Spark Streaming架构原理剖析
文章目录
- 一、Spark Streaming 原理概述
- 二、DStream生成RDD实例的过程
- 1、什么是DStream
- 2、DStreamGraph
- 3、通过DStream生成RDD实例
- 3.1 何时生成RDD实例
- 3.2 如何通过DStream生成RDD实例
- 3.3.1、一般DStream生成RDD的过程
- 3.3.2、InputDStream生成RDD的过程
- 三、数据的收集和划分
- 1、Receiver的启动过程
- 2、Receiver收集数据并上报给ReceiverTracker
- 3、ReceiverTracker收到块信息后的处理工作
- 四、Spark Streaming运行的整个流程分析
- 五、容错和故障恢复保证
- 1、Driver端的长时容错
- 1.1、ReceivedBlockTracker 容错
- 1.2、StreamingContext 容错详解
- 2、Executor端的长时容错
- 2.1、热备——做数据副本
- 2.2、使用WAL进行冷备
- 2.3、重放
- 2.4、总结
- 六、窗口实现
- 1、什么是窗口
- 2、window函数的实现原理
- 七、状态管理实现
- 1、UpdateStateByKey操作的使用
- 2、UpdateStateByKey的实现
- 3、mapWithState
- 八、反压机制实现
- 1、RateController —— Driver端启动
- 2、Receiver实时更新速率并限制数据产生速度
- 参考资料
一、Spark Streaming 原理概述
我们常见的spark job是将一批数据分发到多台节点进行计算的任务。而Spark Streaming就是将不断流入的数据累积起来,然后划分成一个个spark job提交到集群运行。所以Spark Streaming其实就是一个源源不断的微批次处理任务。
我们写Spark Streaming程序时,都必须构造一个StreamingContext实例,StreamingContext的构造函数必须传入的batchDuration参数就是微批处理的时间间隔。比如设置的batchDuration是1s,那么Spark Streaming每隔1s就会收集数据然后生成Spark job提交到集群运行。
下面是spark官方解释Spark Streaming的一个图:
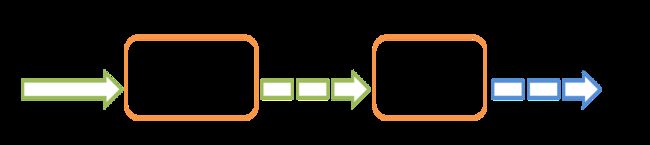
这图也说明了持续流入的数据流在进行Spark Streaming处理后会变成一批批的数据,最终还是交给Spark计算引擎处理。
看了上面的介绍,大家应该都能大概的理解Spark Streaming的架构原理了。但是这个原理终究还是比较泛,Spark Streaming中还是有很多细节值得我们去探究。在介绍那些细节前,我们可以先思考一下下面的三个问题:
- Spark Streaming的编程模型是DStream,它最终是如何转换成RDD的?另外是何时生成RDD?
- Spark Streaming是如何收集数据,然后分配给微批次中的RDD的?
- Spark Streaming是一个长时间运行的程序,它是如何做好容错和故障恢复的?
二、DStream生成RDD实例的过程
1、什么是DStream
在Spark Streaming中,我们都是面向DStream编程。从编程的角度来看,RDD支持的所有transformation函数DStream都能用,所以在我们使用者来看,好像DStream就是RDD,然后在RDD上又新增了一些流式计算的相关函数。
其实不然,严格来说,DStream是RDD的一个模板,RDD则是DStream的一个具体实例。就像java中类和实例的关系。
我们可以看一下DStream的一些关键属性:
//微批处理的时间间隔
def slideDuration: Duration
//维护上游的DStream
def dependencies: List[DStream[_]]
//历史生成过的RDD实例,key为时间。这个 Time 是与用户指定的 batchDuration 对齐了的时间
private[streaming] var generatedRDDs = new HashMap[Time, RDD[T]]()
//一个函数,定义如何生成RDD实例。DStream的各个子类有具体的实现
def compute(validTime: Time): Option[RDD[T]]
和RDD一样,DStream的transformation函数其实也是在各个不同的DStream之间进行转换。比如下面的这些DStream操作:
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" ")) // DStream transformation
val pairs = words.map(word => (word, 1)) // DStream transformation
val wordCounts = pairs.reduceByKey(_ + _) // DStream transformation
wordCounts.print() // DStream output
如果把它们用具体的DStream形容,就会变成如下的代码:
val lines = new SocketInputDStream("localhost", 9999) // 类型是 SocketInputDStream
val words = new FlatMappedDStream(lines, _.split(" ")) // 类型是 FlatMappedDStream
val pairs = new MappedDStream(words, word => (word, 1)) // 类型是 MappedDStream
val wordCounts = new ShuffledDStream(pairs, _ + _) // 类型是 ShuffledDStream
new ForeachDStream(wordCounts, cnt => cnt.print()) // 类型是 ForeachDStream
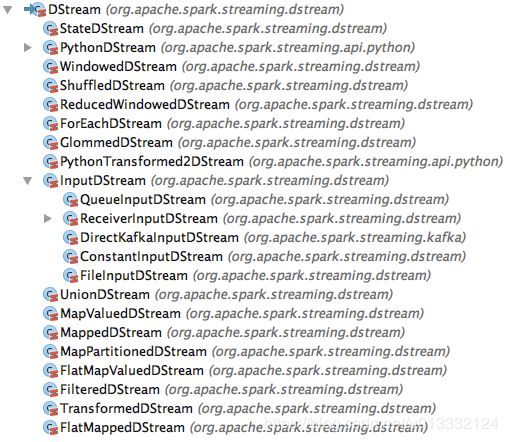
下面是DStream的各个子类:
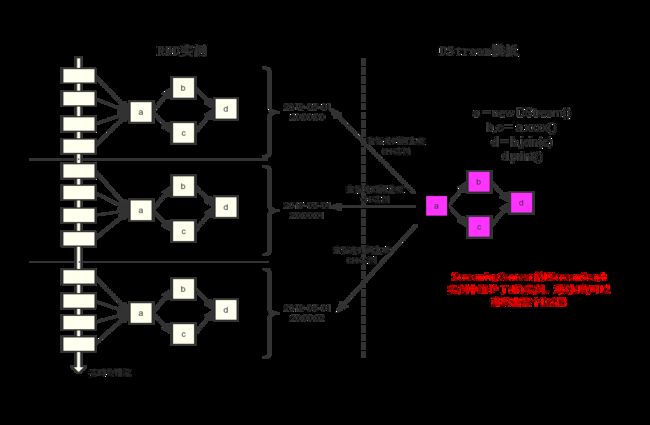
通过下图可以更好的理解DStream和RDD的关系:
2、DStreamGraph
在RDD体系中,RDD和它的dependencies会形成一个RDD DAG。在DStream中,RDD DAG对应的是DStreamGraph。
DStreamGraph是由StreamingContext维护的一个实例,我们先看一下它的一些重要属性:
//DAG中的起始DStreams,无法通过这个遍历DAG。主要为了快速找到DAG的起始节点,否则就要通过outputStreams来遍历整个DAG才能获取到
private val inputStreams = new ArrayBuffer[InputDStream[_]]()
//DAG中的结束DStreams。通过outputStreams和DStreams#dependencies,我们可以遍历整个DAG
private val outputStreams = new ArrayBuffer[DStream[_]]()
DStream在触发output操作时都会调用register()方法注册到StreamingContext的DStreamGraph实例中,也就是加入到outputStreams中,作为该DAG的某个结束节点。
这样,通过DStreamGraph的outputStreams,我们就可以遍历整个DAG图,然后通过反向驱动来生成RDD实例。这个原理也和RDD是一样的。
3、通过DStream生成RDD实例
3.1 何时生成RDD实例
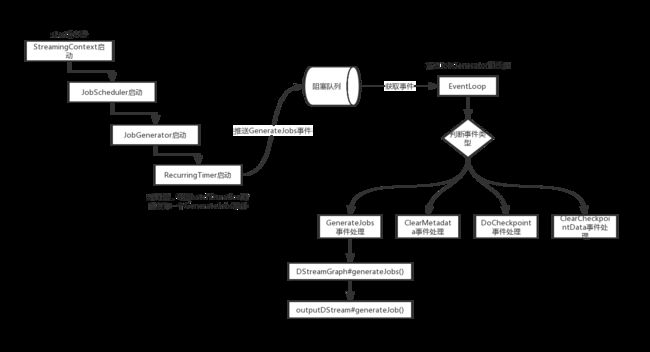
Spark Streaming程序在启动时,也就是调用StreamingContext#start()方法时,会启动JobScheduler组件。这个组件主要用于生成job以及调度job。在JobScheduler启动时,JobScheduler内部会再启动JobGenerator组件,这个组件才是真正用于生成RDD实例的组件。
JobGenerator会开启一个定时任务,每隔batchDuration运行一次,这个定时任务主要负责发布一个Job生成事件,之后有专门的线程来消费这个事件并负责生成RDD实例。
//主要就是生成一个GenerateJobs然后放入一个阻塞队列中
private val timer = new RecurringTimer(clock, ssc.graph.batchDuration.milliseconds,
longTime => eventLoop.post(GenerateJobs(new Time(longTime))), "JobGenerator")
事件消费线程代码如下:
override def run(): Unit = {
try {
while (!stopped.get) {
//不断的从队列去除事件进行处理
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
当该线程发现是GenerateJobs事件后,最终会调用以下方法生成RDD实例:
private def generateJobs(time: Time) {
// Checkpoint all RDDs marked for checkpointing to ensure their lineages are
// truncated periodically. Otherwise, we may run into stack overflows (SPARK-6847).
ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS, "true")
Try {
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
//调用DStreamGraph的generateJobs方法
graph.generateJobs(time) // generate jobs using allocated block
} match {
case Success(jobs) =>
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
PythonDStream.stopStreamingContextIfPythonProcessIsDead(e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
最终也是调用DStreamGraph的generateJobs方法来生成RDD实例。DStreamGraph中维护了outputStream数组,可以通过他们遍历整个DAG图,然后生成RDD实例。
整个过程大概如下图所示:
3.2 如何通过DStream生成RDD实例
DStream中有个abstract 的 compute(time) 方法,就是用来生成RDD实例的。另外DStream中还维护了一个HashMap[Time, RDD[T]],用来存储生成过的RDD。
DStream在要获取某个时间点的RDD时,会先去这个HashMap中获取,如果没有对应的RDD,则调用compute方法生成新的RDD实例然后存储到HashMap中。
上面的逻辑主要体现在DStream的getOrCompute方法中:
private[streaming] final def getOrCompute(time: Time): Option[RDD[T]] = {
// 从 generatedRDDs 里 get 一下:如果有 rdd 就返回,没有 rdd 就进行 orElse 下面的 rdd 生成步骤
generatedRDDs.get(time).orElse {
// 验证 time 需要是 valid
if (isTimeValid(time)) {
// 然后调用 compute(time) 方法获得 rdd 实例,并存入 rddOption 变量
val rddOption = createRDDWithLocalProperties(time) {
PairRDDFunctions.disableOutputSpecValidation.withValue(true) {
compute(time)
}
}
rddOption.foreach { case newRDD =>
if (storageLevel != StorageLevel.NONE) {
newRDD.persist(storageLevel)
logDebug(s"Persisting RDD ${newRDD.id} for time $time to $storageLevel")
}
if (checkpointDuration != null && (time - zeroTime).isMultipleOf(checkpointDuration)) {
newRDD.checkpoint()
logInfo(s"Marking RDD ${newRDD.id} for time $time for checkpointing")
}
// 将刚刚实例化出来的 rddOption 放入 generatedRDDs 对应的 time 位置
generatedRDDs.put(time, newRDD)
}
// 返回刚刚实例化出来的 rddOption
rddOption
} else {
None
}
}
}
3.3.1、一般DStream生成RDD的过程
每个DStream的子类都会实现compute()方法来生成RDD实例。一般来说,RDD实例的生成都会依赖DStream上游生成的RDD实例,所以RDD的生成也是一个反向驱动的过程。
比如MappedDStream的compute方法实现如下:
private[streaming] class MappedDStream[T: ClassTag, U: ClassTag] (
parent: DStream[T],
mapFunc: T => U
) extends DStream[U](parent.ssc) {
override def compute(validTime: Time): Option[RDD[U]] = {
//根据parent的RDD来生成自己的对应的RDD
parent.getOrCompute(validTime).map(_.map[U](mapFunc))
}
}
3.3.2、InputDStream生成RDD的过程
DStreamGraph中的起始节点被称为InputDStream。我们都知道,RDD DAG中肯定有一些节点是没有parent节点的,他们负责从外部读取数据然后进行处理。所以InputDStream和其他DStream比就比较特殊。
InputDStream需要根据不同的数据输入源来决定如何生成RDD实例。
比如FileInputDStream的实现:
// 来自 FileInputDStream
override def compute(validTime: Time): Option[RDD[(K, V)]] = {
// 通过一个 findNewFiles() 方法,找到 validTime 以后产生的新 file 的数据
val newFiles = findNewFiles(validTime.milliseconds)
logInfo("New files at time " + validTime + ":\n" + newFiles.mkString("\n"))
batchTimeToSelectedFiles += ((validTime, newFiles))
recentlySelectedFiles ++= newFiles
// 找到了一些新 file;以新 file 的数组为参数,通过 filesToRDD() 生成单个 RDD 实例 rdds
val rdds = Some(filesToRDD(newFiles))
val metadata = Map(
"files" -> newFiles.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> newFiles.mkString("\n"))
val inputInfo = StreamInputInfo(id, 0, metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
// 返回生成的单个 RDD 实例 rdds
rdds
}
主要流程大概如下:
- (1) 先通过一个 findNewFiles() 方法,找到 validTime 以后产生的多个新 file
- (2) 对每个新 file,都将其作为参数调用 sc.newAPIHadoopFile(file),生成一个 RDD 实例
- (3) 将 (2) 中的多个新 file 对应的多个 RDD 实例进行 union,返回一个 union 后的 UnionRDD
三、数据的收集和划分
InputDStream是DStream的一个子类。InputDStream如何生成RDD在上面一节也介绍过,并且给出了FileInputDStream的例子。但是有一些数据源是比较复杂的,也不好像FileInputDStream一样根据时间来切分数据源给各个时间段的RDD实例。比如Kafka、socket等。因此,对于这些数据源,spark抽象了ReceiverInputDStream这个类,它会根据具体的实现生成若干Receiver然后分发到各个executor收集数据。KafkaInputDStream和SocketInputDStream都是它的子类。
ReceiverInputDStream中定义了getReceiver抽象方法:
abstract class ReceiverInputDStream[T: ClassTag](_ssc: StreamingContext)
extends InputDStream[T](_ssc) {
//抽象方法
//KafkaInputDStream和SocketInputDStream都实现了具体的getReceiver方法
def getReceiver(): Receiver[T]
}
1、Receiver的启动过程
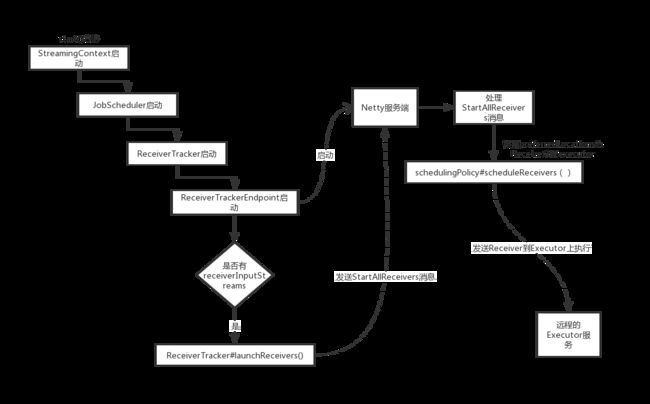
Spark Streaming程序在启动时,会启动JobScheduler组件,JobScheduler启动又会带动ReceiverTracker的启动。
def start(): Unit = synchronized {
if (isTrackerStarted) {
throw new SparkException("ReceiverTracker already started")
}
//判断是否有ReceiverInputDStream
if (!receiverInputStreams.isEmpty) {
//启动一个线程,负责处理后续来自Receivers的消息
endpoint = ssc.env.rpcEnv.setupEndpoint(
"ReceiverTracker", new ReceiverTrackerEndpoint(ssc.env.rpcEnv))
//启动Receivers
if (!skipReceiverLaunch) launchReceivers()
logInfo("ReceiverTracker started")
trackerState = Started
}
}
private def launchReceivers(): Unit = {
//从DStreamGraph的inputstream中找出所有的ReceiverInputDStream
val receivers = receiverInputStreams.map { nis =>
//调用getReceiver获取Receiver
val rcvr = nis.getReceiver()
rcvr.setReceiverId(nis.id)
rcvr
}
runDummySparkJob()
logInfo("Starting " + receivers.length + " receivers")
//发送StartAllReceivers事件,这个事件会被另外一个线程消费然后发送到executor上执行
endpoint.send(StartAllReceivers(receivers))
}
我们可以看一下ReceiverTrackerEndpoint如何对StartAllReceivers进行处理
override def receive: PartialFunction[Any, Unit] = {
// Local messages
case StartAllReceivers(receivers) =>
//schedulingPolicy策略类获取应该将receive分发到哪些executor上
//这里会根据Receive的preferredLocation来做选择,所以具体的策略也和Receive的实现相关
val scheduledLocations = schedulingPolicy.scheduleReceivers(receivers, getExecutors)
//遍历所有的receivers,并将它们分发到对应的executor上
for (receiver <- receivers) {
val executors = scheduledLocations(receiver.streamId)
updateReceiverScheduledExecutors(receiver.streamId, executors)
receiverPreferredLocations(receiver.streamId) = receiver.preferredLocation
startReceiver(receiver, executors)
}
case RestartReceiver(receiver) =>
...
case c: CleanupOldBlocks =>
receiverTrackingInfos.values.flatMap(_.endpoint).foreach(_.send(c))
case UpdateReceiverRateLimit(streamUID, newRate) =>
...
case ReportError(streamId, message, error) =>
reportError(streamId, message, error)
}
schedulingPolicy的分发策略大概如下:
- 如果Receive指定了preferredLocation,就分发到指定host的executor上
- 如果Receive没指定preferredLocation,则尽量保证Receive均匀的分到到各个executor上
Receiver的启动过程大概如下:
2、Receiver收集数据并上报给ReceiverTracker
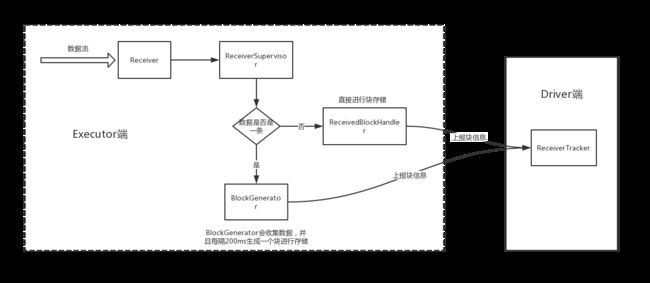
Receiver在executor上启动后,就开始持续不断地接收外界数据,并持续交给 ReceiverSupervisor 进行数据转储。
ReceiverSupervisor收到数据后,如果数据就一条,就将数据给BlockGenerator处理,BlockGenerator会收集数据后每隔一定时间再转成块存储方式,这个时间和spark.streaming.blockInterval配置有关,默认为200ms。如果是一批数据则直接进行块存储,块存储由ReceivedBlockHandler来负责,目前spark streaming有两种ReceivedBlockHandler实现:
- blockManagerskManagerBasedBlockHandler:直接存到 executor 的内存或硬盘
- WriteAheadLogBasedBlockHandler:同时写 WAL(4c) 和 executor 的内存或硬盘
数据处理过程如下:
3、ReceiverTracker收到块信息后的处理工作
Receiver 通过 AddBlock 消息上报 块的meta 信息给 ReceiverTracker,ReceiverTracker进行处理的代码在ReceiverTrackerEndpoint中:
override def receiveAndReply(context: RpcCallContext): PartialFunction[Any, Unit] = {
// Remote messages
case RegisterReceiver(streamId, typ, host, executorId, receiverEndpoint) =>
val successful =
registerReceiver(streamId, typ, host, executorId, receiverEndpoint, context.senderAddress)
context.reply(successful)
case AddBlock(receivedBlockInfo) =>
if (WriteAheadLogUtils.isBatchingEnabled(ssc.conf, isDriver = true)) {
walBatchingThreadPool.execute(new Runnable {
override def run(): Unit = Utils.tryLogNonFatalError {
if (active) {
context.reply(addBlock(receivedBlockInfo))
} else {
throw new IllegalStateException("ReceiverTracker RpcEndpoint shut down.")
}
}
})
} else {
context.reply(addBlock(receivedBlockInfo))
}
case DeregisterReceiver(streamId, message, error) =>
...
case AllReceiverIds =>
context.reply(receiverTrackingInfos.filter(_._2.state != ReceiverState.INACTIVE).keys.toSeq)
case GetAllReceiverInfo =>
context.reply(receiverTrackingInfos.toMap)
case StopAllReceivers =>
...
}
private def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = {
receivedBlockTracker.addBlock(receivedBlockInfo)
}
ReceiverTracker收到AddBlock消息后,会交给ReceivedBlockTracker处理。
ReceivedBlockTracker专门负责已上报的块数据 meta 信息管理。ReceivedBlockTracker中有3个重要的属性:
//未分配的块数据
private val streamIdToUnallocatedBlockQueues = new mutable.HashMap[Int, ReceivedBlockQueue]
//已分配的块数据
private val timeToAllocatedBlocks = new mutable.HashMap[Time, AllocatedBlocks]
//记录了最近一个分配完成的 batch 是哪个
private var lastAllocatedBatchTime: Time = null
ReceivedBlockTracker收到块信息后会将其加入到streamIdToUnallocatedBlockQueues中。之后当JobGenerator要生成新的一个batch的RDD实例时,就会以batchTime为key,将streamIdToUnallocatedBlockQueues的数据添加到timeToAllocatedBlocks中。这样,InputDStream生成的RDD实例就知道应该读取哪些块作为输入数据了。
四、Spark Streaming运行的整个流程分析
Spark Streaming程序启动后,会启动JobScheduler,JobScheduler又会启动两个组件,分别是JobGenerator和ReceiverTracker。
ReceiverTracker启动后,会进行如下操作:
- 发送若干个Receiver到Executor上执行。Receiver就开始持续不断的接收数据
- Receiver接收到的数据最终会通过BlockManager存储到Executor的内存或者磁盘上
- 数据存储完后,Receiver还会将块的meta信息上报给Driver端的ReceiverTracker
- ReceiverTracker会收集这些块meta信息,后面用于分配给下一个batch。
JobGenerator启动后,会定时的为每个batch生成RDD DAG的实例,生成RDD DAG主要包含以下步骤:
- 要求ReceiverTracker将目前收集到的数据进行一次allocate,也就是要将这些数据分配给新的这batch
- 要求DStreamGraph 生成一套新的 RDD DAG 的实例,这里会获取到一个 Set[Job]
- 获取第一步中ReceiverTracker分配给本batch的块meta信息,并将这些meta信息分配给InputDStream生成的RDD实例
- 将Job封装成JobHandler,然后提交到JobScheduler的jobExecutor线程池进行调度。
jobExecutor是一个fix线程池,它的并行度由配置spark.streaming.concurrentJobs决定,默认是1。所以Spark Streaming中job的并行度也是由这个配置来决定的
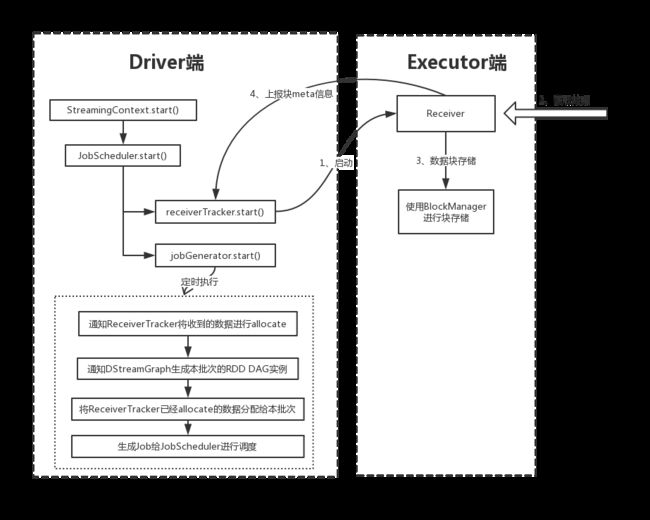
五、容错和故障恢复保证
Spark Streaming作为一个长时间运行的程序,容错和故障恢复保证是很重要的。从上面的介绍我们可以看出,它的运行进程主要有Driver端和Executor端,下面我们分别分析一下这两个端的长时容错。
1、Driver端的长时容错
在Driver端,我们需要做好两方面的容错
- ReceivedBlockTracker 容错,保证接收到的块meta信息不会因driver重启而丢失。—— 使用WAL方式
- StreamingContext 容错,保存每个batch生成的RDD以及Job的完成情况——采用checkpoint方式
1.1、ReceivedBlockTracker 容错
ReceivedBlockTracker才用WAL的冷备方式进行备份,对块的各种操作都会被写到文件中去。
def addBlock(receivedBlockInfo: ReceivedBlockInfo): Boolean = synchronized {
...
// 【在收到了 Receiver 报上来的 meta 信息后,先通过 writeToLog() 写到 WAL】
writeToLog(BlockAdditionEvent(receivedBlockInfo))
// 【再将 meta 信息索引起来】
getReceivedBlockQueue(receivedBlockInfo.streamId) += receivedBlockInfo
...
}
def allocateBlocksToBatch(batchTime: Time): Unit = synchronized {
...
// 【在收到了 JobGenerator 的为最新的 batch 划分 meta 信息的要求后,先通过 writeToLog() 写到 WAL】
writeToLog(BatchAllocationEvent(batchTime, allocatedBlocks))
// 【再将 meta 信息划分到最新的 batch 里】
timeToAllocatedBlocks(batchTime) = allocatedBlocks
...
}
def cleanupOldBatches(cleanupThreshTime: Time, waitForCompletion: Boolean): Unit = synchronized {
...
// 【在收到了 JobGenerator 的清除过时的 meta 信息要求后,先通过 writeToLog() 写到 WAL】
writeToLog(BatchCleanupEvent(timesToCleanup))
// 【再将过时的 meta 信息清理掉】
timeToAllocatedBlocks --= timesToCleanup
// 【再将 WAL 里过时的 meta 信息对应的 log 清理掉】
writeAheadLogOption.foreach(_.clean(cleanupThreshTime.milliseconds, waitForCompletion))
}
从上面的代码可以看出,在触发BlockAdditionEvent, BatchAllocationEvent, BatchCleanupEvent这些事件时,都会调用writeToLog将对应的数据写入文件。
后面当Driver挂了重启后,就可以根据WAL文件来重新构建出之前的ReceivedBlockTracker的状态了。
1.2、StreamingContext 容错详解
StreamingContext通过做checkpoint来进行容错。checkpoint的开启需要在程序中手动指定checkpoint的目录:
// Function to create and setup a new StreamingContext
def functionToCreateContext(): StreamingContext = {
val ssc = new StreamingContext(...) // new context
val lines = ssc.socketTextStream(...) // create DStreams
...
ssc.checkpoint(checkpointDirectory) // set checkpoint directory
ssc
}
// Get StreamingContext from checkpoint data or create a new one
val context = StreamingContext.getOrCreate(checkpointDirectory, functionToCreateContext _)
// Do additional setup on context that needs to be done,
// irrespective of whether it is being started or restarted
context. ...
// Start the context
context.start()
context.awaitTermination()
StreamingContext会先尝试从checkpointDirectory目录中读取之前的状态来恢复,如果读取不到,就创建一个新的StreamingContext。
Driver在运行过程中,有两个事件发生后会进行一次Checkpoint:
- JobGenerator.generateJob() 生成JobSet后会立马做一次Checkpoint
- JobScheduler将提交的JobSet执行完后也会做一次Checkpoint
Checkpoint其实就是将Checkpoint对象序列化然后写入checkpoint文件,后面重启Driver时再从Checkpoint文件恢复。我们可以看一下Checkpoint对象的组成:
private[streaming]
class Checkpoint(ssc: StreamingContext, val checkpointTime: Time)
extends Logging with Serializable {
val master = ssc.sc.master
val framework = ssc.sc.appName
val jars = ssc.sc.jars
val graph = ssc.graph
val checkpointDir = ssc.checkpointDir
val checkpointDuration = ssc.checkpointDuration
val pendingTimes = ssc.scheduler.getPendingTimes().toArray
val sparkConfPairs = ssc.conf.getAll
}
2、Executor端的长时容错
executor端的容错即对输入数据的保障机制。Receiver获取到数据后会将数据以块存储的方式保存下来,这时如何保证Executor挂掉后这些数据依然不会丢失呢?
Executor端的容错保证主要有以下几种方式
2.1、热备——做数据副本
由于Receiver底层也是使用了BlockManager进行块存储,因此我们可以直接将块存储的StorageLevel调整成MEMORY_ONLY_2 或 MEMORY_AND_DISK_2。这样,Receiver在进行块存储的时候就会在不同的Executor上存储两份数据。即使某一个Executor挂了也不影响数据的获取。
Receiver使用的BlockManager StorageLevel和它的实现有关,比如我们实现一个自己的Receiver:
class MyReceiver extends Receiver(StorageLevel.MEMORY_ONLY_2) {
override def onStart(): Unit = {}
override def onStop(): Unit = {}
}
这里的StorageLevel为MEMORY_ONLY_2。
2.2、使用WAL进行冷备
在进行块存储时,使用WAL将数据先写入Hdfs文件中,后面Executor挂掉重启后就可以直接从WAL还原。
WAL需要在设置spark.streaming.receiver.writeAheadLog.enable为true,该值默认为false。
2.3、重放
如果输入源支持重放,我们可以不用冷备或者热备,直接从数据源再次读取数据就好了。比如Kafka,我们直接给RDD分配offset范围即可。那么即使Executor挂了,也不会影响RDD直接根据offset的范围来读取数据。
2.4、总结
| 容错方式 | 优点 | 缺点 |
|---|---|---|
| (1) 热备 | 无 recover time | 需要占用双倍资源 |
| (2) 冷备 | 十分可靠 | 存在 recover time |
| (3) 重放 | 不占用额外资源 | 存在 recover time |
六、窗口实现
1、什么是窗口
窗口是很多实时流框架都有的特性。有了窗口,我们就可以在计算的时候针对窗口内的数据进行计算,比如我们要统计一分钟以内的用户数,就可以设置一个大小为1分钟的时间窗口。窗口一般分为两种窗口:
- 基于时间的窗口,这个时间可以是数据的事件时间、数据的注入时间或者数据的处理时间。目前Spark Streaming只支持数据的处理时间的窗口
- 基于数量的窗口,一般是以数据条数为一个窗口。比如每3条数据为一个窗口
- 会话窗口,一般会以某个事件作为窗口的开始,以某个事件作为窗口的结束。比如一个用户打开浏览器的事件作为窗口开始,以用户关闭浏览器作为窗口的结束来统计用户的使用时长。
2、window函数的实现原理
当我们做WordCount统计时,每次算的都是本批次的数据。如果我们想统计近十分钟的数据,就可以使用window函数
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.window(Seconds(1),Seconds(1))
//后面都是基于10分钟以内的数据进行计算
words....
window函数其实也是基于DStream来实现的:
// windowDuration表示窗口的大小,slideDuration表示每隔多久滑动一次窗口
def window(windowDuration: Duration, slideDuration: Duration): DStream[T] = ssc.withScope {
new WindowedDStream(this, windowDuration, slideDuration)
}
window方法会返回一个WindowedDStream对象。我们再看一下WindowedDStream的compute方法,看它是如何生成RDD实例的:
override def compute(validTime: Time): Option[RDD[T]] = {
val currentWindow = new Interval(validTime - windowDuration + parent.slideDuration, validTime)
val rddsInWindow = parent.slice(currentWindow)
Some(ssc.sc.union(rddsInWindow))
}
DStream#slice()方法会根据时间范围获取对应的RDD实例,之后对这些RDD实例进行union操作,也就是返回一个UnionRDD实例。也就是将该时间窗口内各个batch的数据进行union操作后返回。
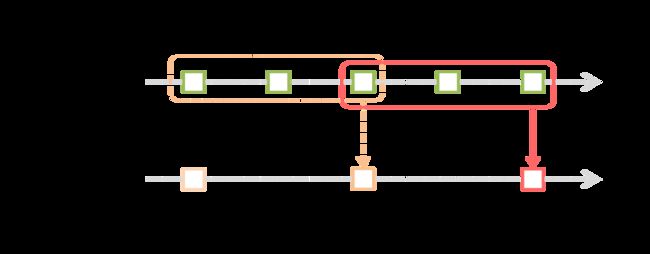
同样的,reduceByWindow和countByWindow方法也都是类似的原理。
七、状态管理实现
1、UpdateStateByKey操作的使用
我们目前看到的Spark Streaming的计算都是无状态的,最多基于使用了窗口聚合了多个batch的数据进行计算。但是很多时候,我们需要针对一些状态进行计算。这个状态可以是任何类型,表达各种含义。比如在WordCount例子中,我们需要统计历史所有的word出现的次数,那么此时次数就是状态。
我们可以先定义一个状态更新函数:
//newValues表示本批次中的新数据
//runningCount表示之前的状态,也就是之前统计过的次数。状态类型是Int
def updateFunction(newValues: Seq[Int], runningCount: Option[Int]): Option[Int] = {
val newCount = ... // add the new values with the previous running count to get the new count
Some(newCount)
}
之后使用这个函数进行状态更新
//状态类型是Int
val runningCounts = pairs.updateStateByKey[Int](updateFunction _)
2、UpdateStateByKey的实现
UpdateStateByKey的实现其实也是基于DStream。UpdateStateByKey函数会返回一个StateDStream实例。我们可以看一下它是如何生成RDD实例的:
override def compute(validTime: Time): Option[RDD[(K, S)]] = {
//获取上一个batch的StateDStream生成的RDD
getOrCompute(validTime - slideDuration) match {
case Some(prevStateRDD) => // If previous state RDD exists
//获取上游RDD
parent.getOrCompute(validTime) match {
case Some(parentRDD) =>
//进行cogroup操作
computeUsingPreviousRDD (validTime, parentRDD, prevStateRDD)
case None => // If parent RDD does not exist
// Re-apply the update function to the old state RDD
val updateFuncLocal = updateFunc
val finalFunc = (iterator: Iterator[(K, S)]) => {
val i = iterator.map(t => (t._1, Seq[V](), Option(t._2)))
updateFuncLocal(validTime, i)
}
val stateRDD = prevStateRDD.mapPartitions(finalFunc, preservePartitioning)
Some(stateRDD)
}
case None => // If previous session RDD does not exist (first input data)
// Try to get the parent RDD
parent.getOrCompute(validTime) match {
case Some(parentRDD) => // If parent RDD exists, then compute as usual
initialRDD match {
case None =>
// Define the function for the mapPartition operation on grouped RDD;
// first map the grouped tuple to tuples of required type,
// and then apply the update function
val updateFuncLocal = updateFunc
val finalFunc = (iterator: Iterator[(K, Iterable[V])]) => {
updateFuncLocal (validTime,
iterator.map (tuple => (tuple._1, tuple._2.toSeq, None)))
}
val groupedRDD = parentRDD.groupByKey(partitioner)
val sessionRDD = groupedRDD.mapPartitions(finalFunc, preservePartitioning)
// logDebug("Generating state RDD for time " + validTime + " (first)")
Some (sessionRDD)
case Some (initialStateRDD) =>
computeUsingPreviousRDD(validTime, parentRDD, initialStateRDD)
}
case None => // If parent RDD does not exist, then nothing to do!
// logDebug("Not generating state RDD (no previous state, no parent)")
None
}
}
}
private [this] def computeUsingPreviousRDD(
batchTime: Time,
parentRDD: RDD[(K, V)],
prevStateRDD: RDD[(K, S)]) = {
// Define the function for the mapPartition operation on cogrouped RDD;
// first map the cogrouped tuple to tuples of required type,
// and then apply the update function
val updateFuncLocal = updateFunc
val finalFunc = (iterator: Iterator[(K, (Iterable[V], Iterable[S]))]) => {
val i = iterator.map { t =>
val itr = t._2._2.iterator
val headOption = if (itr.hasNext) Some(itr.next()) else None
(t._1, t._2._1.toSeq, headOption)
}
updateFuncLocal(batchTime, i)
}
val cogroupedRDD = parentRDD.cogroup(prevStateRDD, partitioner)
val stateRDD = cogroupedRDD.mapPartitions(finalFunc, preservePartitioning)
Some(stateRDD)
}
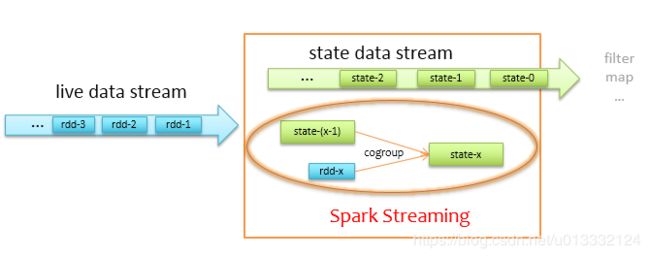
prevStateRDD可以看出是之前的状态,parentRDD表示当前的数据。Spark Streaming做的其实就是将之前的状态和当前的数据进行cogroup操作,然后根据我们定义的函数生成新的状态后存储起来。
整个过程如下图所示:
3、mapWithState
UpdateStateByKey有个问题,就是随着程序的运行,Key的数量会越来越多,每次进行cogroup操作都将非常耗时。性能会越来越差。
为了解决这个问题,从Spark-1.6开始,Spark-Streaming引入一种新的状态管理机制mapWithState,支持输出全量的状态和更新的状态,还支持对状态超时管理。
// 状态更新函数,output是输出,state是状态
val mappingFunc = (
userId: Long,
value: Option[Int],
state: State[Set[Int]]) => {
val previousValues = state.getOption.getOrElse(Set.empty[Int])
val newValues = if (value.isDefined){
previousValues.add(value.get)
} else previousValues
val output = (userId, newValues)
state.update(newValues)
output
}
// 原始数据流,经过过滤清洗,得到的记录形式为(userId, clickId)
val liveDStream = ... // (userId, clickId)
// 使用mapWithState更新状态,并设置状态超时时间为1小时
val stateDstream = liveDStream.mapWithState(
StateSpec.function(mappingFunc).timeout(Minutes(60)))
// stateDstream默认只返回新数据经过mappingFunc后的结果
// 通过stateDstream.snapshot()返回当前的全量状态
stateDstream.foreach(...)
mappingFunc函数会接收每个进来的数据,然后返回一个更新后的执行。同时在这个方法内我们还可以更新状态最新值。
调用mapWithState会返回一个MapWithStateDStream,对这个DStream进行输出只会得到经过mappingFunc处理后的结果,想要获取全量状态需要调用stateSnapshots()方法。
mapWithState的实现大概如下图:
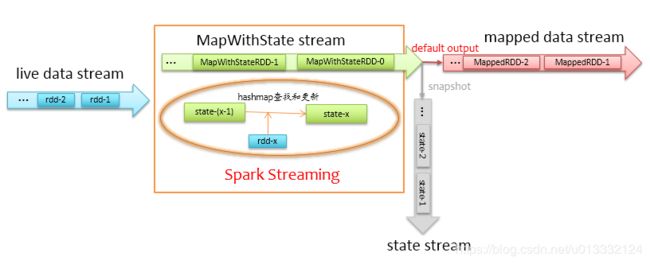
计算过程中,Spark-Streaming会遍历当前时间间隔内的数据rdd-x的key,然后去state-(x-1)里面寻找对应的key,然后调用mappingFunc进行更新,之后得到state-x。state-x的数据是会以HashMap的方式存储在内存中,这样当遍历rdd-x时,就可以快速定位到对应的key的状态值。
mapWithState其实也有一个问题,为了保证高效,它的状态数据都保持在内存中,非常耗内存。另外当数据太大时,就会有OOM的风险。
八、反压机制实现
Spark Streaming在运行中,有时会因为流量突增而导致数据的生产速度大于数据消费速度,进而导致数据堆积,最后出现OOM等问题。
在Spark-1.5之前,我们可以通过spark.streaming.receiver.maxRate来限制流量,但是这种设置依旧无法很好的动态根据数据流量来调整数据的生产速度。在1.5之后,Spark支持动态的调节生产速率。Spark Streaming会实时统计每个batch的处理时间,然后再和生产速率做对比,如果生产速度大于处理速度的话,就会限制数据的生产速度来达到反压的目的。
开启反压机制需要设置spark.streaming.backpressure.enabled为true,这个参数默认是false。
1、RateController —— Driver端启动
RateController继承了StreamingListener,并且实现了onBatchCompleted方法,当一个Batch结束后,RateController可以获取到任务的执行时间、延迟时间、处理条数等信息,然后交给RateEstimator计算速率,之后计算好的速率通过ReceiverTracker推送到Executor上的Receiver。
目前RateEstimator就一个基于PID算法的速率估算实现类。
在JobScheduler启动时,会注册RateController实例。
for {
inputDStream <- ssc.graph.getInputStreams
rateController <- inputDStream.rateController
} ssc.addStreamingListener(rateController)
rateController的实例是从inputDStream获取的。因此,每个inputDStream都有自己的rateController实现。RateController注册到Listener后,就可以监听Job的执行状态了。
2、Receiver实时更新速率并限制数据产生速度
当Receiver接收到数据时,会通过supervisor.pushSingle()方法将数据交给BlockGenerator进行存储。整个过程的代码如下:
//BlockGenerator.scala
def addData(data: Any): Unit = {
if (state == Active) {
//查看速率是否超过,如果生产速度太快会在此处进行限流
waitToPush()
synchronized {
if (state == Active) {
currentBuffer += data
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
} else {
throw new SparkException(
"Cannot add data as BlockGenerator has not been started or has been stopped")
}
}
def waitToPush() {
rateLimiter.acquire()
}
rateLimiter的实现是来自guava包。guava的RateLimiter使用的是令牌桶算法,也就是以固定的频率向桶里放置令牌,然后Receiver在每次add数据时需要从令牌桶获取令牌,如果获取不到则阻塞等待桶中有令牌了才可以放行。
由于Driver那边会不断的统计当前消费的速率然后推送到Receiver,Receiver接收到rate更新消息后就会更新rateLimiter的速率,这样就达到了限制数据生产速度的目的了。
参考资料
Spark Streaming 实现思路与模块概述
spark反压机制详解
Spark-Streaming状态管理应用优化之路
一文读懂PID控制算法
Guava官方文档-RateLimiter类