Java学习篇之File类的判断功能在递归中的使用
在Java学习篇之IO流中的File类一文中涉及到了File类的一些功能的介绍,它的判断功能在对文件的操作过程中使用比较广泛,例如递归和过滤器的使用。
下面直接用相关的功能代码来进行体现,且这些代码在进行功能实现的过程中需要注意部分细节。先说明如何用递归的方式实现一个文件夹的删除吧,此处温馨提示:请自建测试文件夹进行删除测试,因为Java代码在进行删除测试的过程中是不走“回收站”的,删除有风险,运行需谨慎~
首先先展示一个个删除文件夹的代码:
//题目要求
/*
* 从键盘接收一个文件夹路径,删除该文件夹。
*/
import java.io.File;
import java.util.Scanner;
public class DemoDelete {
public static void main(String[] args) {
System.out.println("请输入要删除的文件夹路径:");
Scanner sc=new Scanner(System.in);
String str=sc.next();
//将输入的文件夹路径封装成一个File类对象
File file=new File(str);
//调用删除文件夹的方法,传入参数
deleteFile(file);
}
//删除文件夹,从里边向外删除
public static void deleteFile(File file){
File[] files=file.listFiles();
for (File f : files) {
//File类的判断功能,如果获取到的是一个文件夹
//就调用自身方法,继续深入“剖析”
if(f.isDirectory()){
//递归调用,方法继续进栈
deleteFile(f);
}else{
//如果得到的不是文件夹,就删除
f.delete();
}
}
//这句代码如果没有,最后为空的那个指定文件夹不能删除
file.delete();
}
}
上边的代码中关键之处在于要删除最后为空那个文件夹,即指定的那个文件夹,具体代码已用注释标明(这句代码的上边的代码都是在删除指定文件夹的内部文件夹或者文件,所以最后还剩下它这个“空架子”,需要做最后的清除)
接下来,要说说过滤器的使用,过滤,顾名思义,是“筛选”的意思,下面的例子就要结合递归调用,来体现过滤器在其中起到的作用。(PS:过滤器如果用不惯,可以用if...else...代替)
先自定义一个过滤器类,如下是写法一:
package FilterTest;
import java.io.File;
import java.io.FileFilter;
//定义过滤器,过滤出所有以java结尾的文件
public class MyJavaFilter implements FileFilter {
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".java");
}
}如下是写法二:
package FilterTest;
import java.io.File;
import java.io.FileFilter;
//定义过滤器,过滤出所有以java结尾的文件
public class MyJavaFilter implements FileFilter {
public boolean accept(File pathname) {
//判断获取的是文件夹,直接返回true,待递归调用的时候
//对获取到的内部文件夹 继续做深入的“剖析”。
if(pathname.isDirectory()){
return true;
}else{
return pathname.getName().toLowerCase().endsWith(".java");
}
}
}测试类的写法一样,如下:
package FilterTest;
import java.io.File;
/*
* 遍历目录,获取目录下的所有.java文件
* 遍历多级目录,方法递归实现
* 遍历的过程中,使用过滤器
*/
public class FilterDemo {
public static void main(String[] args) {
getAllJava(new File("F:\\测试文件夹"));
}
/*
* 定义方法,实现遍历指定目录
* 获取目录中所有的.java文件
*/
public static void getAllJava(File dir){
//调用File对象方法listFiles()获取,加入过滤器
File[] fileArr = dir.listFiles(new MyJavaFilter());
for(File f : fileArr){
//对f路径,判断是不是文件夹
if(f.isDirectory()){
//如果不是过滤出来的文件,而是文件夹,就递归进入文件夹遍历
getAllJava(f);
}else{
//如果是文件,就打印出来
System.out.println(f);
}
}
}
}
过滤器类写法一的运行结果:

过滤器类写法一的运行结果:

为什么会出现以上运行结果的差异呢?也许读者会说,File类的listFiles()方法读取到的就是指定的操作文件夹下的第一级文件和文件夹的数组,当然了,确实有这个原因。但是,如果过滤器在过滤的过程中,没有判断获取到的是不是文件夹(if(pathname.isDirectory())),只是返回满足要求的文件,那么遍历的结果就会有缺失。
通过调试我们可以知道,过滤器在被第一次调用的时候,过滤出来的也是第一级文件和文件夹,所以,我们可以认为他的“过滤结果”和File类的listFiles()方法的“获取结果”本质是一样的,就是只取出直接下一级,不在深入,除非有文件夹需要进行递归遍历操作。
写法一断点调试:
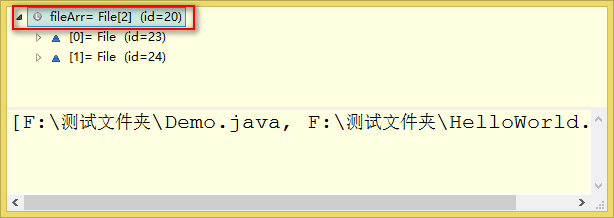
写法二断点调试:

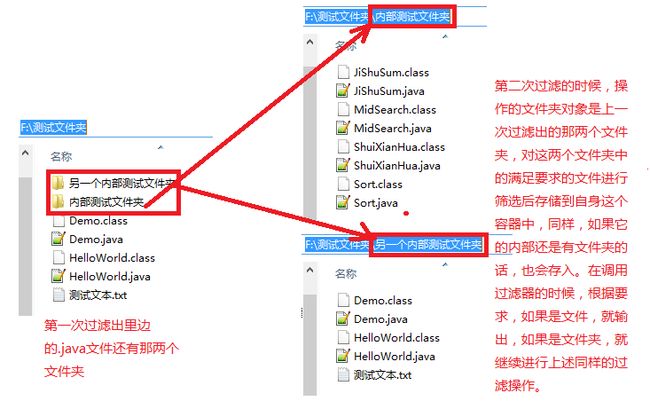
递归过程中,第二次调用迭代器MyJavaFilter对象,遍历“内部测试文件夹”:

通过以上运行结果,我们可以知道这两种过滤器写法的区别在哪里,说白了,就是“浅尝辄止”和“刨根问底”。通过我们建立的测试文件夹可以知道,若是按照第一种写法,过滤出来的只是指定文件下的第一级符合要求的文件,而不能对内部文件夹中的文件进行“深层次”过滤,所以,要想过滤出所有符合要求的文件,过滤器的写法需要采用第二种——必须判断筛选的是不是文件夹,以便存储后等待下一步遍历。
过滤器,从字面上来看,它是一个容器,不知可不可以这样理解它的本质。第一次调用它的时候,操作的文件夹是我们输入的那个文件夹对象,筛选出它下边的满足要求的文件,如果有文件夹,也筛选出来,作为下一次的筛选操作对象,以此类推……(下图是添加了一个新的子文件夹后的遍历顺序图)