1.前言
在互联网风控数据挖掘中,恶意用户可划分为个人恶意和群体恶意。
1.1 个人恶意
个人恶意行为可通过RFM来获取大部分对应恶意用户的特征:
- R:recently,交易时间间隔,比如可以取近一周、一个月、三个月、六个月、九个月等观察时窗。
- F:frequency,交易的次数,比如总的交易次数和恶意交易次数的联合分布等。
- M:monetary,交易的金额,可以结合交易的品类对金额进行调整,不能单看交易金额。
当然也可以根据不同的个人用户画像:
- 浏览行为画像:时间、设备、ip、渠道。
- 下单行为画像:商品信息、时间信息、设备、ip、地址、优惠券、支付方式等。
- 领劵行为:频次、使用周期。
- 注册信息画像:时间、设备、ip、渠道。
- 登录信息画像:时间、设备、ip、渠道。
需要注意的是,正常的用户一般都有固定的下单行为,比如常用的支付方式、常用的收货地址、常用的设备、常用的ip等,这些是很有用的特征。
1.2 群体恶意
特点:短期、快速、大量。目前成熟的电商,都不会允许一个账号短时间内下很多订单,现在的黑产为了能短期快速获利,一般会群控手机(使用软件控制几百甚至上千台手机),或者把漏洞发布到网上,造成大量用户下单。如何识别恶意群体:
- 首先是需要分析他们之间的关联规则,比如同一时间段内(一天、三天、一周等)同一促销活动、同一商品、同一门店、同一支付方式等,通过这些共同特征来识别恶意群体。
- 其次再通过支持度、置信度和提升度等指标来衡量,查看这些关联规则(上述同一XXX)效果如何。
- 最后可以通过Graph来构建社区(比如Louvian算法发现社区等)。
2.关联规则常用度量指标
2.1 基本概念
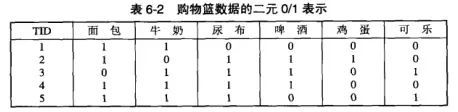
- 二元表示:如图所示,每一行对应一个事务(比如一个TID表示一个用户购物车中的所有商品),每一列表示一个项,它们分别用0、1表示。
- 项集(ItemSet):包含0个或多个项的集合,如果包含k个项,则称为k-项集。频繁项集指的是在所有的二元表中,组合出现的频次很高的某几个项(商品,也可以是一项),一般用于商品推荐(买了a商品和b商品,再买c商品,这三个商品组合出现的频率很高,因此用户买了a和b,推荐给用户c商品容易被购买)。
- 事务的宽度:事务中出现的项的个数。
示例:10000个超市订单(10000个事务),其中购买三元牛奶(A事务)的6000个,购买伊利牛奶(B事务)的7500个,4000个同时包含两者。
2.2 支持度
Support(支持度):表示同时包含A和B的事务占所有事务的比例。如果用P(A)表示使用A事务的比例。
公式表达:Support=P(A&B)。
通过以上示例:三元牛奶(A事务)和伊利牛奶(B事务)的支持度为:P(A&B)=4000/10000=0.4。
2.3 置信度
Confidence(可信度):表示使用包含A的事务中同时包含B事务的比例,即同时包含A和B的事务占包含A事务的比例。
公式表达:Confidence=P(A&B)/P(A)。
通过以上示例:
三元牛奶(A事务)对伊利牛奶(B事务)的置信度为:4000/6000=0.67,说明在购买三元牛奶后,有0.67的用户去购买伊利牛奶。
伊利牛奶(B事务)对三元牛奶(A事务)的提升度为:4000/7500=0.53,说明在购买三元牛奶后,有0.53的用户去购买伊利牛奶。
2.4 提升度
上面我们可以看到A事务对B事务的置信度为0.67,看似相当高,但是其实这是一个误导,为什么这么说?因为在没有任何条件下,B事务的出现的比例是0.75(7500/10000),而出现A事务,且同时出现B事务的比例是0.67,也就是说设置了A事务出现这个条件,B事务出现的比例反而降低了。这说明A事务和B事务是排斥的。
Lift(提升度):表示“包含A的事务中同时包含B事务的比例”与“包含B事务的比例”的比值。
公式表达:Lift=( P(A&B)/P(A))/P(B)=P(A&B)/P(A)/P(B)。
通过以上示例:
2.5 KULC
2.6 IR
公式表达:IR=P(B|A)/P(A|B)
假如在上例中6000个事务包含三元牛奶,75000个包含伊利牛奶,同时购买依旧为4000
则:
KULC=0.5*(4000/75000+4000/6000)=0.36
IR=4000/6000/(4000/75000)=12.5
这说明这两个事务的关联关系非常不平衡,购买三元牛奶的顾客很可能同时会买伊利牛奶,而购买了伊利牛奶的用户不太会再去买三元牛奶。很好理解,A对B的支持度远远高于B对A的支持度。