谈复用的成本与中台的建设
今晚准备在家做饭,但少了一把菜刀,你会问邻居家借么?

复用的成本
DRY原则(Don’t Repeat Yourself)相信每一位程序员都应该知道。其指代的是我们写程序时,不要一遍又一遍地编写相似的代码。
当出现某些相似功能的代码时,我们应该将通用部分代码与特异部分代码分离,以达到复用通用代码,降低整体复杂度的目的。
按照我的理解里,一个好的程序,压缩率应该接近于0,没有任何可以精简的部分(变量名、方法名等除外)
复用带来很多好处,如:
- 利用已有资源快速开发
- 代码更清晰易懂
- 代码可以统一修改管控
- 数据可以统一分析利用
- 降低系统整体复杂度
然而达到复用的目的并非没有成本,从整体上看 复用的成本包含:
- 发现可复用逻辑的成本
- 学习可复用逻辑的成本
- 扩展可复用逻辑的成本
- 修改可复用逻辑的成本
如果整个系统是SOLO的,那么发现和学习的成本近乎于0(前提是你还记得你写过什么东西),进行复用只包含扩展和修改代码的成本。
但一个系统可能很大,完成系统所需的人数可能是:
- 几个人的小组
- 几十个人的室
- 几百人的部门
- 几千人的公司
- 几万人的集团

当我们能在公司级或者集团级较好地处理复用这件事件时,我们就称其为 中台(当然,部门中台、室中台也可以,只是复用在企业级别时换个名称显得更高大上)
但让我们回想一下自己所在的小组里,已经处理掉了重复代码,达到了完美的复用了么?如果已经完美复用了,那你所在的室呢?
我们发现,随着人数的增加以及代码数量的增加,未经过良好设计及组织,发现及使用可复用代码的难度将会急剧增加。
同时,若复用发生在利益关系不一致的不同组织(室、部门、公司、集团)里,则复用不一定能被执行。即使复用可以执行,但需求方与提供方对任务的优先级定义不一致,提供方响应速度跟不上时,那也可能使得复用无法产生。
实现DRY可能只需要一个优秀的程序员,但实现Don’t Repeat Ourselve就没这么简单了。
对于需求方团队是否要复用某个其他团队的组件,可以由一个公式来表示:
实现复用所需时间 <= 业务允许的响应时间
AND
(发现成本 + 学习成本 + 沟通协调成本 + 使用成本) <= 重新做的成本
当上述表达式为“真”,那么我们就可以考虑复用。
下面针对这个公式,进行分段讨论。
实现复用所需的时间
复用并不是总能节约开发时间:
- 发现可复用组件需要时间
- 学习可复用组件需要时间
- 可复用组件准入需要时间
- 使用本公司的组件服务所需的流程制度
- 使用其他公司的组件服务所需的商务合作的沟通
- 可复用组件的扩展需要时间
- 可复用组件的修改需要时间
- 复用组件需要经过多个业务验证才能达到一个较为稳定的状态,在此之前业务协助可复用组件演化需要更多的时间
- 可复用组件的维护团队可能跟使用者团队的利益关系不一致,导致修改的优先级更低
影响复用达成时间的因素很多,这些因素叠加起来可能导致复用所消耗的时间更多。因此对于一些时间特别敏感、由其决定生死的业务,在可复用组件未成熟,或者可复用组件支持团队的支持力度不够时,可以不考虑复用。
不复用的情况就是我们通常讲的烟囱系统,现在大环境的论调是烟囱系统不好,其在一个业务成熟的公司里确实不好。但是烟囱系统在业务早期变化大,快速野蛮生长时,由于不需要考虑复用,没有太多的条条框框限制,提供了高效的开发效率支持,为业务的存活做了重要贡献。

复用的发现成本
是什么影响了复用的发现成本?我认为主要是:
- 发现复用的方式
在几个人的小组维护的系统里,我们倾向于不产生任何重复代码。在实现某些功能时,需要确定有没有已有的枚举、类、方法、DAO时我们会问小组长,或者直接在小群里吼一声。
在几十个人的室里,我们小组要用其他小组系统的接口时,通常会由小组负责人之间拉会议沟通协调,确认对应接口是否存在,是否合适,如何使用,改造方案等。
这些发现都依赖于人,但而人的记忆是不可靠的,可能会遗忘记错,并且一旦涉及到人之间的交流的话,效率就会降低(要打断对方工作、等对方回应、要组织会议等)。因此我们要降低复用发现成本最好的方式是降低对人的依赖。
单一系统的复用发现方式
降低单一系统(单个git repo/单个eclipse项目)的复用发现成本的一种做法就是合理分包,在写好代码的同时,就把复用发现的手段给完善了。
一个合理分包的代码里,我们能够快速地推断出我们所需要的东西在哪里、是否存在。
而一个不合理分包的代码,我们会看到几十上百个类平铺于一个层级,用人眼根本找不到想要的类,必须依靠记忆中依稀记得的关键字来进行搜索。
那怎么做到合理分包?很简单,只要保持一个简单的原则
每个包的文件数量不超过10个,若超过10个则分裂成两到三个子包
但当然,包的名字必须是有含义且一眼能看明白的,这样才能让我们逐层找到我们要的文件。这其实是一种通用的控制复杂度的方法,可见文末另外一篇文章《从分治的思想到架构的设计》
降低多系统间复用发现成本
降低多个系统间复用发现成本的一种做法是搭建一个WEB系统用于统一发现可复用组件。
这个管理系统应该可以按照分类逐层查找复用组件,也可以按照关键字查找对应的复用组件。阿里云官方网站我们可以作为一种参考。
但当然,构造这么一个系统也是需要消耗大量人力物力的,在初期使用Wiki+Swagger的形式将接口信息提供出去也是不错的选择。
学习的成本
一个接口学习的成本大小与接口大小成正比。
接口大小指代要正确使用该接口所需具备的知识,如:
- 所需的参数数量
- 使用的前置条件
- 隐含的坑
- …
这些知识,我们也可以称其为“耦合”。
我们知道,耦合要越小越好,这样才能让通过接口交互的两个模块更容易地独立演进。
同时,耦合越小,我们学习这个接口的成本就越小。
当然,影响学习的成本除了接口自身要良好设计之外,还需要完善的文档与例子,这也是降低学习成本的关键。
沟通协调成本
复用的沟通协调成本在越大的组织里有可能越大。
被复用的组件需要进行修改定制时,我们需要组件的维护方提供支持,此时就需要相应的沟通协调成本。
若组件提供方与组件使用方没有任何利益关系,甚至于其利益是冲突的,那么组件提供方则缺乏动力为使用者提供支持,甚至于拒绝提供服务。这时候沟通协调成本将会特别的大。
这个问题实际上不是一个软件技术问题,这涉及到组织架构的设计。因此要降低沟通协调成本,则需要更高一级的领导设计调整 组件提供方与使用方之间的关系,使其达到利益相关、一致。
这实际上也是很多文章讲的,(企业级)中台是一把手工程的由来,其并非由技术人员就能推动的事情。

使用成本
当我们使用各种云服务时,我们需要付费,在一些较大的公司里,使用别的部门的服务也是需要付出相关成本的,当复用这些组件的成本超过自己重新做一份的成本时,我们就会考虑自己再搞一套
企业级复用的例子
以下是阿里谢纯良分享的一个关于系统复用的图:

图中包含几层
- 平台层
- 可复用的通用算法、通用中间件
- 共享业务能力层
- 可复用的通用能力,包括订单、支付、商品等
- 多应用通用功能的逻辑中心化及数据中心化
- 应用层
- 按照应用所需的流程组装共享业务能力
- 应用可包含电商、客服、CRM等
- 扩展层
- 通过扩展应用层预留的扩展点,以满足特定渠道场景的需求
以下是我之前公司系统间进行复用的图:
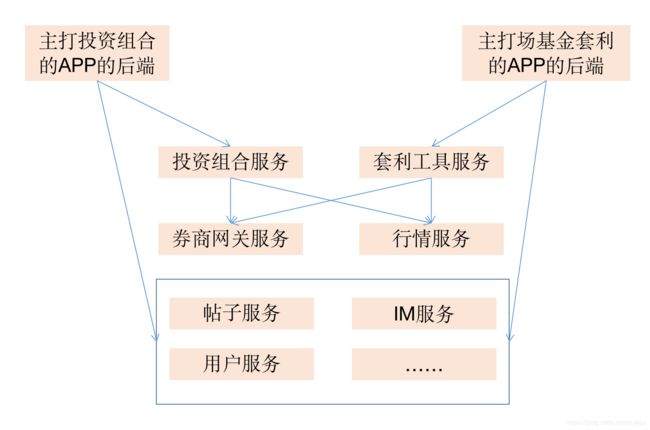
图中最顶端的对应的是阿里图中的应用层,其余的对应的是共享业务能力层。
这里共享能力层里的各种能力也有可能互相组合形成一些新的能力,如图中的投资组合服务 以及 套利工具服务。
如果我们愿意,可以把没有依赖于其他服务的服务叫原子能力服务,组合了其他原子能力服务的服务叫做组合能力服务,但这些名词仅仅在特定场景特定公司内起作用,我们作为一个程序员要穿透这些名词看到本质。
就像中台这个名词一样,它的本质就是企业级的复用,达到这个复用目的途径有千万种,只要达到这个目的他就是中台。
就像微服务这个名词一样,它的本质目的就是为了应对业务快速变化,而不得已地将服务做小。只要我们达到了应对业务快速变化这个目的,我们就成功了。而其中带来的所谓 配置中心、注册中心、熔断、分布式事务等等,他们是不得不引入的一些额外成本,而不是成果。
总结
中台是最近火起来的概念,但它只是新瓶装旧酒,本质是在企业层级进行复用的一个描述。
复用则是每一个程序员应有的觉悟,但规模是万恶之源,任何事情规模增大了,实施的难度都会急剧增加。
进行复用(或者说进行中台建设)并非没有代价,我们需要权衡复用的利弊后,才能做出正确的决策。
关于作者
在两家排名前三的股份制商业银行及互金创业公司工作过,目前在排名前二的互联网银行工作,做过业务,做过中间件,做过架构,也带过小团队。
欢迎加微信交流技术,请备注名字+公司。
公众号

微信
