Redis(入门笔记)
- 学习一个大的技术点,然后顺带着就把这个技术点的面试题给学习了。
- 学习完一个技术后,如果面试题还不能够解答的话,只能说明学的不精,需要查漏补缺。
- 下一个学习的方向:Redis-非关系型数据库。
为什么学习Redis?因为我没有学过,我的技能里边缺少这个技能,并且到处都是Redis相关的面试题,并且在日常工作中,数据库也是经常使用的。分析了一下,就来学习了。至于看什么资料学习,去哪里学习,什么状态下学习,我都会在这里记录下来,相信以后看到这里的时候能够更快更高效的回忆起这个技术的学习过程。当然这也是我们的学习方法。输入加输出。
2020年03月04日06:39:22 。 昨天记录的上方部分,然后就开始去工作了。今天已经读书两个小时,开始学习喽。first, i need to found redis guide . go .
筛选了三个觉得可以学习的地方:
- redis官网: https://redis.io/ http://try.redis.io/ (It is ok . recommend)
- 菜鸟教程中的Redis介绍 : https://www.runoob.com/redis/redis-tutorial.html
- bilibili中的Redis培训的视频: https://space.bilibili.com/329325318/favlist?fid=793600718&ftype=create(下次尽量的先不寻找视频教学的内容。因为一个技术的视频最少也要10个小时以上。)
资源有了,接下来我要怎么学呢?
首先要了解Redis是什么,其次Redis用在哪些场合,最后学习Redis具体怎么用。
介绍(Redis是什么)
Redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes with radius queries and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
Redis是一个开放源代码(BSD许可)的内存中数据结构存储,用作数据库,缓存和消息代理。 它支持数据结构,例如字符串,哈希,列表,集合,带范围查询的排序集合,位图,超日志,带有半径查询和流的地理空间索引。 Redis具有内置的复制,Lua脚本,LRU逐出,事务和不同级别的磁盘持久性,并通过Redis Sentinel和Redis Cluster自动分区提供高可用性。
You can run atomic operations on these types, like appending to a string; incrementing the value in a hash; pushing an element to a list; computing set intersection, union and difference; or getting the member with highest ranking in a sorted set.
您可以在这些类型上运行原子操作,例如追加到字符串。 在哈希中增加值; 将元素推送到列表; 计算集的交集,并集和差; 或在排序集中获得排名最高的成员。
In order to achieve its outstanding performance, Redis works with an in-memory dataset. Depending on your use case, you can persist it either by dumping the dataset to disk every once in a while, or by appending each command to a log. Persistence can be optionally disabled, if you just need a feature-rich, networked, in-memory cache.
为了获得出色的性能,Redis使用内存中的数据集。 根据您的用例,您可以通过将数据集偶尔转储到磁盘上,或者通过将每个命令附加到日志中来持久化它。 如果只需要功能丰富的网络内存缓存,则可以选择禁用持久性。
Redis also supports trivial-to-setup master-slave asynchronous replication, with very fast non-blocking first synchronization, auto-reconnection with partial resynchronization on net split.
Redis还支持琐碎的设置主从异步复制,具有非常快速的非阻塞首次同步,以及在网络拆分时具有部分重新同步的自动重新连接。
基本的数据结构,例如以下几种:
- String: 字符串
- Hash: 散列
- List: 列表
- Set: 集合
- Sorted Set: 有序集合
Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库。
Redis 与其他 key - value 缓存产品有以下三个特点:
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis 优势
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis与其他key-value存储有什么不同?
- Redis有着更为复杂的数据结构并且提供对他们的原子性操作,这是一个不同于其他数据库的进化路径。Redis的数据类型都是基于基本数据结构的同时对程序员透明,无需进行额外的抽象。
- Redis运行在内存中但是可以持久化到磁盘,所以在对不同数据集进行高速读写时需要权衡内存,因为数据量不能大于硬件内存。在内存数据库方面的另一个优点是,相比在磁盘上相同的复杂的数据结构,在内存中操作起来非常简单,这样Redis可以做很多内部复杂性很强的事情。同时,在磁盘格式方面他们是紧凑的以追加的方式产生的,因为他们并不需要进行随机访问。
下载安装
Mac环境下:
➜ ~ brew install redis
安装成功,检测一下。
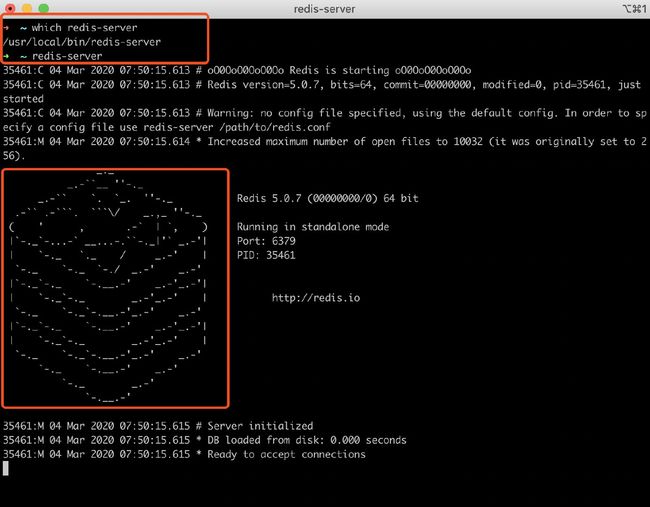
新打开一个窗口。 > redis-cli 进入到redis客户端。
刷一些关于Redis的博客先
先初步认识一下,大家的笔记都着重在哪个地方,Redis整体的内容都有哪些。哪些需要着重学习的。
- https://www.cnblogs.com/CodeBear/p/12402932.html
- https://zhuanlan.zhihu.com/p/37055648
- https://github.com/Snailclimb/JavaGuide/blob/master/docs/database/Redis/Redis.md#redis-%E7%AE%80%E4%BB%8B
- https://blog.csdn.net/bernkafly/article/details/89553711
关于hash
Hash表就是一个数组,而这个数组的元素,是一个链表
链表越长,Hash表的查询、插入、删除等操作的性能都会下降,极端情况下,如果全部元素都放到了一个链表里头,复杂度就会降为O(n),也就和顺序查找算法无异了。(正因如此,Java8里头的HashMap在元素增长到一定程度时会从链表转成一颗红黑树,来减缓查找性能的下降)
博客刷出来的重点关键词:
-
5种数据类型: String , list , hash , set , zset
-
二进制安全:只会严格按照二进制的数据存取。存取的永远是字节数组。在Redis里面是不可能存中文的,我们之所以在程序里面可以轻轻松松的拿到中文,只是因为API做了解码的操作。
-
因为我们的Xshell客户端使用的是UTF-8,在UTF-8下,一个中文通常是三个字节,两个中文就是6个字节,所以在Redis内部"hello中国"占了5+6=11个字节。
-
incr 自增。 decr 自减命令。 只能操作integer类型的数据。
-
可是所有的数字如果用type命令来查看的话, 也是string类型的,为什么也可以进行自增自减的操作呢?原来Redis的内部还会为每个key打上一个标记,来标记它是什么类型的(这个类型可和Redis的五种数据类型不一样哦)。 查看内部类型的命令为: Obejct encoding key
-
bitmap : String就很好的支持了bitmap,提供了一系列bitmap的命令 : setbit codeear 3 1
-
strlen codebear : 查看key 的长度
-
看了那么多的例子,大家有没有发现一个问题,所有的运算都在Redis内部完成,对于这种情况,有一个很高大上的名词:计算向数据移动。与之相对的,把数据从某个地方取出来,然后在外部计算,就叫数据向计算移动。
-
Redis的list底层是一个双向链表
-
list的简单命令介绍:
lpush codebear a b c d e前面的l代表左边,lpush就是在左边推,这样第一个推进去的,就是在最右边rpush codebear z: 往右边推。lpop codebear: 弹出命令。 左边弹出一个。rpop codebear: 弹出命令。右边弹出一个。lrange codebear 0 -1: lrange是从左开始指定索引范围内的数据,后面的-1就是代表拿到最后一个为止ltrim codebear 1 -1:它是保留索引范围之内的数据,删除索引范围之外的数据. -
如果我们使用lpush,rpop或者rpush,lpop这样的组合,就是先进先出,就是队列了;如果我们使用lpush,lpop或者rpush,rpop这样的组合,就是先进后出,就是栈了,所以Redis还可以作为消息队列来使用,用到的就是list这个数据类型了。
-
Hash的简单命令介绍:
hset codeber name codebear : 存储对象的名字
hset codebear age 18 : 存储对象的年龄
hincrby codebear age 2 : 给对象的年龄加2
...
hget codeber name : 获取对象的名字
hgetall
-
set的基本用法: 无序的
sadd codebear 6 1 2 3 3 8 6 : 给set赋值
smembers codebear : 查看set的值
srandmember codebear 2 : 从set集合中随机取出两个不重复的值。
srandmember codebear -2 : 从set集合中随机取出两个可以重复的值
srandmember: 参数的值如果大于set元素个数,如10,则取出全部元素。-10,则取出多个重复元素。
我们做抽奖系统,就可以用到这个命令了,如果可以重复中奖,后面带着负数,如果不能重复中奖,后面带着正数。
set还可以计算差集、并集、交集:
sunion codebear1 codebear2 差集
sdiff codebear1 codebear2 并集
sinter codebear1 codebear2 交集
-
zset的基本用法: 有序的。每个元素都有一个score的概念,score越小排在越前面
zadd codebear 1 hello 3 world 2 tree : 给zset赋值
zrange codebear 0 -1 withscores :取出结果。如果后面跟着withscores,就会把scores一起取出来
zrank codebear tree : 查看元素在集合中的排名 。 (索引值从0开始的)
zscore codebear tree : 查看元素的score
zrevrange codebear 0 1 : 取出从大到小的前两个
-
Redis中的zset是用什么实现的?跳表。为什么要用跳表实现呢,是因为跳表的特性:读写均衡。
Redis-key/value
在看Value操作之前,先看一看Key的操作
keys * 查询当前库的所有键
exists 判断某个键是否存在
type 查看键的类型
del 删除某个键
expire 为键值设置过期时间,单位秒。
ttl 查看还有多少秒过期,-1表示永不过期 (-2表示已过期)
dbsize 查看当前数据库的key的数量
Flushdb 清空当前库(慎用!)
Flushall 通杀全部库(删库跑路!!!忘了这个命令吧)
关于Redis五大数据类型
https://blog.csdn.net/bernkafly/article/details/89553711
Redis为什么那么快?
- 编程语言: Redis使用C语言编写的,更接近底层,可以直接调用OS函数
- 基于内存:Redis的数据都是放在内存的,所以更快。
- 单线程: Redis是单线程的,避免了线程切换的消耗,也不会有竞争,所以更快。
- 网络模型:Redis的网络模型是epoll,是多路复用的网络模型。
- Redis数据结构的优化:Redis中提供了5种数据类型,其中zset用跳表做了优化,而Redis整个其实也都使用hash做了优化,使其的时间成本是O(1),查找更快。
- Redis6.0推出了I/O Threads ,所以更快。
Redis有什么缺点
这就是一个开放式的问题了,有很多答案,比如:
- 因为Redis是单线程的,所以无法发挥出多核CPU的优势
- 因为Redis是单线程的,一旦执行了一个复杂的命令,后面所有的命令都被堵在门外。
- 无法做到对hash中的某一项添加过期时间。
Redis为什么可以保证原子性。
因为Redis是单线程的,所以同时只能处理一个读写请求,所以可以保证原子性。
Redis是单线程的,到底该如何解释
我们一直在强调Redis是单线程的,Redis是单线程的,但是Redis真的完全是单线程的吗?其实不然,我们说的Redis是单线程的,只是说Redis的读写是单线程的,也就是work thread只有一个。
什么是I/O Threads
I/O Threads是Redis 6.0推出的新特性,在以前Redis从socket拿到请求、处理、把结果写到socket是串行化的,即:

而Redis6.0推出了I/O Threads后:
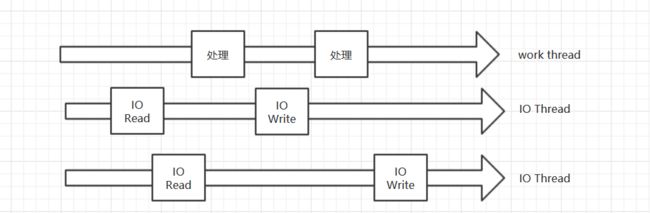
可以看到I/O Thread有多个,I/O Thread负责从socket读数据和写数据到socket,work thread在处理数据的同时,其他I/O Thread可以再从socke读数据,先准备好,等work thread忙完手中的事情了,立马可以处理下个请求。
但是work thread只有一个,这点要牢记。
什么是epoll?
我也不知道,看看别人的介绍吧,先不着急记录。
epoll到底是个什么鬼呢,说的简单点,就是告诉内核我对哪些事件感兴趣,内核就会帮你监听,当发生了你感兴趣的事件后,内核就会主动通知你。
这有什么优点呢:
- 减少用户态和内核态的切换。
- 基于事件就绪通知方式:内核主动通知你,不牢你费心去轮询、去判断。
- 文件描述符几乎没有上限:你想和几个客户端交互就和几个客户端交互,一个线程可以监听N个客户端,并且完成交互。
epoll函数是基于OS的,在windows里面,没有epoll这东西。
Redis的过期策略
一般来说,常用的过期策略有三种:
- 定时删除:需要给每个key添加一个定时器,一到期就溢出数据。优点是非常精确,缺点是消耗比较大。
- 定期删除:每隔一段时间,就会扫描一定数量的key,发现过期的,就移除数据。优点是消耗比较小,缺点是过期的key无法被及时移除。
- 懒删除:使用某个key的时候,先判断下这个key是否过期,过期则删除。优点是消耗小,缺点是过期的key无法被及时删除,只有使用到了,才会被移除。
Redis使用的是定期删除+懒删除的策略。
Redis 内存淘汰机制
MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据
redis 提供 6种数据淘汰策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
4.0版本后增加以下两种:
- volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
- allkeys-lfu:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
关于缓存雪崩和缓存穿透
什么是缓存雪崩?
缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉
解决方法?
- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
什么是缓存穿透?
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
解决方法:
1、做好参数校验。
如果用 Java 代码展示的话,差不多是下面这样的:
public Object getObjectInclNullById(Integer id) {
// 从缓存中获取数据
Object cacheValue = cache.get(id);
// 缓存为空
if (cacheValue == null) {
// 从数据库中获取
Object storageValue = storage.get(key);
// 缓存空对象
cache.set(key, storageValue);
// 如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
// 必须设置过期时间,否则有被攻击的风险
cache.expire(key, 60 * 5);
}
return storageValue;
}
return cacheValue;
}
2、布隆过滤器
布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程
如何保证缓存与数据库 双写时的数据一致性?
https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
Redis的持久化
(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
https://github.com/Snailclimb/JavaGuide/blob/master/docs/database/Redis/Redis%E6%8C%81%E4%B9%85%E5%8C%96.md
Redis事务
Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。(这也就验证了Redis的读写是单线程的概述。)
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
补充内容:
- redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。(来自issue:关于Redis事务不是原子性问题 )
通过Java使用Redis
https://blog.csdn.net/lixiaoxiong55/article/details/81592800
根据视频教程的学习笔记
学习目录
- Redis的安装
- Redis核心配置文件Redis.conf讲解文件
- docker安装Redis
- Redis常用数据类型及应用场景
- 其他功能
- Redis订阅发布
- Redis事务
- Redis数据淘汰策略
- Redis持久化
- Redis缓存与数据库同步
- 使用kafka作为异步队列
- Redis知识点总结:缓存穿透,缓存雪崩,热点key等处理方案(双重锁的使用)
- Redis高级应用
- Redis5版本集群搭建
- Java客户端远程连接Rediscluster实现应用
- springboot2整合rediscluster
redis的简介与安装
简介
Redis是完全开源免费的,遵守BSD协议,是一个高性能(NoSQL)key-value数据库。
NoSQL:泛指非关系型数据库,数据与数据之间没有关联关系。nosql数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。减轻数据库的压力
SQL:关系型数据库:表与表之间建立关联关系
MongoDB:文档型数据库。
图形数据库:Neo4J
NoSQL数据库试用的情况:
- 数据模型比较简单
- 需要灵活性更强的IT系统
- 对数据库性能要求比较高
- 不需要高度的数据一致性
- 对于给定key,比较容易映射复杂值的环境。
Redis的特点:
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
Redis总结:
- Redis单个key存入512M大小
企业级开发中:可以用作数据库、缓存(热点数据)和消息中间件等大部分功能
安装:
一般安装在Linux环境中。需要提前安装gcc
redis.config 配置:
redis-server redis.config .这样才能使用配置过的config
如果设置了密码: redis-cli -a 密码
bind : 绑定的主机地址。
daemonize : 是否以守护进行进行访问。 No/改为yes
pidfile:pid
port :6379 端口号
Timeout 300 。
loglevel verbose: 日志级别
save :指定在多长时间内,有多少次更新操作,执行一次持久化。
dbfilename dump.rdb : 指定数据库的文件名。默认值为dump.rdb
requirepass foobared : 设置默认密码。默认关闭。
maxmemor : Redis最大内存限制。//建议和自己服务器作对比。
Redis作为优秀的中间缓存建,时常会存储大量的数据,应该及时整理内存,不然很快就被占满。
1.为数据设置超时时间
2.采用LRU算法动态删除不用的数据


Redis关闭:
- 非正常关闭方式:(断电、非正常、杀死线程,容易丢失数据)、
- 正常关闭 : shutdown
Redis常用命令
redis 支持的五种数据类型: string ,list , set, zset , hash
Redis的key-公共命令
- del key : 删除一个key
- keys * : 查看所有的key
- DUMP key : 查看key的序列化的值
- EXISTS key : 判断key是否存在
- ttl key : 查看key的过期时间。 -1 代表永久有效。-2 代表无效。
- pttl key : 以毫秒为单位查看过期时间
- expire key 10 : 设置过期时间10秒
- pexpire key 1000 : 设置过期时间1000毫秒。
- Persist key : 移除key的过期时间
- Keys pattern: 以通配符查找key. * 查找所有。 ?代表一个字符。 可以组合使用
- Random key : 随机返回一个key
- select 1 : 切换到第一个数据库 。默认一共有16个数据库。编号为0-15
- rename key newname : 修改key 的名字。
- move key db : 移动key到指定的数据库中
- type key : 查看key的类型
expire key seconds 的应用场景:设置过期时间
- 限时的优惠活动信息
- 网站数据缓存(对于一些需要顶事更新的数据,例如:积分排行榜)
- 手机验证码。(一分钟内有效)
- 限制网站访问频率(一小时内密码错误三次)
key 的命名规范:
- key不要太长,尽量不要超过1024字节,这不仅消耗内存,而且会降低查询效率
- key也不要太短,可读性会降低: a b c
- 在一个项目中,key最好使用同一的命名模式:例如:user:123:password (可以使用数据库的主键)
- key的名称区分大小写
Redis的数据类型
1. String
二进制安全:只会严格按照二进制的数据存取。存取的永远是字节数组。在Redis里面是不可能存中文的,我们之所以在程序里面可以轻轻松松的拿到中文,只是因为API做了解码的操作。
二进制安全的特点:
- 编码。解码。发生在客户端完成,执行效率高
- 不需要频繁的编解码,不会出现乱码
String是Redis最基本的数据类型,一个键最大能存储512M
String的常用命令:
1. set keyname value : 赋值语法,重复赋值会覆盖原来的值。
2. get keyname : 取值。
3. setnx key value : 只有在key不存在时,为key设置值 //解决分布锁方案之一
4. getrange key stard end : 用于获取存储在执行key中的子字符串,类似于字符串截取。
5. getset a 123 : 设置新值,返回旧值。
6. strlen key : 查看长度
7. incr key : 自增。 如果key不存在,先初始化为0,然后加一
incrby key 10 : 自增10
8. decr key : 自减。
decr key 10: 自减10
String应用场景
1. String通常用于保存单个字符串或者JSON字符串数据
2. 可以把一个图片文件内容作为字符串来存储
3. 计数器(常用的key-value缓存应用,常规计数,微博数,点击数) , incr
2. Hash
Redis hash 特别适合存储对象。
hash常用命令:
1. hset key field value : 赋值操作
2. hget key field : 获取值。
3. hmset key field value [field value ...]: 一次存入一个对象。
4. hmget key field [field] : 一次查看多个属性
5. hgetall key : 一次查看一个对象的所有属性
6. Hkeys key : 获取key的哈希表中的所有字段
7. hlen key : 获取所有字段的数量
8. hedl key field : 删除key的一个属性
9. hsetnx key field value : 不存在时设置值
10. hincrby key field num : 自增
11. hexists key field : 查看属性是否存在
hash应用场景
1. 常用来存储一个对象
2. 为什么不用String存储一个对象?
hash是最接近关系型数据库的数据结构,可以将数据库一条记录或者程序中一个对象穿换成hashmap存放在redis中。
使用key/value 首先会出现需要转换对象的问题,修改值的问题。
Redis提供的hash很好的解决了这个问题,Redis的Hash实际上是内部存储的value为一个hashmap,并提供了直接存储这个map成员的接口。
3.List
类似于Java中的LinkedList
list常用命令:
赋值语法:
1. lpush key value1 [value2] : 给list左边添加值,添加至表头部
2. rpush key value1 [value2] : 给list右边添加值,添加至表尾部
3. lpushx key value : 将一个值存入列表头部,列表不存在操作无效。
4. rpushx key value : 将一个值存入列表尾部,列表不存在操作无效。
取值语法:
1. llen key // 获取key列表的长度
2. lindex key index //通过索引获取列表中的元素
3. lrange key start stop //获取列表指定范围内的数据。
索引从0开始算。 -1 表示列表的最后一个元素。-2 表示列表的倒数第二个元素。 以此类推。
删除语法:
1. lpop key : 移除并获取列表的第一个元素。(从左侧删除)
2. rpop key : 移除并获取列表的最后一个元素。(从右侧删除)
3. blpop key1[key2] timeout : 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表,直到等到超时或发现可弹出元素为止。
4. brpop key1 timeout : 同上。
5. ltrime key start stop : 修建key .只保留 区间内的值。
修改语法:
1. lset key index value : 通过索引设置列表元素的值。
2. linsert key before|after world value : 在列表元素world的前边或者后边插入value值。
list常用场景:
1. 对数据量大的集合数据删减。
列表数据显示、关注列表、粉丝列表、留言评价、分页、热点新闻等。
2. 任务队列。
任务队列,任务队列中的任务未完成,此时不能执行接下来的操作。
场景:订单系统的下单流程。 网站要求实名认证。
4.Set
类似于Java中的hashtable 。 数据不重复,且无序
set常用命令:
sadd codebear 6 1 2 3 3 8 6 : 给set赋值
scard key : 获取集合的成员数。
smembers codebear : 查看set的值
srem key member1 [member2]: 移除集合中农一个或多个成员
spop key[count]: 移除并返回集合中的一个随机元素。
srandmember codebear 2 : 从set集合中随机取出两个不重复的值。
srandmember codebear -2 : 从set集合中随机取出两个可以重复的值
srandmember: 参数的值如果大于set元素个数,如10,则取出全部元素。-10,则取出多个重复元素。
我们做抽奖系统,就可以用到这个命令了,如果可以重复中奖,后面带着负数,如果不能重复中奖,后面带着正数。
set还可以计算差集、并集、交集:
sunion codebear1 codebear2 差集
sdiff codebear1 codebear2 并集
sinter codebear1 codebear2 交集
== 扩展:
sunionstore destination key[key2]: 返回差集 存储在destination中
set应用场景:
常用语:对两个集合间的数据进行交集,并集,交集运算。
1. 共同关注,共同喜好,等。
2. 唯一性
5.zset
zset > 有序集合。 不重复。
zset常用命令: 每一个zset都有一个source的概念。 集合就是根据source排序的。从小到达。
1. zadd key score1 value1 [score2 value2] : 赋值操作。
2.
zset应用场景。
1. 排行榜。


Java连接Redis
常用jedis 来 Java连接Redis。
我使用的gradle: "redis.clients:jedis:2.9.0"
/**
* Java通过Jedis连接Redis.
*/
public class TestRedis1 {
public static void main(String[] args) {
Jedis jedis = new Jedis("localhost");
System.out.println("连接成功");
System.out.println(jedis.ping());
if (jedis.exists("erwa")) {
String erwa = jedis.get("erwa");
System.out.println("jedis中查的数据" + erwa);
} else {
String erwa = "二娃";
jedis.set("erwa", erwa);
System.out.println("数据库中插到的数据"+erwa);
}
jedis.close();
}
}
Redis中有哪些命令,Jedis中就有哪些方法。
// Redis的String的作用:为了减轻数据库的访问压力。
// 需求:判断key是否存在,如果存在,从Redis中查出,如果不存在,从数据库中查出。
//连接池工具类
redisPoolUtil {
private static JedisPool pool;
static { //静态代码块,只被初始化一次
//1. Redis pool 基本配置信息。
JedisPoolConfig config = new JedisPoolConfig();
//有默认配置,这里就不自己配了。
String host = "localhost";
int port = 6379;
pool = new JedisPool(config,host,port);
}
//获取连接。
static Jedis getJedis(){
Jedis jedis = pool.getResource();
return jedis;
}
//关闭连接。
static void close(Jedis jedis){
jedis.close();
}
}
/**
使用Jedis来完成对hash的操作。
需求: hash存储一个对象。
判断redis中是否存在该key,如果存在,直接返回值。
如果不存在,查询数据库,(将查询的结果存入Redis)并返回给用户
*/
public void testHash(){
Jedis jedis = redisPoolUtil.getJedis();
String key = "user";
if(jedis.exists){
Map map = jedi.hgetAll(key);
sout(map );
}else{
//查询数据库并返回结果。
jedis.hset(key,"id","1");
jedis.hset(key,"name","1");
jedis.hset(key,"age","1");
jedis.hset(key,"remark","1");
}
}
//如果使用bean对象来接受数据库的对象并放入Redis中,要把bean对象实现序列化。
springdate 提供 RedisTemplate模板
这里就不跟着敲了,后续了解一下springboot如何整合Redis。
针对于Redis,String类型的运用场景模拟。限制登陆功能。一小时内最多输错3次。
使用RedisTemplate操作Redis的时候,一般会有两种调用Redis方法的方式:
写操作时:
1、redisTemplate.hashset(); 使用redisTemplate存入的数据不会被序列化。
2、redisTemplate.opsForHash().hashget存入的数据会被序列化。
读操作时:
1、redisTemplate.hashget() ; 使用RedisTemplate直接操作 。(查询没有被序列化的key)
2、redisTemplate.opsForHash().hashget(); 调用Redis的基本数据类型来操作(查询没有被序列化的key被序列化的key)。
默认的序列化方式为JDK的序列化方式。
通过注入的方式修改模板的快捷方式。

Redis高级操作
Redis发布订阅

Redis多数据库

Redis事务



事务的错误处理

事务的watch与unwatch 。 事务实行过程中避免被打断。


redis 的数据淘汰策略


Redis持久化
Redis默认使用的方式是RDB


缺点:小内存机器不适合使用。


redis缓存与数据库的一致性


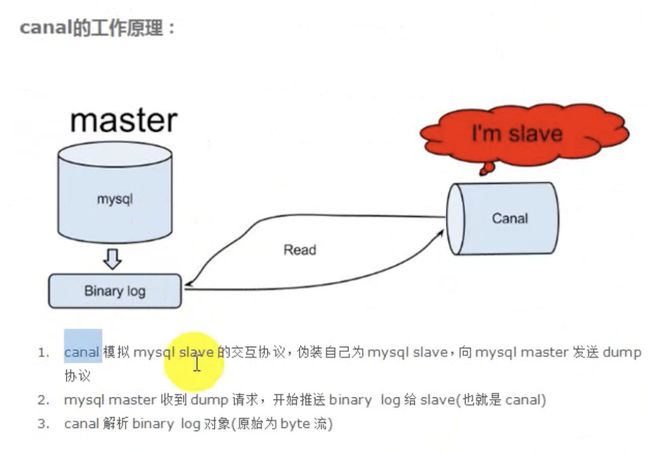


缓存穿透

缓存雪崩

热点key

Redis高级

高可用和高并发





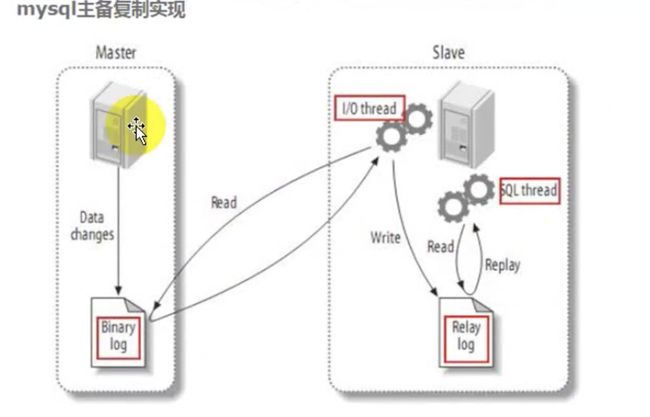
Redis主从复制
将主数据库所有增删改成功之后的SQL存储在日志中,同步在从数据库中。
但是也可能出现单机问题,主服务器也可能发生问题。


Redis Cluster集群
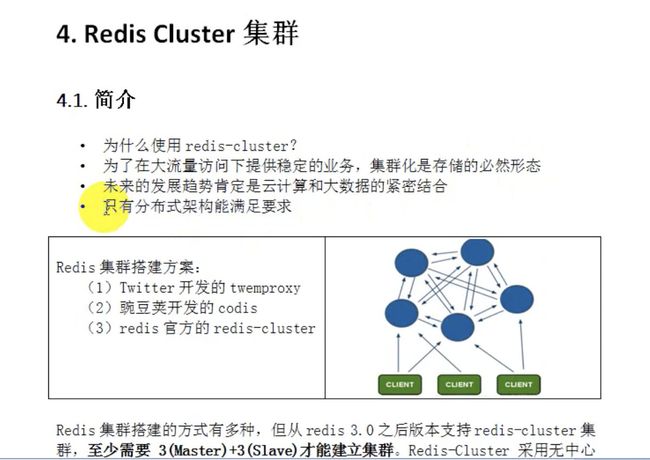
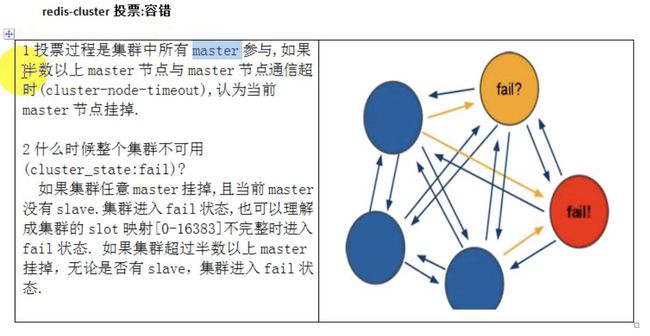
结构,每个结构保存数据和整个集群状态,每个节点都和其他所有节点相连。


Redis Cluster集群搭建



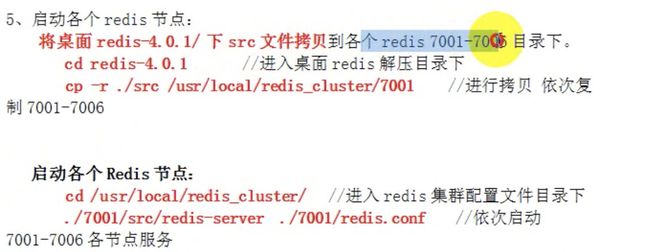


默认分配3主3从。



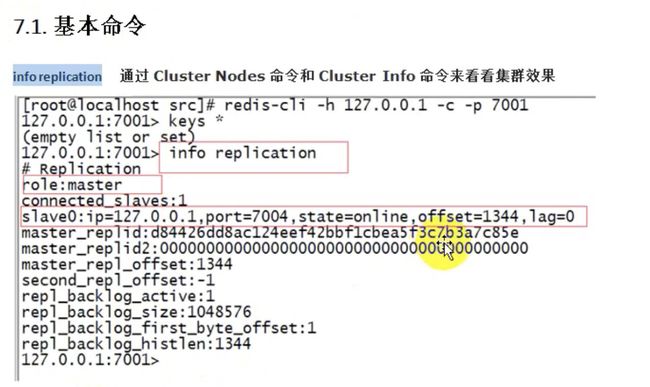
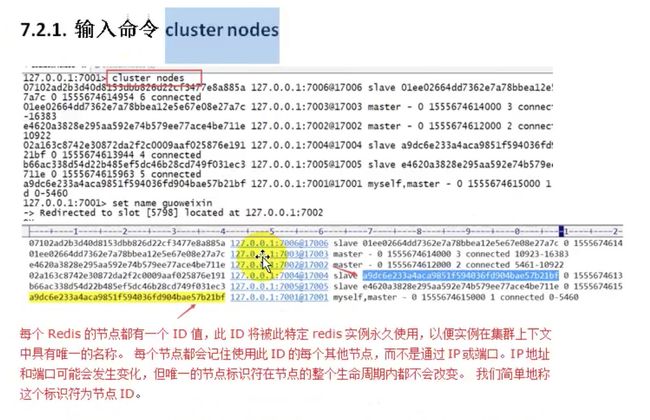
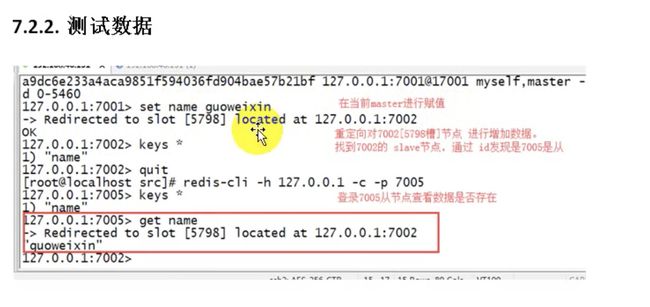
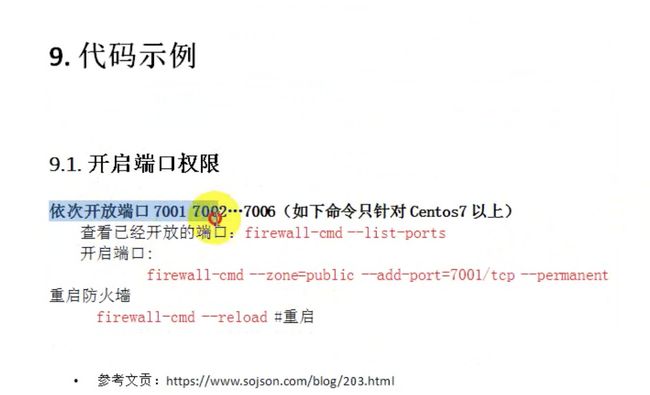

入门结束
对Redis有了大概的了解。算是入门了。但是由于缺少实战经验,对很多的概念也没有很深的了解。这篇笔记只是我作为一个Redis新手,从0到认知的一个过程。后续会持续深入学习。接下来需要用到的时候会重新开始一篇笔记,对用到的点进行一个整理学习与总结。
至于那些面试题,我认为,如果学透了一个知识点,面试题能够起到很好的辅助学习的作用,毕竟能够作为一门技术的面试题,都是这门技术的一个重点所在。
接下来我会去学习netty,由于之前收藏的有张龙老师的学习教程,总共68个小时。我预计花费2周的时间来进行学习。今日是周一。2020年03月23日06:49:58。 预计的是两周后的周末对这门技术进行一个笔记整理。
over。欢迎大家交流沟通。一位刚毕业在Java道路上摸爬滚打的程序员。