从一个class文件深入理解Java字节码结构
前言
我们都知道,Java程序最终是转换成class文件执行在虚拟机上的,那么class文件是个怎样的结构,虚拟机又是如何处理去执行class文件里面的内容呢,这篇文章带你深入理解Java字节码中的结构。
1.Demo源码
首先,编写一个简单的Java源码:
package com.april.test;
public class Demo {
private int num = 1;
public int add() {
num = num + 2;
return num;
}
}
这段代码很简单,只有一个成员变量num和一个方法add()。
2.字节码
要运行一段Java源码,必须先将源码转换为class文件,class文件就是编译器编译之后供虚拟机解释执行的二进制字节码文件,可以通过IDE工具或者命令行去将源码编译成class文件。这里我们使用命令行去操作,运行下面命令:
javac Demo.java
就会生成一个Demo.class文件。
我们打开这个Demo.class文件看下。这里用到的是Notepad++,需要安装一个HEX-Editor插件。

3.class文件反编译java文件
在分析class文件之前,我们先来看下将这个Demo.class反编译回Demo.java的结果,如下图所示:
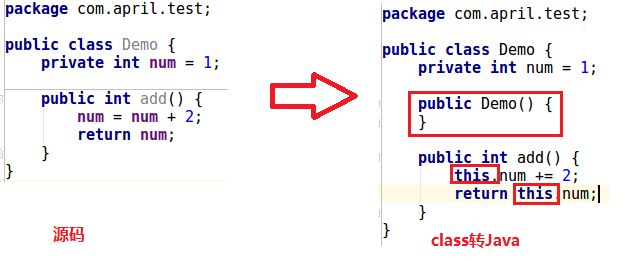
可以看到,回编译的源码比编写的代码多了一个空的构造函数和this关键字,为什么呢?先放下这个疑问,看完这篇分析,相信你就知道答案了。
4.字节码结构
从上面的字节码文件中我们可以看到,里面就是一堆的16进制字节。那么该如何解读呢?别急,我们先来看一张表:
| 类型 | 名称 | 说明 | 长度 |
|---|---|---|---|
| u4 | magic | 魔数,识别Class文件格式 | 4个字节 |
| u2 | minor_version | 副版本号 | 2个字节 |
| u2 | major_version | 主版本号 | 2个字节 |
| u2 | constant_pool_count | 常量池计算器 | 2个字节 |
| cp_info | constant_pool | 常量池 | n个字节 |
| u2 | access_flags | 访问标志 | 2个字节 |
| u2 | this_class | 类索引 | 2个字节 |
| u2 | super_class | 父类索引 | 2个字节 |
| u2 | interfaces_count | 接口计数器 | 2个字节 |
| u2 | interfaces | 接口索引集合 | 2个字节 |
| u2 | fields_count | 字段个数 | 2个字节 |
| field_info | fields | 字段集合 | n个字节 |
| u2 | methods_count | 方法计数器 | 2个字节 |
| method_info | methods | 方法集合 | n个字节 |
| u2 | attributes_count | 附加属性计数器 | 2个字节 |
| attribute_info | attributes | 附加属性集合 | n个字节 |
这是一张Java字节码总的结构表,我们按照上面的顺序逐一进行解读就可以了。
首先,我们来说明一下:class文件只有两种数据类型:无符号数和表。如下表所示:
| 数据类型 | 定义 | 说明 |
|---|---|---|
| 无符号数 | 无符号数可以用来描述数字、索引引用、数量值或按照utf-8编码构成的字符串值。 | 其中无符号数属于基本的数据类型。 以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节 |
| 表 | 表是由多个无符号数或其他表构成的复合数据结构。 | 所有的表都以“_info”结尾。 由于表没有固定长度,所以通常会在其前面加上个数说明。 |
实际上整个class文件就是一张表,其结构就是上面的表一了。
那么我们现在再来看表一中的类型那一列,也就很简单了:
| 类型 | 说明 | 长度 |
|---|---|---|
| u1 | 1个字节 | 1 |
| u2 | 2个字节 | 2 |
| u4 | 4个字节 | 4 |
| u8 | 8个字节 | 8 |
| cp_info | 常量表 | n |
| field_info | 字段表 | n |
| method_info | 方法表 | n |
| attribute_info | 属性表 | n |
上面各种具体的表的数据结构后面会详细说明,这里暂且不表。
好了,现在我们开始对那一堆的16进制进行解读。

4.1 魔数
从上面的总的结构图中可以看到,开头的4个字节表示的是魔数,其值为:

嗯,其值为0XCAFE BABE。CAFE BABE??What the fxxk?
好了,那么什么是魔数呢?魔数就是用来区分文件类型的一种标志,一般都是用文件的前几个字节来表示。比如0XCAFE BABE表示的是class文件,那么为什么不是用文件名后缀来进行判断呢?因为文件名后缀容易被修改啊,所以为了保证文件的安全性,将文件类型写在文件内部可以保证不被篡改。
再来说说为什么class文件用的是CAFE BABE呢,看到这个大概你就懂了。

4.2 版本号
紧跟着魔数后面的4位就是版本号了,同样也是4个字节,其中前2个字节表示副版本号,后2个字节
表示主版本号。再来看看我们Demo字节码中的值:

前面两个字节是0x0000,也就是其值为0;
后面两个字节是0x0034,也就是其值为52.
所以上面的代码就是52.0版本来编译的,也就是jdk1.8.0。
4.3 常量池
4.3.1 常量池容量计数器
接下来就是常量池了。由于常量池的数量不固定,时长时短,所以需要放置两个字节来表示常量池容量计数值。Demo的值为:

其值为0x0013,掐指一算,也就是19。
需要注意的是,这实际上只有18项常量。为什么呢?
通常我们写代码时都是从0开始的,但是这里的常量池却是从1开始,因为它把第0项常量空出来了。这是为了在于满足后面某些指向常量池的索引值的数据在特定情况下需要表达“不引用任何一个常量池项目”的含义,这种情况可用索引值0来表示。
Class文件中只有常量池的容量计数是从1开始的,对于其他集合类型,包括接口索引集合、字段表集合、方法表集合等的容量计数都与一般习惯相同,是从0开始的。
4.3.2 字面量和符号引用
在对这些常量解读前,我们需要搞清楚几个概念。
常量池主要存放两大类常量:字面量和符号引用。如下表:
| 常量 | 具体的常量 |
|---|---|
| 字面量 | 文本字符串 |
| 声明为final的常量值 | |
| 符号引用 | 类和接口的全限定名 |
| 字段的名称和描述符 | |
| 方法的名称和描述符 |
4.3.2.1 全限定名
com/april/test/Demo这个就是类的全限定名,仅仅是把包名的".“替换成”/",为了使连续的多个全限定名之间不产生混淆,在使用时最后一般会加入一个“;”表示全限定名结束。
4.3.2.2 简单名称
简单名称是指没有类型和参数修饰的方法或者字段名称,上面例子中的类的add()方法和num字段的简单名称分别是add和num。
4.3.2.3 描述符
描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,详见下表:
| 标志符 | 含义 |
|---|---|
| B | 基本数据类型byte |
| C | 基本数据类型char |
| D | 基本数据类型double |
| F | 基本数据类型float |
| I | 基本数据类型int |
| J | 基本数据类型long |
| S | 基本数据类型short |
| Z | 基本数据类型boolean |
| V | 基本数据类型void |
| L | 对象类型,如Ljava/lang/Object |
对于数组类型,每一维度将使用一个前置的[字符来描述,如一个定义为java.lang.String[][]类型的二维数组,将被记录为:[[Ljava/lang/String;,,一个整型数组int[]被记录为[I。
用描述符来描述方法时,按照先参数列表,后返回值的顺序描述,参数列表按照参数的严格顺序放在一组小括号“( )”之内。如方法java.lang.String toString()的描述符为( ) LJava/lang/String;,方法int abc(int[] x, int y)的描述符为([II) I。
4.3.3 常量类型和结构
常量池中的每一项都是一个表,其项目类型共有14种,如下表格所示:
| 类型 | 标志 | 描述 |
|---|---|---|
| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整形字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MothodType_info | 16 | 标志方法类型 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
这14种类型的结构各不相同,如下表格所示:
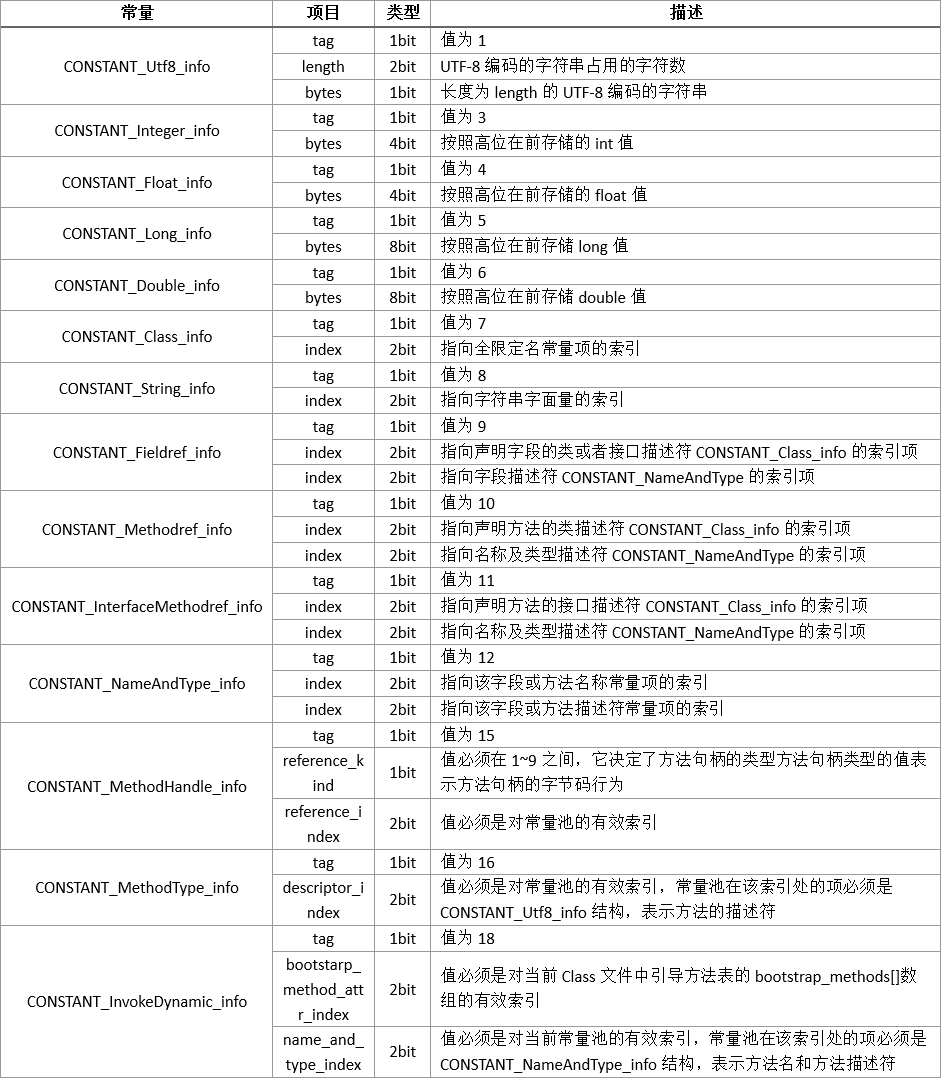
注:此表格的类型的单位不对,不是bit,应该是byte(字节)。后面的同理。
从上面的表格可以看到,虽然每一项的结构都各不相同,但是他们有个共同点,就是每一项的第一个字节都是一个标志位,标识这一项是哪种类型的常量。
4.3.4 常量解读
好了,我们进入这18项常量的解读,首先是第一个常量,看下它的标志位是啥:

其值为0x0a,即10,查上面的表格可知,其对应的项目类型为CONSTANT_Methodref_info,即类中方法的符号引用。其结构为:

即后面4个字节都是它的内容,分别为两个索引项:

其中前两位的值为0x0004,即4,指向常量池第4项的索引;
后两位的值为0x000f,即15,指向常量池第15项的索引。
至此,第一个常量就解读完毕了。
我们再来看下第二个常量:

其标志位的值为0x09,即9,查上面的表格可知,其对应的项目类型为CONSTANT_Fieldref_info,即字段的符号引用。其结构为:

同样也是4个字节,前后都是两个索引。分别指向第4项的索引和第10项的索引。
后面还有16项常量就不一一去解读了,因为整个常量池还是挺长的:

你看,这么长的一大段16进制,看的我都快瞎了:

实际上,我们只要敲一行简单的命令:
javap -verbose Demo.class
其中部分的输出结果为:
Constant pool:
#1 = Methodref #4.#15 // java/lang/Object."":()V
#2 = Fieldref #3.#16 // com/april/test/Demo.num:I
#3 = Class #17 // com/april/test/Demo
#4 = Class #18 // java/lang/Object
#5 = Utf8 num
#6 = Utf8 I
#7 = Utf8 <init>
#8 = Utf8 ()V
#9 = Utf8 Code
#10 = Utf8 LineNumberTable
#11 = Utf8 add
#12 = Utf8 ()I
#13 = Utf8 SourceFile
#14 = Utf8 Demo.java
#15 = NameAndType #7:#8 // "":()V
#16 = NameAndType #5:#6 // num:I
#17 = Utf8 com/april/test/Demo
#18 = Utf8 java/lang/Object
你看,一家大小,齐齐整整,全都出来了。
但是,通过我们手动去分析才知道这个结果是怎么出来的,要知其然知其所以然嘛~
4.4 访问标志
常量池后面就是访问标志,用两个字节来表示,其标识了类或者接口的访问信息,比如:该Class文件是类还是接口,是否被定义成public,是否是abstract,如果是类,是否被声明成final等等。各种访问标志如下所示:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 是否为Public类型 |
| ACC_FINAL | 0x0010 | 是否被声明为final,只有类可以设置 |
| ACC_SUPER | 0x0020 | 是否允许使用invokespecial字节码指令的新语义,JDK1.0.2之后编译出来的类的这个标志默认为真 |
| ACC_INTERFACE | 0x0200 | 标志这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 是否为abstract类型,对于接口或者抽象类来说,次标志值为真,其他类型为假 |
| ACC_SYNTHETIC | 0x1000 | 标志这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x2000 | 标志这是一个注解 |
| ACC_ENUM | x4000 | 标志这是一个枚举 |
再来看下我们Demo字节码中的值:
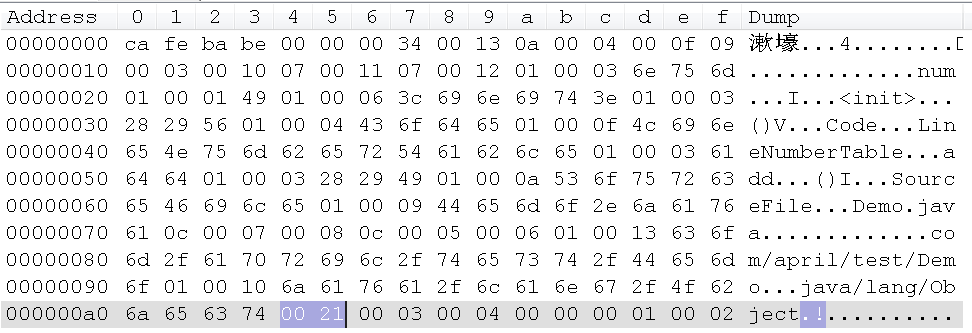
其值为:0x0021,是0x0020和0x0001的并集,即这是一个Public的类,再回头看看我们的源码。
确认过眼神,我遇上对的了。
4.5 类索引、父类索引、接口索引
访问标志后的两个字节就是类索引;
类索引后的两个字节就是父类索引;
父类索引后的两个字节则是接口索引计数器。
通过这三项,就可以确定了这个类的继承关系了。
4.5.1 类索引
我们直接来看下Demo字节码中的值:

类索引的值为0x0003,即为指向常量池中第三项的索引。你看,这里用到了常量池中的值了。
我们回头翻翻常量池中的第三项:
#3 = Class #17 // com/april/test/Demo
通过类索引我们可以确定到类的全限定名。
4.5.2 父类索引
从上图看到,父类索引的值为0x0004,即常量池中的第四项:
#4 = Class #18 // java/lang/Object
这样我们就可以确定到父类的全限定名。
可以看到,如果我们没有继承任何类,其默认继承的是java/lang/Object类。
同时,由于Java不支持多继承,所以其父类只有一个。
4.5.3 接口计数器
从上图看到,接口索引个数的值为0x0000,即没有任何接口索引,我们demo的源码也确实没有去实现任何接口。
4.5.4 接口索引集合
由于我们demo的源码没有去实现任何接口,所以接口索引集合就为空了,不占地方,嘻嘻。
可以看到,由于Java支持多接口,因此这里设计成了接口计数器和接口索引集合来实现。
4.6 字段表
接口计数器或接口索引集合后面就是字段表了。
字段表用来描述类或者接口中声明的变量。这里的字段包含了类级别变量以及实例变量,但是不包括方法内部声明的局部变量。
4.6.1 字段表计数器
同样,其前面两个字节用来表示字段表的容量,看下demo字节码中的值:
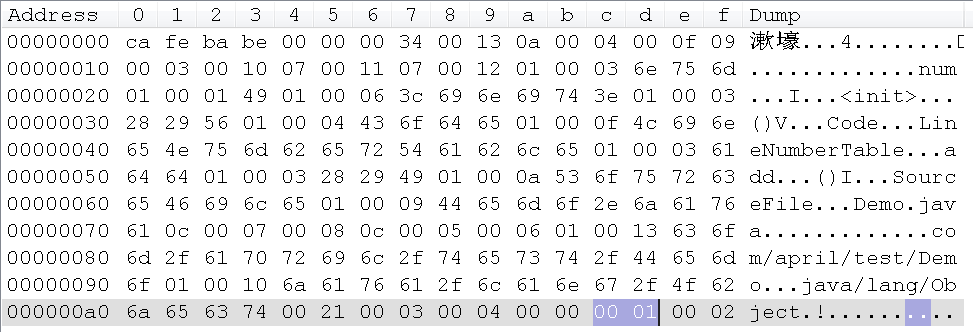
其值为0x0001,表示只有一个字段。
4.6.2 字段表访问标志
我们知道,一个字段可以被各种关键字去修饰,比如:作用域修饰符(public、private、protected)、static修饰符、final修饰符、volatile修饰符等等。因此,其可像类的访问标志那样,使用一些标志来标记字段。字段的访问标志有如下这些:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 字段是否为public |
| ACC_PRIVATE | 0x0002 | 字段是否为private |
| ACC_PROTECTED | 0x0004 | 字段是否为protected |
| ACC_STATIC | 0x0008 | 字段是否为static |
| ACC_FINAL | 0x0010 | 字段是否为final |
| ACC_VOLATILE | 0x0040 | 字段是否为volatile |
| ACC_TRANSTENT | 0x0080 | 字段是否为transient |
| ACC_SYNCHETIC | 0x1000 | 字段是否为由编译器自动产生 |
| ACC_ENUM | 0x4000 | 字段是否为enum |
4.6.3 字段表结构
字段表作为一个表,同样有他自己的结构:
| 类型 | 名称 | 含义 | 数量 |
|---|---|---|---|
| u2 | access_flags | 访问标志 | 1 |
| u2 | name_index | 字段名索引 | 1 |
| u2 | descriptor_index | 描述符索引 | 1 |
| u2 | attributes_count | 属性计数器 | 1 |
| attribute_info | attributes | 属性集合 | attributes_count |
4.6.4 字段表解读
我们先来回顾一下我们demo源码中的字段:
private int num = 1;
由于只有一个字段,还是比较简单的,直接看demo字节码中的值:

访问标志的值为0x0002,查询上面字段访问标志的表格,可得字段为private;
字段名索引的值为0x0005,查询常量池中的第5项,可得:
#5 = Utf8 num
描述符索引的值为0x0006,查询常量池中的第6项,可得:
#6 = Utf8 I
属性计数器的值为0x0000,即没有任何的属性。
确认过眼神,我遇上对的了。
至此,字段表解读完成。
4.6.5 注意事项
- 字段表集合中不会列出从父类或者父接口中继承而来的字段。
- 内部类中为了保持对外部类的访问性,会自动添加指向外部类实例的字段。
- 在Java语言中字段是无法重载的,两个字段的数据类型,修饰符不管是否相同,都必须使用不一样的名称,但是对于字节码来讲,如果两个字段的描述符不一致,那字段重名就是合法的.
4.7 方法表
字段表后就是方法表了。
4.7.1 方法表计数器
前面两个字节依然用来表示方法表的容量,看下demo字节码中的值:
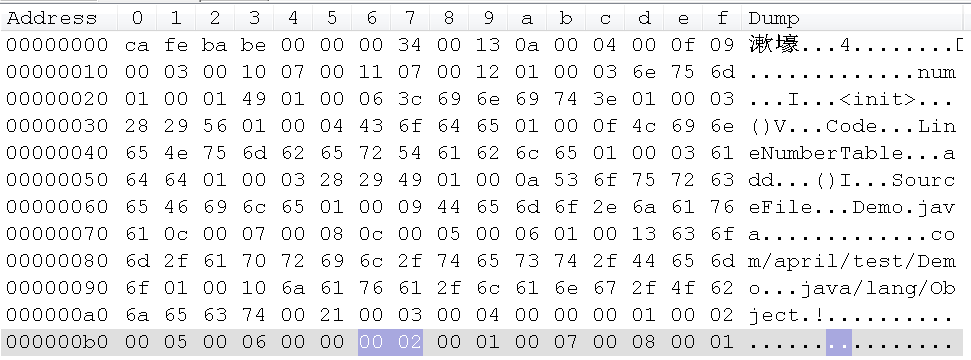
其值为0x0002,即有2个方法。
4.7.2 方法表访问标志
跟字段表一样,方法表也有访问标志,而且他们的标志有部分相同,部分则不同,方法表的具体访问标志如下:
| 标志名称 | 标志值 | 含义 |
|---|---|---|
| ACC_PUBLIC | 0x0001 | 方法是否为public |
| ACC_PRIVATE | 0x0002 | 方法是否为private |
| ACC_PROTECTED | 0x0004 | 方法是否为protected |
| ACC_STATIC | 0x0008 | 方法是否为static |
| ACC_FINAL | 0x0010 | 方法是否为final |
| ACC_SYHCHRONRIZED | 0x0020 | 方法是否为synchronized |
| ACC_BRIDGE | 0x0040 | 方法是否是有编译器产生的方法 |
| ACC_VARARGS | 0x0080 | 方法是否接受参数 |
| ACC_NATIVE | 0x0100 | 方法是否为native |
| ACC_ABSTRACT | 0x0400 | 方法是否为abstract |
| ACC_STRICTFP | 0x0800 | 方法是否为strictfp |
| ACC_SYNTHETIC | 0x1000 | 方法是否是有编译器自动产生的 |
4.7.3 方法表结构
方法表的结构实际跟字段表是一样的,方法表结构如下:
| 类型 | 名称 | 含义 | 数量 |
|---|---|---|---|
| u2 | access_flags | 访问标志 | 1 |
| u2 | name_index | 方法名索引 | 1 |
| u2 | descriptor_index | 描述符索引 | 1 |
| u2 | attributes_count | 属性计数器 | 1 |
| attribute_info | attributes | 属性集合 | attributes_count |
4.7.4 属性解读
还是先回顾一下Demo中的源码:
public int add() {
num = num + 2;
return num;
}
只有一个自定义的方法。但是上面方法表计数器明明是2个,这是为啥呢?
这是因为它包含了默认的构造方法,我们来看下下面的分析就懂了,先看下Demo字节码中的值:
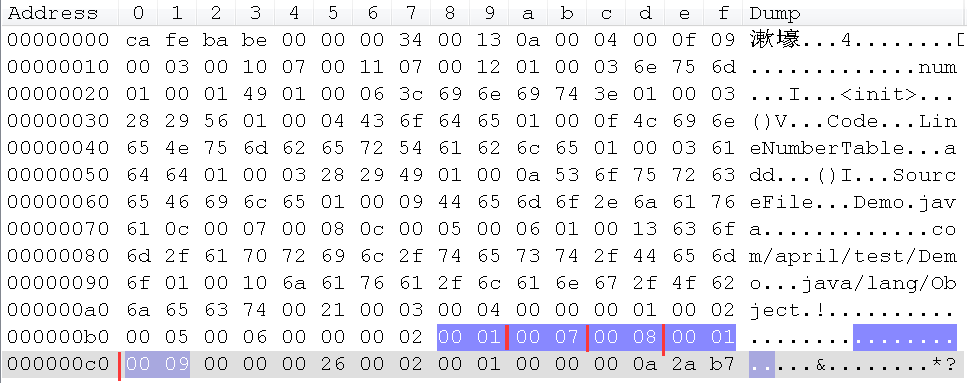
这是第一个方法表,我们来解读一下这里面的16进制:
访问标志的值为0x0001,查询上面字段访问标志的表格,可得字段为public;
方法名索引的值为0x0007,查询常量池中的第7项,可得:
#7 = Utf8 <init>
这个名为默认的构造方法了。
描述符索引的值为0x0008,查询常量池中的第8项,可得:
#8 = Utf8 ()V
注:描述符不熟悉的话可以回头看看4.3.2.3的内容。
属性计数器的值为0x0001,即这个方法表有一个属性。
属性计数器后面就是属性表了,由于只有一个属性,所以这里也只有一个属性表。
由于涉及到属性表,这里简单说下,下一节会详细介绍。
属性表的前两个字节是属性名称索引,这里的值为0x0009,查下常量池中的第9项:
#9 = Utf8 Code
即这是一个Code属性,我们方法里面的代码就是存放在这个Code属性里面。相关细节暂且不表。下一节会详细介绍Code属性。
先跳过属性表,我们再来看下第二个方法:

访问标志的值为0x0001,查询上面字段访问标志的表格,可得字段为public;
方法名索引的值为0x000b,查询常量池中的第11项,可得:
#11 = Utf8 add
描述符索引的值为0x000c,查询常量池中的第12项,可得:
#12 = Utf8 ()I
属性计数器的值为0x0001,即这个方法表有一个属性。
属性名称索引的值同样也是0x0009,即这是一个Code属性。
可以看到,第二个方法表就是我们自定义的add()方法了。
4.7.5 注意事项
- 如果父类方法在子类中没有被重写(
Override),方法表集合中就不会出现父类的方法。 - 编译器可能会自动添加方法,最典型的便是类构造方法(静态构造方法)
- 在Java语言中,要重载(
Overload)一个方法,除了要与原方法具有相同的简单名称之外,还要求必须拥有一个与原方法不同的特征签名,特征签名就是一个方法中各个参数在常量池中的字段符号引用的集合,也就是因为返回值不会包含在特征签名之中,因此Java语言里无法仅仅依靠返回值的不同来对一个已有方法进行重载。但在Class文件格式中,特征签名的范围更大一些,只要描述符不是完全一致的两个方法就可以共存。也就是说,如果两个方法有相同的名称和特征签名,但返回值不同,那么也是可以合法共存于同一个class文件中。
4.8 属性表
前面说到了属性表,现在来重点看下。属性表不仅在方法表有用到,字段表和Class文件中也会用得到。本篇文章中用到的例子在字段表中的属性个数为0,所以也没涉及到;在方法表中用到了2次,都是Code属性;至于Class文件,在末尾时会讲到,这里就先不说了。
4.8.1 属性类型
属性表实际上可以有很多类型,上面看到的Code属性只是其中一种,下面这些是虚拟机中预定义的属性:
| 属性名称 | 使用位置 | 含义 |
|---|---|---|
| Code | 方法表 | Java代码编译成的字节码指令 |
| ConstantValue | 字段表 | final关键字定义的常量池 |
| Deprecated | 类,方法,字段表 | 被声明为deprecated的方法和字段 |
| Exceptions | 方法表 | 方法抛出的异常 |
| EnclosingMethod | 类文件 | 仅当一个类为局部类或者匿名类是才能拥有这个属性,这个属性用于标识这个类所在的外围方法 |
| InnerClass | 类文件 | 内部类列表 |
| LineNumberTable | Code属性 | Java源码的行号与字节码指令的对应关系 |
| LocalVariableTable | Code属性 | 方法的局部变量描述 |
| StackMapTable | Code属性 | JDK1.6中新增的属性,供新的类型检查检验器检查和处理目标方法的局部变量和操作数有所需要的类是否匹配 |
| Signature | 类,方法表,字段表 | 用于支持泛型情况下的方法签名 |
| SourceFile | 类文件 | 记录源文件名称 |
| SourceDebugExtension | 类文件 | 用于存储额外的调试信息 |
| Synthetic | 类,方法表,字段表 | 标志方法或字段为编译器自动生成的 |
| LocalVariableTypeTable | 类 | 使用特征签名代替描述符,是为了引入泛型语法之后能描述泛型参数化类型而添加 |
| RuntimeVisibleAnnotations | 类,方法表,字段表 | 为动态注解提供支持 |
| RuntimeInvisibleAnnotations | 表,方法表,字段表 | 用于指明哪些注解是运行时不可见的 |
| RuntimeVisibleParameterAnnotation | 方法表 | 作用与RuntimeVisibleAnnotations属性类似,只不过作用对象为方法 |
| RuntimeInvisibleParameterAnnotation | 方法表 | 作用与RuntimeInvisibleAnnotations属性类似,作用对象哪个为方法参数 |
| AnnotationDefault | 方法表 | 用于记录注解类元素的默认值 |
| BootstrapMethods | 类文件 | 用于保存invokeddynamic指令引用的引导方式限定符 |
4.8.2 属性表结构
属性表的结构比较灵活,各种不同的属性只要满足以下结构即可:
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u2 | attribute_length | 1 | 属性长度 |
| u1 | info | attribute_length | 属性表 |
即只需说明属性的名称以及占用位数的长度即可,属性表具体的结构可以去自定义。
4.8.3 部分属性详解
下面针对部分常见的一些属性进行详解
4.8.3.1 Code属性
前面我们看到的属性表都是Code属性,我们这里重点来看下。
Code属性就是存放方法体里面的代码,像接口或者抽象方法,他们没有具体的方法体,因此也就不会有Code属性了。
4.8.3.1.1 Code属性表结构
先来看下Code属性表的结构,如下图:
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u2 | max_stack | 1 | 操作数栈深度的最大值 |
| u2 | max_locals | 1 | 局部变量表所需的存续空间 |
| u4 | code_length | 1 | 字节码指令的长度 |
| u1 | code | code_length | 存储字节码指令 |
| u2 | exception_table_length | 1 | 异常表长度 |
| exception_info | exception_table | exception_length | 异常表 |
| u2 | attributes_count | 1 | 属性集合计数器 |
| attribute_info | attributes | attributes_count | 属性集合 |
可以看到:Code属性表的前两项跟属性表是一致的,即Code属性表遵循属性表的结构,后面那些则是他自定义的结构。
4.8.3.1.2 Code属性解读
同样,解读Code属性只需按照上面的表格逐一解读即可。
我们先来看下第一个方法表中的Code属性:
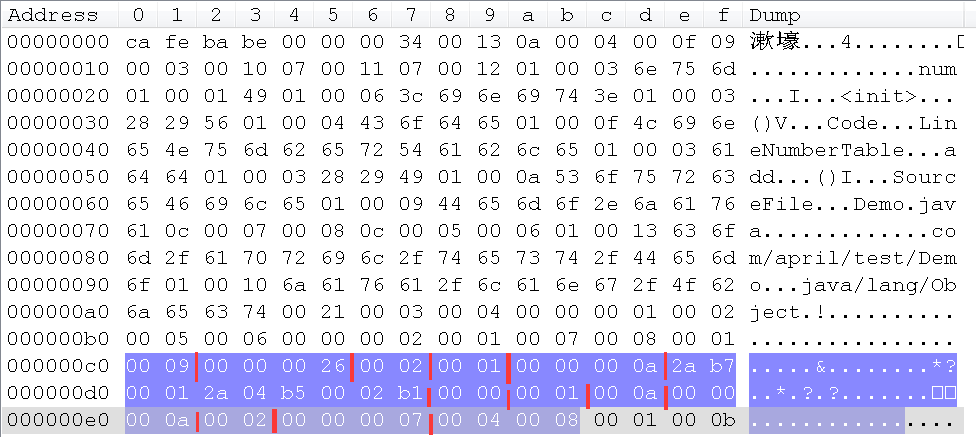
属性名索引的值为0x0009,上面也说过了,这是一个Code属性;
属性长度的值为0x00000026,即长度为38,注意,这里的长度是指后面自定义的属性长度,不包括属性名索引和属性长度这两个所占的长度,因为这哥俩占的长度都是固定6个字节了,所以往后38个字节都是Code属性的内容;
max_stack的值为0x0002,即操作数栈深度的最大值为2;
max_locals的值为0x0001,即局部变量表所需的存储空间为1;max_locals的单位是Slot,Slot是虚拟机为局部变量分配内存所使用的最小单位。
code_length的值为0x00000000a,即字节码指令的10;
code的值为0x2a b7 00 01 2a 04 b5 00 02 b1,这里的值就代表一系列的字节码指令。一个字节代表一个指令,一个指令可能有参数也可能没参数,如果有参数,则其后面字节码就是他的参数;如果没参数,后面的字节码就是下一条指令。
这里我们来解读一下这些指令,文末最后的附录附有Java虚拟机字节码指令表,可以通过指令表来查询指令的含义。
2a指令,查表可得指令为aload_0,其含义为:将第0个Slot中为reference类型的本地变量推送到操作数栈顶。b7指令,查表可得指令为invokespecial,其含义为:将操作数栈顶的reference类型的数据所指向的对象作为方法接受者,调用此对象的实例构造器方法、private方法或者它的父类的方法。其后面紧跟着的2个字节即指向其具体要调用的方法。00 01,指向常量池中的第1项,查询上面的常量池可得:#1 = Methodref #4.#15 // java/lang/Object."。即这是要调用默认构造方法":()V 。2a指令,同第1个。04指令,查表可得指令为iconst_1,其含义为:将int型常量值1推送至栈顶。b5指令,查表可得指令为putfield,其含义为:为指定的类的实例域赋值。其后的2个字节为要赋值的实例。00 02,指向常量池中的第2项,查询上面的常量池可得:#2 = Fieldref #3.#16 // com/april/test/Demo.num:I。即这里要将num这个字段赋值为1。b5指令,查表可得指令为return,其含义为:返回此方法,并且返回值为void。这条指令执行完后,当前的方法也就结束了。
所以,上面的指令简单点来说就是,调用默认的构造方法,并初始化num的值为1。
同时,可以看到,这些操作都是基于栈来完成的。
如果要逐字逐字的去查每一个指令的意思,那是相当的麻烦,大概要查到猴年马月吧。实际上,只要一行命令,就能将这样字节码转化为指令了,还是javap命令哈:
javap -verbose Demo.class
截取部分输出结果:
public com.april.test.Demo();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: invokespecial #1 // Method java/lang/Object."":()V
4: aload_0
5: iconst_1
6: putfield #2 // Field num:I
9: return
LineNumberTable:
line 7: 0
line 8: 4
看看,那是相当的简单。关于字节码指令,就到此为止了。继续往下看。
exception_table_length的值为0x0000,即异常表长度为0,所以其异常表也就没有了;
attributes_count的值为0x0001,即code属性表里面还有一个其他的属性表,后面就是这个其他属性的属性表了;
所有的属性都遵循属性表的结构,同样,这里的结构也不例外。
前两个字节为属性名索引,其值为0x000a,查看常量池中的第10项:
#10 = Utf8 LineNumberTable
即这是一个LineNumberTable属性。LineNumberTable属性先跳过,具体可以看下一小节。
再来看下第二个方法表中的的Code属性:

属性名索引的值同样为0x0009,所以,这也是一个Code属性;
属性长度的值为0x0000002b,即长度为43;
max_stack的值为0x0003,即操作数栈深度的最大值为3;
max_locals的值为0x0001,即局部变量表所需的存储空间为1;
code_length的值为0x00000000f,即字节码指令的15;
code的值为0x2a 2a b4 20 02 05 60 b5 20 02 2a b4 20 02 ac,使用javap命令,可得:
public int add();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=3, locals=1, args_size=1
0: aload_0
1: aload_0
2: getfield #2 // Field num:I
5: iconst_2
6: iadd
7: putfield #2 // Field num:I
10: aload_0
11: getfield #2 // Field num:I
14: ireturn
LineNumberTable:
line 11: 0
line 12: 10
可以看到,这就是我们自定义的add()方法;
exception_table_length的值为0x0000,即异常表长度为0,所以其异常表也没有;
attributes_count的值为0x0001,即code属性表里面还有一个其他的属性表;
属性名索引值为0x000a,即这同样也是一个LineNumberTable属性,LineNumberTable属性看下一小节。
4.8.3.2 LineNumberTable属性
LineNumberTable属性是用来描述Java源码行号与字节码行号之间的对应关系。
4.8.3.2.1 LineNumberTable属性表结构
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u2 | line_number_table_length | 1 | 行号表长度 |
| line_number_info | line_number_table | line_number_table_length | 行号表 |
line_number_info(行号表),其长度为4个字节,前两个为start_pc,即字节码行号;后两个为line_number,即Java源代码行号。
4.8.3.2.2 LineNumberTable属性解读
前面出现了两个LineNumberTable属性,先看第一个:

attributes_count的值为0x0001,即code属性表里面还有一个其他的属性表;
属性名索引值为0x000a,查看常量池中的第10项:
#10 = Utf8 LineNumberTable
即这是一个LineNumberTable属性。
attribute_length的值为0x00 00 00 0a,即其长度为10,后面10个字节的都是LineNumberTable属性的内容;
line_number_table_length的值为0x0002,即其行号表长度长度为2,即有两个行号表;
第一个行号表其值为0x00 00 00 07,即字节码第0行对应Java源码第7行;
第二个行号表其值为0x00 04 00 08,即字节码第4行对应Java源码第8行。
同样,使用javap命令也能看到:
LineNumberTable:
line 7: 0
line 8: 4
第二个LineNumberTable属性为:

这里就不逐一看了,同样使用javap命令可得:
LineNumberTable:
line 11: 0
line 12: 10
所以这些行号是有什么用呢?当程序抛出异常时,我们就可以看到报错的行号了,这利于我们debug;使用断点时,也是根据源码的行号来设置的。
4.8.3.2 SourceFile属性
前面将常量池、字段集合、方法集合等都解读完了。最终剩下的就是一些附加属性了。
先来看看剩余还未解读的字节码:

同样,前面2个字节表示附加属性计算器,其值为0x0001,即还有一个附加属性。
最后这一个属性就是SourceFile属性,即源码文件属性。
先来看看其结构:
4.8.3.2.1 SourceFile属性结构
| 类型 | 名称 | 数量 | 含义 |
|---|---|---|---|
| u2 | attribute_name_index | 1 | 属性名索引 |
| u4 | attribute_length | 1 | 属性长度 |
| u2 | sourcefile_index | 1 | 源码文件索引 |
可以看到,其长度总是固定的8个字节。
4.8.3.2.2 SourceFile属性解读
属性名索引的值为0x000d,即常量池中的第13项,查询可得:
#13 = Utf8 SourceFile
属性长度的值为0x00 00 00 02,即长度为2;
源码文件索引的值为0x000e,即常量池中的第14项,查询可得:
#14 = Utf8 Demo.java
所以,我们能够从这里知道,这个Class文件的源码文件名称为Demo.java。同样,当抛出异常时,可以通过这个属性定位到报错的文件。
至此,上面的字节码就完全解读完毕了。
4.8.4 其他属性
Java虚拟机中预定义的属性有20多个,这里就不一一介绍了,通过上面几个属性的介绍,只要领会其精髓,其他属性的解读也是易如反掌。
5.总结
通过手动去解读字节码文件,终于大概了解到其构成和原理了。断断续续写了比较长的时间,终于写完了,撒花~
实际上,我们可以使用各种工具来帮我们去解读字节码文件,而不用直接去看这些16进制,神烦啊,哈哈。溜了溜了。

6. 附录
6.1 Java虚拟机字节码指令表
| 字节码 | 助记符 | 指令含义 |
|---|---|---|
| 0x00 | nop | 什么都不做 |
| 0x01 | aconst_null | 将null推送至栈顶 |
| 0x02 | iconst_m1 | 将int型-1推送至栈顶 |
| 0x03 | iconst_0 | 将int型0推送至栈顶 |
| 0x04 | iconst_1 | 将int型1推送至栈顶 |
| 0x05 | iconst_2 | 将int型2推送至栈顶 |
| 0x06 | iconst_3 | 将int型3推送至栈顶 |
| 0x07 | iconst_4 | 将int型4推送至栈顶 |
| 0x08 | iconst_5 | 将int型5推送至栈顶 |
| 0x09 | lconst_0 | 将long型0推送至栈顶 |
| 0x0a | lconst_1 | 将long型1推送至栈顶 |
| 0x0b | fconst_0 | 将float型0推送至栈顶 |
| 0x0c | fconst_1 | 将float型1推送至栈顶 |
| 0x0d | fconst_2 | 将float型2推送至栈顶 |
| 0x0e | dconst_0 | 将do le型0推送至栈顶 |
| 0x0f | dconst_1 | 将do le型1推送至栈顶 |
| 0x10 | bipush | 将单字节的常量值(-128~127)推送至栈顶 |
| 0x11 | sipush | 将一个短整型常量值(-32768~32767)推送至栈顶 |
| 0x12 | ldc | 将int, float或String型常量值从常量池中推送至栈顶 |
| 0x13 | ldc_w | 将int, float或String型常量值从常量池中推送至栈顶(宽索引) |
| 0x14 | ldc2_w | 将long或do le型常量值从常量池中推送至栈顶(宽索引) |
| 0x15 | iload | 将指定的int型本地变量 |
| 0x16 | lload | 将指定的long型本地变量 |
| 0x17 | fload | 将指定的float型本地变量 |
| 0x18 | dload | 将指定的do le型本地变量 |
| 0x19 | aload | 将指定的引用类型本地变量 |
| 0x1a | iload_0 | 将第一个int型本地变量 |
| 0x1b | iload_1 | 将第二个int型本地变量 |
| 0x1c | iload_2 | 将第三个int型本地变量 |
| 0x1d | iload_3 | 将第四个int型本地变量 |
| 0x1e | lload_0 | 将第一个long型本地变量 |
| 0x1f | lload_1 | 将第二个long型本地变量 |
| 0x20 | lload_2 | 将第三个long型本地变量 |
| 0x21 | lload_3 | 将第四个long型本地变量 |
| 0x22 | fload_0 | 将第一个float型本地变量 |
| 0x23 | fload_1 | 将第二个float型本地变量 |
| 0x24 | fload_2 | 将第三个float型本地变量 |
| 0x25 | fload_3 | 将第四个float型本地变量 |
| 0x26 | dload_0 | 将第一个do le型本地变量 |
| 0x27 | dload_1 | 将第二个do le型本地变量 |
| 0x28 | dload_2 | 将第三个do le型本地变量 |
| 0x29 | dload_3 | 将第四个do le型本地变量 |
| 0x2a | aload_0 | 将第一个引用类型本地变量 |
| 0x2b | aload_1 | 将第二个引用类型本地变量 |
| 0x2c | aload_2 | 将第三个引用类型本地变量 |
| 0x2d | aload_3 | 将第四个引用类型本地变量 |
| 0x2e | iaload | 将int型数组指定索引的值推送至栈顶 |
| 0x2f | laload | 将long型数组指定索引的值推送至栈顶 |
| 0x30 | faload | 将float型数组指定索引的值推送至栈顶 |
| 0x31 | daload | 将do le型数组指定索引的值推送至栈顶 |
| 0x32 | aaload | 将引用型数组指定索引的值推送至栈顶 |
| 0x33 | baload | 将boolean或byte型数组指定索引的值推送至栈顶 |
| 0x34 | caload | 将char型数组指定索引的值推送至栈顶 |
| 0x35 | saload | 将short型数组指定索引的值推送至栈顶 |
| 0x36 | istore | 将栈顶int型数值存入指定本地变量 |
| 0x37 | lstore | 将栈顶long型数值存入指定本地变量 |
| 0x38 | fstore | 将栈顶float型数值存入指定本地变量 |
| 0x39 | dstore | 将栈顶do le型数值存入指定本地变量 |
| 0x3a | astore | 将栈顶引用型数值存入指定本地变量 |
| 0x3b | istore_0 | 将栈顶int型数值存入第一个本地变量 |
| 0x3c | istore_1 | 将栈顶int型数值存入第二个本地变量 |
| 0x3d | istore_2 | 将栈顶int型数值存入第三个本地变量 |
| 0x3e | istore_3 | 将栈顶int型数值存入第四个本地变量 |
| 0x3f | lstore_0 | 将栈顶long型数值存入第一个本地变量 |
| 0x40 | lstore_1 | 将栈顶long型数值存入第二个本地变量 |
| 0x41 | lstore_2 | 将栈顶long型数值存入第三个本地变量 |
| 0x42 | lstore_3 | 将栈顶long型数值存入第四个本地变量 |
| 0x43 | fstore_0 | 将栈顶float型数值存入第一个本地变量 |
| 0x44 | fstore_1 | 将栈顶float型数值存入第二个本地变量 |
| 0x45 | fstore_2 | 将栈顶float型数值存入第三个本地变量 |
| 0x46 | fstore_3 | 将栈顶float型数值存入第四个本地变量 |
| 0x47 | dstore_0 | 将栈顶do le型数值存入第一个本地变量 |
| 0x48 | dstore_1 | 将栈顶do le型数值存入第二个本地变量 |
| 0x49 | dstore_2 | 将栈顶do le型数值存入第三个本地变量 |
| 0x4a | dstore_3 | 将栈顶do le型数值存入第四个本地变量 |
| 0x4b | astore_0 | 将栈顶引用型数值存入第一个本地变量 |
| 0x4c | astore_1 | 将栈顶引用型数值存入第二个本地变量 |
| 0x4d | astore_2 | 将栈顶引用型数值存入第三个本地变量 |
| 0x4e | astore_3 | 将栈顶引用型数值存入第四个本地变量 |
| 0x4f | iastore | 将栈顶int型数值存入指定数组的指定索引位置 |
| 0x50 | lastore | 将栈顶long型数值存入指定数组的指定索引位置 |
| 0x51 | fastore | 将栈顶float型数值存入指定数组的指定索引位置 |
| 0x52 | dastore | 将栈顶do le型数值存入指定数组的指定索引位置 |
| 0x53 | aastore | 将栈顶引用型数值存入指定数组的指定索引位置 |
| 0x54 | bastore | 将栈顶boolean或byte型数值存入指定数组的指定索引位置 |
| 0x55 | castore | 将栈顶char型数值存入指定数组的指定索引位置 |
| 0x56 | sastore | 将栈顶short型数值存入指定数组的指定索引位置 |
| 0x57 | pop | 将栈顶数值弹出 (数值不能是long或do le类型的) |
| 0x58 | pop2 | 将栈顶的一个(long或do le类型的)或两个数值弹出(其它) |
| 0x59 | dup | 复制栈顶数值并将复制值压入栈顶 |
| 0x5a | dup_x1 | 复制栈顶数值并将两个复制值压入栈顶 |
| 0x5b | dup_x2 | 复制栈顶数值并将三个(或两个)复制值压入栈顶 |
| 0x5c | dup2 | 复制栈顶一个(long或do le类型的)或两个(其它)数值并将复制值压入栈顶 |
| 0x5d | dup2_x1 | dup_x1 指令的双倍版本 |
| 0x5e | dup2_x2 | dup_x2 指令的双倍版本 |
| 0x5f | swap | 将栈最顶端的两个数值互换(数值不能是long或do le类型的) |
| 0x60 | iadd | 将栈顶两int型数值相加并将结果压入栈顶 |
| 0x61 | ladd | 将栈顶两long型数值相加并将结果压入栈顶 |
| 0x62 | fadd | 将栈顶两float型数值相加并将结果压入栈顶 |
| 0x63 | dadd | 将栈顶两do le型数值相加并将结果压入栈顶 |
| 0x64 | is | 将栈顶两int型数值相减并将结果压入栈顶 |
| 0x65 | ls | 将栈顶两long型数值相减并将结果压入栈顶 |
| 0x66 | fs | 将栈顶两float型数值相减并将结果压入栈顶 |
| 0x67 | ds | 将栈顶两do le型数值相减并将结果压入栈顶 |
| 0x68 | imul | 将栈顶两int型数值相乘并将结果压入栈顶 |
| 0x69 | lmul | 将栈顶两long型数值相乘并将结果压入栈顶 |
| 0x6a | fmul | 将栈顶两float型数值相乘并将结果压入栈顶 |
| 0x6b | dmul | 将栈顶两do le型数值相乘并将结果压入栈顶 |
| 0x6c | idiv | 将栈顶两int型数值相除并将结果压入栈顶 |
| 0x6d | ldiv | 将栈顶两long型数值相除并将结果压入栈顶 |
| 0x6e | fdiv | 将栈顶两float型数值相除并将结果压入栈顶 |
| 0x6f | ddiv | 将栈顶两do le型数值相除并将结果压入栈顶 |
| 0x70 | irem | 将栈顶两int型数值作取模运算并将结果压入栈顶 |
| 0x71 | lrem | 将栈顶两long型数值作取模运算并将结果压入栈顶 |
| 0x72 | frem | 将栈顶两float型数值作取模运算并将结果压入栈顶 |
| 0x73 | drem | 将栈顶两do le型数值作取模运算并将结果压入栈顶 |
| 0x74 | ineg | 将栈顶int型数值取负并将结果压入栈顶 |
| 0x75 | lneg | 将栈顶long型数值取负并将结果压入栈顶 |
| 0x76 | fneg | 将栈顶float型数值取负并将结果压入栈顶 |
| 0x77 | dneg | 将栈顶do le型数值取负并将结果压入栈顶 |
| 0x78 | ishl | 将int型数值左移位指定位数并将结果压入栈顶 |
| 0x79 | lshl | 将long型数值左移位指定位数并将结果压入栈顶 |
| 0x7a | ishr | 将int型数值右(符号)移位指定位数并将结果压入栈顶 |
| 0x7b | lshr | 将long型数值右(符号)移位指定位数并将结果压入栈顶 |
| 0x7c | iushr | 将int型数值右(无符号)移位指定位数并将结果压入栈顶 |
| 0x7d | lushr | 将long型数值右(无符号)移位指定位数并将结果压入栈顶 |
| 0x7e | iand | 将栈顶两int型数值作“按位与”并将结果压入栈顶 |
| 0x7f | land | 将栈顶两long型数值作“按位与”并将结果压入栈顶 |
| 0x80 | ior | 将栈顶两int型数值作“按位或”并将结果压入栈顶 |
| 0x81 | lor | 将栈顶两long型数值作“按位或”并将结果压入栈顶 |
| 0x82 | ixor | 将栈顶两int型数值作“按位异或”并将结果压入栈顶 |
| 0x83 | lxor | 将栈顶两long型数值作“按位异或”并将结果压入栈顶 |
| 0x84 | iinc | 将指定int型变量增加指定值(i++, i–, i+=2) |
| 0x85 | i2l | 将栈顶int型数值强制转换成long型数值并将结果压入栈顶 |
| 0x86 | i2f | 将栈顶int型数值强制转换成float型数值并将结果压入栈顶 |
| 0x87 | i2d | 将栈顶int型数值强制转换成do le型数值并将结果压入栈顶 |
| 0x88 | l2i | 将栈顶long型数值强制转换成int型数值并将结果压入栈顶 |
| 0x89 | l2f | 将栈顶long型数值强制转换成float型数值并将结果压入栈顶 |
| 0x8a | l2d | 将栈顶long型数值强制转换成do le型数值并将结果压入栈顶 |
| 0x8b | f2i | 将栈顶float型数值强制转换成int型数值并将结果压入栈顶 |
| 0x8c | f2l | 将栈顶float型数值强制转换成long型数值并将结果压入栈顶 |
| 0x8d | f2d | 将栈顶float型数值强制转换成do le型数值并将结果压入栈顶 |
| 0x8e | d2i | 将栈顶do le型数值强制转换成int型数值并将结果压入栈顶 |
| 0x8f | d2l | 将栈顶do le型数值强制转换成long型数值并将结果压入栈顶 |
| 0x90 | d2f | 将栈顶do le型数值强制转换成float型数值并将结果压入栈顶 |
| 0x91 | i2b | 将栈顶int型数值强制转换成byte型数值并将结果压入栈顶 |
| 0x92 | i2c | 将栈顶int型数值强制转换成char型数值并将结果压入栈顶 |
| 0x93 | i2s | 将栈顶int型数值强制转换成short型数值并将结果压入栈顶 |
| 0x94 | lcmp | 比较栈顶两long型数值大小,并将结果(1,0,-1)压入栈顶 |
| 0x95 | fcmpl | 比较栈顶两float型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将-1压入栈顶 |
| 0x96 | fcmpg | 比较栈顶两float型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将1压入栈顶 |
| 0x97 | dcmpl | 比较栈顶两do le型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将-1压入栈顶 |
| 0x98 | dcmpg | 比较栈顶两do le型数值大小,并将结果(1,0,-1)压入栈顶;当其中一个数值为NaN时,将1压入栈顶 |
| 0x99 | ifeq | 当栈顶int型数值等于0时跳转 |
| 0x9a | ifne | 当栈顶int型数值不等于0时跳转 |
| 0x9b | iflt | 当栈顶int型数值小于0时跳转 |
| 0x9c | ifge | 当栈顶int型数值大于等于0时跳转 |
| 0x9d | ifgt | 当栈顶int型数值大于0时跳转 |
| 0x9e | ifle | 当栈顶int型数值小于等于0时跳转 |
| 0x9f | if_icmpeq | 比较栈顶两int型数值大小,当结果等于0时跳转 |
| 0xa0 | if_icmpne | 比较栈顶两int型数值大小,当结果不等于0时跳转 |
| 0xa1 | if_icmplt | 比较栈顶两int型数值大小,当结果小于0时跳转 |
| 0xa2 | if_icmpge | 比较栈顶两int型数值大小,当结果大于等于0时跳转 |
| 0xa3 | if_icmpgt | 比较栈顶两int型数值大小,当结果大于0时跳转 |
| 0xa4 | if_icmple | 比较栈顶两int型数值大小,当结果小于等于0时跳转 |
| 0xa5 | if_acmpeq | 比较栈顶两引用型数值,当结果相等时跳转 |
| 0xa6 | if_acmpne | 比较栈顶两引用型数值,当结果不相等时跳转 |
| 0xa7 | goto | 无条件跳转 |
| 0xa8 | jsr | 跳转至指定16位offset位置,并将jsr下一条指令地址压入栈顶 |
| 0xa9 | ret | 返回至本地变量 |
| 0xaa | tableswitch | 用于switch条件跳转,case值连续(可变长度指令) |
| 0xab | lookupswitch | 用于switch条件跳转,case值不连续(可变长度指令) |
| 0xac | ireturn | 从当前方法返回int |
| 0xad | lreturn | 从当前方法返回long |
| 0xae | freturn | 从当前方法返回float |
| 0xaf | dreturn | 从当前方法返回do le |
| 0xb0 | areturn | 从当前方法返回对象引用 |
| 0xb1 | return | 从当前方法返回void |
| 0xb2 | getstatic | 获取指定类的静态域,并将其值压入栈顶 |
| 0xb3 | putstatic | 为指定的类的静态域赋值 |
| 0xb4 | getfield | 获取指定类的实例域,并将其值压入栈顶 |
| 0xb5 | putfield | 为指定的类的实例域赋值 |
| 0xb6 | invokevirtual | 调用实例方法 |
| 0xb7 | invokespecial | 调用超类构造方法,实例初始化方法,私有方法 |
| 0xb8 | invokestatic | 调用静态方法 |
| 0xb9 | invokeinterface | 调用接口方法 |
| 0xba | – | 无此指令 |
| 0xbb | new | 创建一个对象,并将其引用值压入栈顶 |
| 0xbc | newarray | 创建一个指定原始类型(如int, float, char…)的数组,并将其引用值压入栈顶 |
| 0xbd | anewarray | 创建一个引用型(如类,接口,数组)的数组,并将其引用值压入栈顶 |
| 0xbe | arraylength | 获得数组的长度值并压入栈顶 |
| 0xbf | athrow | 将栈顶的异常抛出 |
| 0xc0 | checkcast | 检验类型转换,检验未通过将抛出ClassCastException |
| 0xc1 | instanceof | 检验对象是否是指定的类的实例,如果是将1压入栈顶,否则将0压入栈顶 |
| 0xc2 | monitorenter | 获得对象的锁,用于同步方法或同步块 |
| 0xc3 | monitorexit | 释放对象的锁,用于同步方法或同步块 |
| 0xc4 | wide | <待补充> |
| 0xc5 | multianewarray | 创建指定类型和指定维度的多维数组(执行该指令时,操作栈中必须包含各维度的长度值),并将其引用值压入栈顶 |
| 0xc6 | ifnull | 为null时跳转 |
| 0xc7 | ifnonnull | 不为null时跳转 |
| 0xc8 | goto_w | 无条件跳转(宽索引) |
| 0xc9 | jsr_w | 跳转至指定32位offset位置,并将jsr_w下一条指令地址压入栈顶 |