使用you-get批量下载B站视频
目录
准备工作
Step1:安装you-get;
Step2:找到要下载视频的源URL;
利用you-get下载需要的视频资源
方法1,使用命令行
方法2,创建bat批处理文件
方法3,创建python脚本文件
附:you-get --help
其它问题
准备工作
Step1:安装you-get;
方法,见 you-get中文说明。
Step2:找到要下载视频的源URL;
方法:点开视频网页,获取URL链接:https://www.bilibili.com/bangumi/play/ss2514/?from=search&seid=5912598083158202353
注:对于某些B站视频,若直接使用浏览器地址栏链接,you-get会提示:
you-get: [Error] Unsupported URL pattern.解决办法:
F12打开开发者调试工具,在查看器下找到
标签,找到类似如下语句:,使用此URL地址:https://www.bilibili.com/video/av00000000/。
利用you-get下载需要的视频资源
方法1,使用命令行
C:\Users\tojay>you-get --playlist -o E:\MyVedio https://www.bilibili.com/bangumi/play/ss2514/?from=search&seid=5912598083158202353开始愉快的下载...

方法2,创建bat批处理文件
新建txt文本文件,写入以下代码,命名保存为bl_download.txt,修改txt后缀为bat。
@echo off
for /f "delims=," %%i in (url_list.txt) do (
you-get -l -o E:\MyVedio %%i
)
pause注意:本地存储路径不能含有中文
新建txt文本文件,写入视频url,保存,命名为“url_list.txt”。
https://www.bilibili.com/video/av00000000,
https://www.bilibili.com/video/av11111111,
https://www.bilibili.com/video/av12222222,双击运行bl_download.bat文件即可开始下载任务。
开始愉快的下载...
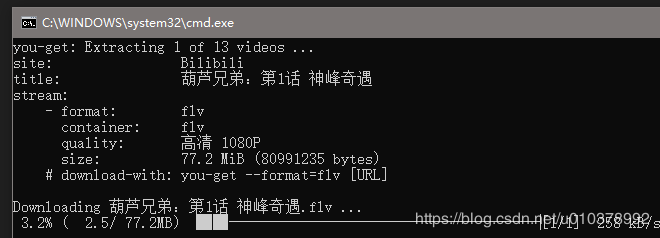
方法3,创建python脚本文件
import sys
from you_get import common as you_get #导入you-get库
#设置下载目录
directory = 'E:\MyVedio'
#设置要下载的视频地址
url = 'https://www.bilibili.com/bangumi/play/ss2514/?from=search&seid=5912598083158202353'
sys.argv = ['you-get', '-l', '-o', directory, url]
you_get.main()开始愉快的下载...

附:you-get --help
you-get: version 0.4.1355, a tiny downloader that scrapes the web.
usage: you-get [OPTION]... URL...
A tiny downloader that scrapes the web
optional arguments:
-V, --version Print version and exit
-h, --help Print this help message and exit
Dry-run options:
(no actual downloading)
-i, --info Print extracted information
-u, --url Print extracted information with URLs
--json Print extracted URLs in JSON format
Download options:
-n, --no-merge Do not merge video parts
--no-caption Do not download captions (subtitles, lyrics, danmaku,
...)
-f, --force Force overwriting existing files
--skip-existing-file-size-check
Skip existing file without checking file size
-F STREAM_ID, --format STREAM_ID
Set video format to STREAM_ID
-O FILE, --output-filename FILE
Set output filename
-o DIR, --output-dir DIR
Set output directory
-p PLAYER, --player PLAYER
Stream extracted URL to a PLAYER
-c COOKIES_FILE, --cookies COOKIES_FILE
Load cookies.txt or cookies.sqlite
-t SECONDS, --timeout SECONDS
Set socket timeout
-d, --debug Show traceback and other debug info
-I FILE, --input-file FILE
Read non-playlist URLs from FILE
-P PASSWORD, --password PASSWORD
Set video visit password to PASSWORD
-l, --playlist Prefer to download a playlist
-a, --auto-rename Auto rename same name different files
-k, --insecure ignore ssl errors
Proxy options:
-x HOST:PORT, --http-proxy HOST:PORT
Use an HTTP proxy for downloading
-y HOST:PORT, --extractor-proxy HOST:PORT
Use an HTTP proxy for extracting only
--no-proxy Never use a proxy
-s HOST:PORT, --socks-proxy HOST:PORT
Use an SOCKS5 proxy for downloading其它问题
本人写博客过程中,愉快的爬了B站100个左右的视频后,出现了以下错误:
you-get: [error] oops, something went wrong.
you-get: don't panic, c'est la vie. please try the following steps:
you-get: (1) Rule out any network problem.
you-get: (2) Make sure you-get is up-to-date.
you-get: (3) Check if the issue is already known, on
you-get: https://github.com/soimort/you-get/wiki/Known-Bugs
you-get: https://github.com/soimort/you-get/issues
you-get: (4) Run the command with '--debug' option,
you-get: and report this issue with the full output.通过you-get 的 --debug查看错误详情:
[DEBUG] get_content: https://www.bilibili.com/bangumi/play/ss2514/?from=search&seid=5912598083158202353
[DEBUG] HTTP Error with code403
[DEBUG] HTTP Error with code403
[DEBUG] HTTP Error with code403
华丽丽的被B站反爬了...
更换IP后可以继续,日后若能找到好的解决方法再回来更新吧!