会全局标记存活对象,但只选择收益较高的少量 region(存活对象较多和存活对象较少都算收益高,)。在标记完成后,G1 知道哪些 region 大部分是空的,首先回收这些 region,通常会产生大量的自由内存空间。
如果计划收集某个 region,则将 region 中存活的对象复制到未分配的 region。如果收集的 region 属于Eden区的空间,则将剩下的区域当作 survivor 区。
G1收集器适合在堆内存较大的情况下使用,JDK9中默认使用 G1 垃圾收集器。
G1收集器的水有点深,以后再淌。