前言
经过上一篇文章的探索,我们已经熟知了图元是如何消费的。当一旦有图元进行过消费,SF就会决定刷新整个屏幕,大致上分为如下6个步骤:
- 1.preComposition 预处理合成
- 2.rebuildLayerStacks 重新构建Layer栈
- 3.setUpHWComposer HWC的渲染或者准备
- 4.doDebugFlashRegions 打开debug绘制模式
- 5.doTracing 跟踪打印
- 6.doComposition 合成图元
- 7.postComposition 图元合成后的vysnc等收尾工作。
对应第3点和第4点。暂时没必要关心。本文着重分析第1,2,5,6,7 五个步骤。
如果遇到问题请到本文进行讨论https://www.jianshu.com/p/e3ffe13f82aa
正文
preComposition 预处理合成
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::preComposition(nsecs_t refreshStartTime)
{
bool needExtraInvalidate = false;
mDrawingState.traverseInZOrder([&](Layer* layer) {
if (layer->onPreComposition(refreshStartTime)) {
needExtraInvalidate = true;
}
});
if (needExtraInvalidate) {
signalLayerUpdate();
}
}
bool BufferLayer::onPreComposition(nsecs_t refreshStartTime) {
if (mBufferLatched) {
Mutex::Autolock lock(mFrameEventHistoryMutex);
mFrameEventHistory.addPreComposition(mCurrentFrameNumber,
refreshStartTime);
}
mRefreshPending = false;
return mQueuedFrames > 0 || mSidebandStreamChanged ||
mAutoRefresh;
}
此时判断到mQueuedFrames还有其他图元需要消费。返回 true,继续调用signalLayerUpdate进行下一轮的invalidate消息。
rebuildLayerStacks 重新构建Layer栈计算可视区
void SurfaceFlinger::rebuildLayerStacks() {
if (CC_UNLIKELY(mVisibleRegionsDirty)) {
ATRACE_NAME("rebuildLayerStacks VR Dirty");
mVisibleRegionsDirty = false;
invalidateHwcGeometry();
for (size_t dpy=0 ; dpy> layersSortedByZ;
Vector> layersNeedingFences;
const sp& displayDevice(mDisplays[dpy]);
const Transform& tr(displayDevice->getTransform());
const Rect bounds(displayDevice->getBounds());
if (displayDevice->isDisplayOn()) {
computeVisibleRegions(displayDevice, dirtyRegion, opaqueRegion);
mDrawingState.traverseInZOrder([&](Layer* layer) {
bool hwcLayerDestroyed = false;
if (layer->belongsToDisplay(displayDevice->getLayerStack(),
displayDevice->isPrimary())) {
Region drawRegion(tr.transform(
layer->visibleNonTransparentRegion));
drawRegion.andSelf(bounds);
if (!drawRegion.isEmpty()) {
layersSortedByZ.add(layer);
} else {
hwcLayerDestroyed = layer->destroyHwcLayer(
displayDevice->getHwcDisplayId());
}
} else {
hwcLayerDestroyed = layer->destroyHwcLayer(
displayDevice->getHwcDisplayId());
}
if (hwcLayerDestroyed) {
auto found = std::find(mLayersWithQueuedFrames.cbegin(),
mLayersWithQueuedFrames.cend(), layer);
if (found != mLayersWithQueuedFrames.cend()) {
layersNeedingFences.add(layer);
}
}
});
}
displayDevice->setVisibleLayersSortedByZ(layersSortedByZ);
displayDevice->setLayersNeedingFences(layersNeedingFences);
displayDevice->undefinedRegion.set(bounds);
displayDevice->undefinedRegion.subtractSelf(
tr.transform(opaqueRegion));
displayDevice->dirtyRegion.orSelf(dirtyRegion);
}
}
}
mVisibleRegionsDirty如果为true,说明有Layer 加入或者说latchBuffer对应的图元的显示出现了改变。
首先遍历每一个屏幕下对应所有的displayDevice,计算每一个computeVisibleRegions中的可视区域,透明区域等。并且拿这个区域和每一个Layer的visibleNonTransparentRegion(可见不透明区域)互相交集,保存到displayDevice。
先来看看核心方法computeVisibleRegions。
computeVisibleRegions
void SurfaceFlinger::computeVisibleRegions(const sp& displayDevice,
Region& outDirtyRegion, Region& outOpaqueRegion)
{
ATRACE_CALL();
ALOGV("computeVisibleRegions");
Region aboveOpaqueLayers;
Region aboveCoveredLayers;
Region dirty;
outDirtyRegion.clear();
mDrawingState.traverseInReverseZOrder([&](Layer* layer) {
// start with the whole surface at its current location
const Layer::State& s(layer->getDrawingState());
// only consider the layers on the given layer stack
if (!layer->belongsToDisplay(displayDevice->getLayerStack(), displayDevice->isPrimary()))
return;
/*
* opaqueRegion: area of a surface that is fully opaque.
*/
Region opaqueRegion;
/*
* visibleRegion: area of a surface that is visible on screen
* and not fully transparent. This is essentially the layer's
* footprint minus the opaque regions above it.
* Areas covered by a translucent surface are considered visible.
*/
Region visibleRegion;
/*
* coveredRegion: area of a surface that is covered by all
* visible regions above it (which includes the translucent areas).
*/
Region coveredRegion;
/*
* transparentRegion: area of a surface that is hinted to be completely
* transparent. This is only used to tell when the layer has no visible
* non-transparent regions and can be removed from the layer list. It
* does not affect the visibleRegion of this layer or any layers
* beneath it. The hint may not be correct if apps don't respect the
* SurfaceView restrictions (which, sadly, some don't).
*/
Region transparentRegion;
// handle hidden surfaces by setting the visible region to empty
if (CC_LIKELY(layer->isVisible())) {
const bool translucent = !layer->isOpaque(s);
Rect bounds(layer->computeScreenBounds());
visibleRegion.set(bounds);
Transform tr = layer->getTransform();
if (!visibleRegion.isEmpty()) {
// Remove the transparent area from the visible region
if (translucent) {
if (tr.preserveRects()) {
// transform the transparent region
transparentRegion = tr.transform(s.activeTransparentRegion);
} else {
// transformation too complex, can't do the
// transparent region optimization.
transparentRegion.clear();
}
}
// compute the opaque region
const int32_t layerOrientation = tr.getOrientation();
if (layer->getAlpha() == 1.0f && !translucent &&
((layerOrientation & Transform::ROT_INVALID) == false)) {
// the opaque region is the layer's footprint
opaqueRegion = visibleRegion;
}
}
}
if (visibleRegion.isEmpty()) {
layer->clearVisibilityRegions();
return;
}
// Clip the covered region to the visible region
coveredRegion = aboveCoveredLayers.intersect(visibleRegion);
// Update aboveCoveredLayers for next (lower) layer
aboveCoveredLayers.orSelf(visibleRegion);
// subtract the opaque region covered by the layers above us
visibleRegion.subtractSelf(aboveOpaqueLayers);
// compute this layer's dirty region
if (layer->contentDirty) {
// we need to invalidate the whole region
dirty = visibleRegion;
// as well, as the old visible region
dirty.orSelf(layer->visibleRegion);
layer->contentDirty = false;
} else {
/* compute the exposed region:
* the exposed region consists of two components:
* 1) what's VISIBLE now and was COVERED before
* 2) what's EXPOSED now less what was EXPOSED before
*
* note that (1) is conservative, we start with the whole
* visible region but only keep what used to be covered by
* something -- which mean it may have been exposed.
*
* (2) handles areas that were not covered by anything but got
* exposed because of a resize.
*/
const Region newExposed = visibleRegion - coveredRegion;
const Region oldVisibleRegion = layer->visibleRegion;
const Region oldCoveredRegion = layer->coveredRegion;
const Region oldExposed = oldVisibleRegion - oldCoveredRegion;
dirty = (visibleRegion&oldCoveredRegion) | (newExposed-oldExposed);
}
dirty.subtractSelf(aboveOpaqueLayers);
// accumulate to the screen dirty region
outDirtyRegion.orSelf(dirty);
// Update aboveOpaqueLayers for next (lower) layer
aboveOpaqueLayers.orSelf(opaqueRegion);
// Store the visible region in screen space
layer->setVisibleRegion(visibleRegion);
layer->setCoveredRegion(coveredRegion);
layer->setVisibleNonTransparentRegion(
visibleRegion.subtract(transparentRegion));
});
outOpaqueRegion = aboveOpaqueLayers;
}
要理解这段逻辑,我们首先要明白这四个参数什么:
- 1.opaqueRegion 不透明区域
- 2.visibleRegion 可见区域
- 3.coveredRegion 遮挡区域
- 4.transparentRegion 半透明区域
要弄懂这几个区域做了什么我们还需要看Layer的computeScreenBounds计算在屏幕中边缘的方法。
Layer computeScreenBounds
Rect Layer::computeScreenBounds(bool reduceTransparentRegion) const {
const Layer::State& s(getDrawingState());
Rect win(s.active.w, s.active.h);
if (!s.crop.isEmpty()) {
win.intersect(s.crop, &win);
}
Transform t = getTransform();
win = t.transform(win);
if (!s.finalCrop.isEmpty()) {
win.intersect(s.finalCrop, &win);
}
const sp& p = mDrawingParent.promote();
if (p != nullptr) {
Rect bounds = p->computeScreenBounds(false);
bounds.intersect(win, &win);
}
if (reduceTransparentRegion) {
auto const screenTransparentRegion = t.transform(s.activeTransparentRegion);
win = reduce(win, screenTransparentRegion);
}
return win;
}
reduceTransparentRegion默认是true。
-
- 获得当前GraphicBuffer的宽高进行裁剪
-
- 再根据父Layer的宽高对这段区域进行一次压缩处理。
-
- 还有一次finalCrop裁剪区域,在进行一次裁剪。
-
- 计算父Layer的的边缘,取父Layer和当前Layer的交集。
-
- activeTransparentRegion获取当前活跃的透明区域,把当前这个已经裁剪过的win区域剪掉,剪掉所有透明的区域。
这个步骤用图画出来会好理解
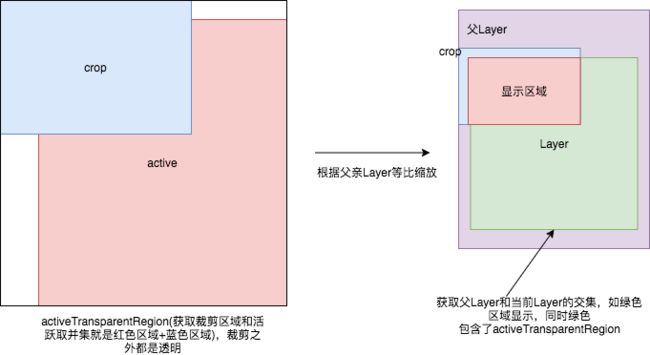
最后红色的区域就是Layer 的边缘大小。
computeVisibleRegions 计算原理
直到每一个的Layer是怎么计算的,我们再来看看每一个Layer是怎么deviceDisplay和计算显示区域的。
- 1.如果判读到Layer可以显示透明则把整个区域设置回activeTransparentRegion。
- 2.如果Layer的getAlpha是1.0,就是完全不透明,则opaqueRegion = 可视区域visibleRegion。
- 3.visibleRegion总区域则是把每一层Layer的visibleRegion都取并集。
- 4.coveredRegion 的区域则是取每一层Layer的visibleRegion的交集。
用一幅图表示,红色代表coveredRegion,蓝色代表visibleRegion
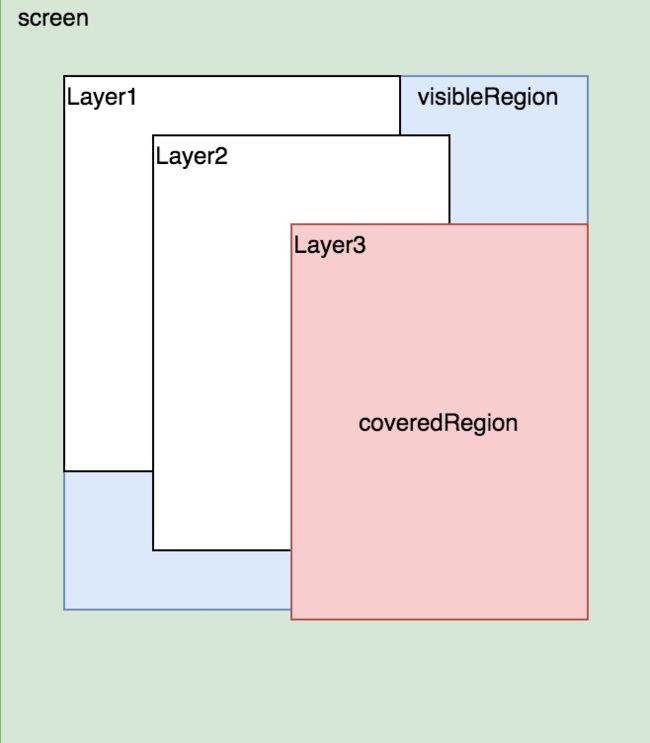
最后都保存在DisplayDevice中。
setUpHWComposer HWC的渲染或者HWC的准备
void SurfaceFlinger::setUpHWComposer() {
for (size_t dpy=0 ; dpygetDirtyRegion(mRepaintEverything).isEmpty();
bool empty = mDisplays[dpy]->getVisibleLayersSortedByZ().size() == 0;
bool wasEmpty = !mDisplays[dpy]->lastCompositionHadVisibleLayers;
bool mustRecompose = dirty && !(empty && wasEmpty);
mDisplays[dpy]->beginFrame(mustRecompose);
if (mustRecompose) {
mDisplays[dpy]->lastCompositionHadVisibleLayers = !empty;
}
}
// build the h/w work list
if (CC_UNLIKELY(mGeometryInvalid)) {
mGeometryInvalid = false;
for (size_t dpy=0 ; dpy displayDevice(mDisplays[dpy]);
const auto hwcId = displayDevice->getHwcDisplayId();
if (hwcId >= 0) {
const Vector>& currentLayers(
displayDevice->getVisibleLayersSortedByZ());
for (size_t i = 0; i < currentLayers.size(); i++) {
const auto& layer = currentLayers[i];
if (!layer->hasHwcLayer(hwcId)) {
if (!layer->createHwcLayer(getBE().mHwc.get(), hwcId)) {
layer->forceClientComposition(hwcId);
continue;
}
}
layer->setGeometry(displayDevice, i);
if (mDebugDisableHWC || mDebugRegion) {
layer->forceClientComposition(hwcId);
}
}
}
}
}
// Set the per-frame data
for (size_t displayId = 0; displayId < mDisplays.size(); ++displayId) {
auto& displayDevice = mDisplays[displayId];
const auto hwcId = displayDevice->getHwcDisplayId();
if (hwcId < 0) {
continue;
}
if (mDrawingState.colorMatrixChanged) {
displayDevice->setColorTransform(mDrawingState.colorMatrix);
status_t result = getBE().mHwc->setColorTransform(hwcId, mDrawingState.colorMatrix);
}
for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) {
if (layer->isHdrY410()) {
layer->forceClientComposition(hwcId);
} else if ((layer->getDataSpace() == Dataspace::BT2020_PQ ||
layer->getDataSpace() == Dataspace::BT2020_ITU_PQ) &&
!displayDevice->hasHDR10Support()) {
layer->forceClientComposition(hwcId);
} else if ((layer->getDataSpace() == Dataspace::BT2020_HLG ||
layer->getDataSpace() == Dataspace::BT2020_ITU_HLG) &&
!displayDevice->hasHLGSupport()) {
layer->forceClientComposition(hwcId);
}
if (layer->getForceClientComposition(hwcId)) {
layer->setCompositionType(hwcId, HWC2::Composition::Client);
continue;
}
layer->setPerFrameData(displayDevice);
}
if (hasWideColorDisplay) {
....
}
}
mDrawingState.colorMatrixChanged = false;
for (size_t displayId = 0; displayId < mDisplays.size(); ++displayId) {
auto& displayDevice = mDisplays[displayId];
if (!displayDevice->isDisplayOn()) {
continue;
}
status_t result = displayDevice->prepareFrame(*getBE().mHwc);
}
}
大致分为四个步骤:
- 1.遍历每一个DisplayDevice调用beginFrame方法,准备绘制图元。
- 2.遍历每一个DisplayDevice先判断他的色彩空间。并且设置颜色矩阵。接着获取DisplayDevice中需要绘制的Layer,检查是否创建了hwcLayer,没有则创建,创建失败则设置forceClientComposition,强制设置为Client渲染模式,进行OpenGL es渲染。最后调用setGeometry。
- 3.遍历每一个DisplayDevice,根据DataSpace,进一步处理是否需要强制使用Client渲染模式,最后调用layer的setPerFrameData方法。
- 4.遍历每一个DisplayDevice,调用prepareFrame。
注意,从这一步开始,我们可以把渲染机制大致分为如下两类:
- 1.HWC 合成
- 2.OpenGL es 合成
有了两种渲染机制,那么对应的就会有两种对应渲染的准备。而setUpHWComposer方法就是进行这两种渲染环境的准备。其中setPerFrameData将会设置从latch过程中保存的图元传输到Hal层。而OpenGL es相关的渲染环境因为绑定了OpenGL es的特殊性,所以这个方法其实就是在准备HWC渲染的环境。
DisplayDevice beginFrame
文件:/frameworks/native/services/surfaceflinger/DisplayDevice.cpp
status_t DisplayDevice::beginFrame(bool mustRecompose) const {
return mDisplaySurface->beginFrame(mustRecompose);
}
mDisplaySurface实际上就是我第一篇在初始化和你们聊到过的FrameBufferSurface。
文件:frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cpp
status_t FramebufferSurface::beginFrame(bool /*mustRecompose*/) {
return NO_ERROR;
}
实际上没有做什么事情。
Layer createHwcLayer 创建HwcLayer
bool Layer::createHwcLayer(HWComposer* hwc, int32_t hwcId) {
HWC2::Layer* layer = hwc->createLayer(hwcId);
if (!layer) {
return false;
}
LayerBE::HWCInfo& hwcInfo = getBE().mHwcLayers[hwcId];
hwcInfo.hwc = hwc;
hwcInfo.layer = layer;
layer->setLayerDestroyedListener(
[this, hwcId](HWC2::Layer* /*layer*/) { getBE().mHwcLayers.erase(hwcId); });
return true;
}
核心是调用了HWComposer的createLayer方法,在底层Hal层生成一个对应的Layer对象。
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
HWC2::Layer* HWComposer::createLayer(int32_t displayId) {
RETURN_IF_INVALID_DISPLAY(displayId, nullptr);
auto display = mDisplayData[displayId].hwcDisplay;
HWC2::Layer* layer;
auto error = display->createLayer(&layer);
RETURN_IF_HWC_ERROR(error, displayId, nullptr);
return layer;
}
此时会调用Display的createLayer方法。
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/HWC2.cpp
Error Display::createLayer(Layer** outLayer)
{
if (!outLayer) {
return Error::BadParameter;
}
hwc2_layer_t layerId = 0;
auto intError = mComposer.createLayer(mId, &layerId);
auto error = static_cast(intError);
if (error != Error::None) {
return error;
}
auto layer = std::make_unique(
mComposer, mCapabilities, mId, layerId);
*outLayer = layer.get();
mLayers.emplace(layerId, std::move(layer));
return Error::None;
}
此时能看到最后会通过Hal层生成一个Layer,并且用hwc2_layer_t id进行标记句柄。
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/ComposerHal.cpp
Error Composer::createLayer(Display display, Layer* outLayer)
{
Error error = kDefaultError;
mClient->createLayer(display, BufferQueue::NUM_BUFFER_SLOTS,
[&](const auto& tmpError, const auto& tmpLayer) {
error = tmpError;
if (error != Error::NONE) {
return;
}
*outLayer = tmpLayer;
});
return error;
}
接下来就到了Hal层中进行申请。
Hal层创建Layer
文件:/hardware/interfaces/graphics/composer/2.1/utils/hwc2on1adapter/HWC2On1Adapter.cpp
Error HWC2On1Adapter::Display::createLayer(hwc2_layer_t* outLayerId) {
std::unique_lock lock(mStateMutex);
auto layer = *mLayers.emplace(std::make_shared(*this));
mDevice.mLayers.emplace(std::make_pair(layer->getId(), layer));
*outLayerId = layer->getId();
markGeometryChanged();
return Error::None;
}
此时会在底层new一个Layer对象。并且保存在Display中的mLayers集合以及HWC2On1Adapter中。
SF setGeometry
文件:/frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void Layer::setGeometry(const sp& displayDevice, uint32_t z)
{
const auto hwcId = displayDevice->getHwcDisplayId();
auto& hwcInfo = getBE().mHwcLayers[hwcId];
// enable this layer
hwcInfo.forceClientComposition = false;
if (isSecure() && !displayDevice->isSecure()) {
hwcInfo.forceClientComposition = true;
}
auto& hwcLayer = hwcInfo.layer;
const State& s(getDrawingState());
auto blendMode = HWC2::BlendMode::None;
if (!isOpaque(s) || getAlpha() != 1.0f) {
blendMode =
mPremultipliedAlpha ? HWC2::BlendMode::Premultiplied : HWC2::BlendMode::Coverage;
}
auto error = hwcLayer->setBlendMode(blendMode);
Region activeTransparentRegion(s.activeTransparentRegion);
Transform t = getTransform();
if (!s.crop.isEmpty()) {
Rect activeCrop(s.crop);
activeCrop = t.transform(activeCrop);
if (!activeCrop.intersect(displayDevice->getViewport(), &activeCrop)) {
activeCrop.clear();
}
activeCrop = t.inverse().transform(activeCrop, true);
if (!activeCrop.intersect(Rect(s.active.w, s.active.h), &activeCrop)) {
activeCrop.clear();
}
// mark regions outside the crop as transparent
activeTransparentRegion.orSelf(Rect(0, 0, s.active.w, activeCrop.top));
activeTransparentRegion.orSelf(Rect(0, activeCrop.bottom, s.active.w, s.active.h));
activeTransparentRegion.orSelf(Rect(0, activeCrop.top, activeCrop.left, activeCrop.bottom));
activeTransparentRegion.orSelf(
Rect(activeCrop.right, activeCrop.top, s.active.w, activeCrop.bottom));
}
Rect frame{t.transform(computeBounds(activeTransparentRegion))};
if (!s.finalCrop.isEmpty()) {
if (!frame.intersect(s.finalCrop, &frame)) {
frame.clear();
}
}
if (!frame.intersect(displayDevice->getViewport(), &frame)) {
frame.clear();
}
const Transform& tr(displayDevice->getTransform());
Rect transformedFrame = tr.transform(frame);
error = hwcLayer->setDisplayFrame(transformedFrame);
if (error != HWC2::Error::None) {
...
} else {
hwcInfo.displayFrame = transformedFrame;
}
FloatRect sourceCrop = computeCrop(displayDevice);
error = hwcLayer->setSourceCrop(sourceCrop);
if (error != HWC2::Error::None) {
...
} else {
hwcInfo.sourceCrop = sourceCrop;
}
float alpha = static_cast(getAlpha());
error = hwcLayer->setPlaneAlpha(alpha);
error = hwcLayer->setZOrder(z);
int type = s.type;
int appId = s.appId;
sp parent = mDrawingParent.promote();
if (parent.get()) {
auto& parentState = parent->getDrawingState();
if (parentState.type >= 0 || parentState.appId >= 0) {
type = parentState.type;
appId = parentState.appId;
}
}
error = hwcLayer->setInfo(type, appId);
const Transform bufferOrientation(mCurrentTransform);
Transform transform(tr * t * bufferOrientation);
if (getTransformToDisplayInverse()) {
uint32_t invTransform = DisplayDevice::getPrimaryDisplayOrientationTransform();
// calculate the inverse transform
if (invTransform & NATIVE_WINDOW_TRANSFORM_ROT_90) {
invTransform ^= NATIVE_WINDOW_TRANSFORM_FLIP_V | NATIVE_WINDOW_TRANSFORM_FLIP_H;
}
transform = Transform(invTransform) * tr * bufferOrientation;
}
const uint32_t orientation = transform.getOrientation();
if (orientation & Transform::ROT_INVALID) {
hwcInfo.forceClientComposition = true;
} else {
auto transform = static_cast(orientation);
hwcInfo.transform = transform;
auto error = hwcLayer->setTransform(transform);
}
}
setGeometry方法设置其实就是设置activeTransparentRegion的区域。并把它设置到hwcLayer中,在Hal层中记录整个需要显示的区域。
BufferLayer setPerFrameData
文件:/frameworks/native/services/surfaceflinger/BufferLayer.cpp
void BufferLayer::setPerFrameData(const sp& displayDevice) {
const Transform& tr = displayDevice->getTransform();
const auto& viewport = displayDevice->getViewport();
Region visible = tr.transform(visibleRegion.intersect(viewport));
auto hwcId = displayDevice->getHwcDisplayId();
auto& hwcInfo = getBE().mHwcLayers[hwcId];
auto& hwcLayer = hwcInfo.layer;
auto error = hwcLayer->setVisibleRegion(visible);
...
error = hwcLayer->setSurfaceDamage(surfaceDamageRegion);
...
// Sideband layers
...
// Device or Cursor layers
if (mPotentialCursor) {
setCompositionType(hwcId, HWC2::Composition::Cursor);
} else {
setCompositionType(hwcId, HWC2::Composition::Device);
}
error = hwcLayer->setDataspace(mCurrentDataSpace);
...
const HdrMetadata& metadata = mConsumer->getCurrentHdrMetadata();
error = hwcLayer->setPerFrameMetadata(displayDevice->getSupportedPerFrameMetadata(), metadata);
...
uint32_t hwcSlot = 0;
sp hwcBuffer;
hwcInfo.bufferCache.getHwcBuffer(getBE().compositionInfo.mBufferSlot,
getBE().compositionInfo.mBuffer, &hwcSlot, &hwcBuffer);
auto acquireFence = mConsumer->getCurrentFence();
error = hwcLayer->setBuffer(hwcSlot, hwcBuffer, acquireFence);
...
}
这个方法做了HWC渲染最重要的准备。
- 1.调用hwcLayer的setSurfaceDamage,记录OpenGL es绘制时候需要更新的已经变动的渲染区域
- 2.根据创建Surface时候传进来的flag进行设置接下来渲染类型进而确定使用什么进行渲染。一般正常创建,flag为0,mPotentialCursor为false,此时就被设置为Device,也就是借助HWC进行渲染。
- 3.setDataspace 设置色彩空间。
- 4.通过latchBuffer步骤,把当前的需要渲染的Buffer保存在getBE().compositionInfo中取出,设置到hwcInfo的缓存中,并且设置给hwcBuffer。最后把这个GraphicBuffer和Fence保存到hwcLayer中。
hwcLayer setBuffer
Error HWC2On1Adapter::Layer::setBuffer(buffer_handle_t buffer,
int32_t acquireFence) {
ALOGV("Setting acquireFence to %d for layer %" PRIu64, acquireFence, mId);
mBuffer.setBuffer(buffer);
mBuffer.setFence(acquireFence);
return Error::None;
}
mBuffer实际上就是FenceBuffer。里面保存了Fence和Buffer。
DisplayDevice prepareFrame
文件:/frameworks/native/services/surfaceflinger/DisplayDevice.cpp
status_t DisplayDevice::prepareFrame(HWComposer& hwc) {
status_t error = hwc.prepare(*this);
if (error != NO_ERROR) {
return error;
}
DisplaySurface::CompositionType compositionType;
bool hasClient = hwc.hasClientComposition(mHwcDisplayId);
bool hasDevice = hwc.hasDeviceComposition(mHwcDisplayId);
if (hasClient && hasDevice) {
compositionType = DisplaySurface::COMPOSITION_MIXED;
} else if (hasClient) {
compositionType = DisplaySurface::COMPOSITION_GLES;
} else if (hasDevice) {
compositionType = DisplaySurface::COMPOSITION_HWC;
} else {
compositionType = DisplaySurface::COMPOSITION_HWC;
}
return mDisplaySurface->prepareFrame(compositionType);
}
在这里面做了两件事情:
- 1.HWComposer prepare hwc进行渲染工作
- 2.FrameBufferSurface prepareFrame 准备OpenGL es渲染到屏幕的工作
HWC 进行渲染准备工作
我们先来看看hwc的prepare方法
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/HWComposer.cpp
status_t HWComposer::prepare(DisplayDevice& displayDevice) {
Mutex::Autolock _l(mDisplayLock);
auto displayId = displayDevice.getHwcDisplayId();
auto& displayData = mDisplayData[displayId];
auto& hwcDisplay = displayData.hwcDisplay;
uint32_t numTypes = 0;
uint32_t numRequests = 0;
HWC2::Error error = HWC2::Error::None;
displayData.validateWasSkipped = false;
if (!displayData.hasClientComposition) {
sp outPresentFence;
uint32_t state = UINT32_MAX;
error = hwcDisplay->presentOrValidate(&numTypes, &numRequests, &outPresentFence , &state);
if (state == 1) { //Present Succeeded.
std::unordered_map> releaseFences;
error = hwcDisplay->getReleaseFences(&releaseFences);
displayData.releaseFences = std::move(releaseFences);
displayData.lastPresentFence = outPresentFence;
displayData.validateWasSkipped = true;
displayData.presentError = error;
return NO_ERROR;
}
// Present failed but Validate ran.
} else {
error = hwcDisplay->validate(&numTypes, &numRequests);
}
std::unordered_map changedTypes;
changedTypes.reserve(numTypes);
error = hwcDisplay->getChangedCompositionTypes(&changedTypes);
displayData.displayRequests = static_cast(0);
std::unordered_map layerRequests;
layerRequests.reserve(numRequests);
error = hwcDisplay->getRequests(&displayData.displayRequests,
&layerRequests);
displayData.hasClientComposition = false;
displayData.hasDeviceComposition = false;
for (auto& layer : displayDevice.getVisibleLayersSortedByZ()) {
auto hwcLayer = layer->getHwcLayer(displayId);
if (changedTypes.count(hwcLayer) != 0) {
validateChange(layer->getCompositionType(displayId),
changedTypes[hwcLayer]);
layer->setCompositionType(displayId, changedTypes[hwcLayer], false);
}
switch (layer->getCompositionType(displayId)) {
case HWC2::Composition::Client:
displayData.hasClientComposition = true;
break;
case HWC2::Composition::Device:
case HWC2::Composition::SolidColor:
case HWC2::Composition::Cursor:
case HWC2::Composition::Sideband:
displayData.hasDeviceComposition = true;
break;
default:
break;
}
if (layerRequests.count(hwcLayer) != 0 &&
layerRequests[hwcLayer] ==
HWC2::LayerRequest::ClearClientTarget) {
layer->setClearClientTarget(displayId, true);
} else {
if (layerRequests.count(hwcLayer) != 0) {
}
layer->setClearClientTarget(displayId, false);
}
}
error = hwcDisplay->acceptChanges();
return NO_ERROR;
}
这里面做了两件事情:
-
- 校验在HWC中缓存的mDisplayData中缓存缓存的数据。这个mDisplayData实际上就是每一次热插拔的时候会为mDisplayData中新增一个缓存(详细请看第一篇)。当发现此时需要渲染的displayID对应的屏幕的渲染模式是非Client模式,则会直接通过调用HWC::Diaplay的presentOrValidate方法进行HWC校验后进行HWC的渲染显示。
- 2.但是如果是Client模式,则说明需要后续的渲染步骤进行OpenGL es渲染。此时只会进行HWC::Display的validate的校验。同时遍历寻找可显示的Layer中hwcLayer,并且设置为相应的type,同时记录在SF的Layer中。
其实这里面做的事情需要和createLayer进行一次联动。当createLayer成功了说明允许进行HWC的渲染。但是如果HWC创建Layer失败了,则会强制设置为Client模式进行OpenGL es渲染。
但是这个时候还不够确定,在setUpHWComposer步骤最后一个循环中,就会进一步通过HWC确认具体的模式。
如果之前关闭了mDisplayDtata之前就关闭了Client模式。则会默认走非Client模式进行HWC渲染。否则的话将会getChangedCompositionTypes方法获取在hwcDisplay中已经模式变化的display统一设置到Layer中。
最后将会调用acceptChanges,把底层的mChanges集合更新。
那么让我们看看HWC渲染的核心流程对应的方法presentOrValidate。
HWC::Display presentOrValidate HWC的渲染准备
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/HWC2.cpp
Error Display::presentOrValidate(uint32_t* outNumTypes, uint32_t* outNumRequests,
sp* outPresentFence, uint32_t* state) {
uint32_t numTypes = 0;
uint32_t numRequests = 0;
int32_t presentFenceFd = -1;
auto intError = mComposer.presentOrValidateDisplay(
mId, &numTypes, &numRequests, &presentFenceFd, state);
auto error = static_cast(intError);
if (error != Error::None && error != Error::HasChanges) {
return error;
}
if (*state == 1) {
*outPresentFence = new Fence(presentFenceFd);
}
if (*state == 0) {
*outNumTypes = numTypes;
*outNumRequests = numRequests;
}
return error;
}
核心是mComposer的presentOrValidateDisplay方法。mComposer就是ComposerHal沟通Hal层的对象。
ComposerHal presentOrValidateDisplay
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/ComposerHal.cpp
Error Composer::presentOrValidateDisplay(Display display, uint32_t* outNumTypes,
uint32_t* outNumRequests, int* outPresentFence, uint32_t* state) {
mWriter.selectDisplay(display);
mWriter.presentOrvalidateDisplay();
Error error = execute();
if (error != Error::NONE) {
return error;
}
mReader.takePresentOrValidateStage(display, state);
if (*state == 1) { // Present succeeded
mReader.takePresentFence(display, outPresentFence);
}
if (*state == 0) { // Validate succeeded.
mReader.hasChanges(display, outNumTypes, outNumRequests);
}
return Error::NONE;
}
这里面出现两个Hal层的对象,ComposerWriter和ComposerReader。这两者实际上就是围绕着ComposerCommandEngine进行读写。
- 1.ComposerWriter依次调用selectDisplay和presentOrvalidateDisplay把数据写在底层。
- 2.再通过execute执行输入到ComposerCommandEngine中。
- 3.执行结束后,通过ComposerReader把结果读出来。
这两个对象,我就不细说,在SF的Hal层初始化有提到过。这里就列出三者之间的关系。
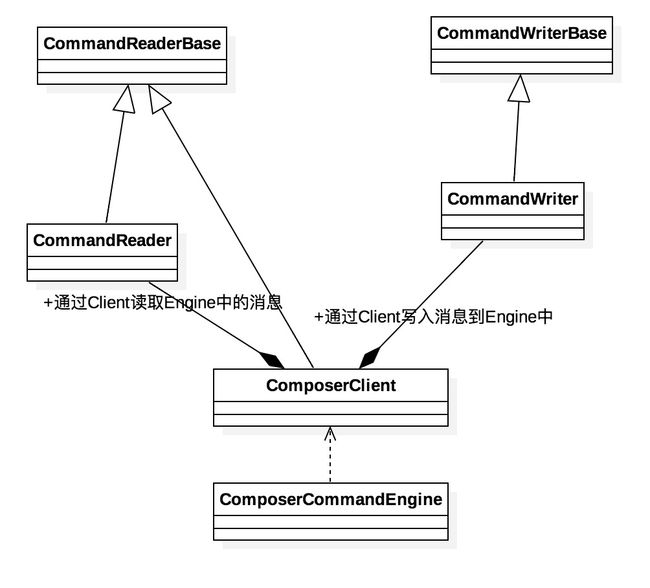
其详细的设计就不解析,其实很简单。ComposerWriter写到一个mData的数据数组中,不足则按照初始长度的两倍进行扩容。execute将会调用ComposerClient的execute方法,输入这些数据并且进行执行。执行完毕后,通过reader读出。有兴趣的读者,可以去读一读。
我们着重来看看ComposerCommandEngine对应presentOrvalidateDisplay执行了什么。
ComposerCommandEngine presentOrvalidateDisplay
文件:/hardware/interfaces/graphics/composer/2.1/utils/hal/include/composer-hal/2.1/ComposerCommandEngine.h
bool executePresentOrValidateDisplay(uint16_t length) {
if (length != CommandWriterBase::kPresentOrValidateDisplayLength) {
return false;
}
// First try to Present as is.
if (mHal->hasCapability(HWC2_CAPABILITY_SKIP_VALIDATE)) {
int presentFence = -1;
std::vector layers;
std::vector fences;
auto err = mHal->presentDisplay(mCurrentDisplay, &presentFence, &layers, &fences);
if (err == Error::NONE) {
mWriter.setPresentOrValidateResult(1);
mWriter.setPresentFence(presentFence);
mWriter.setReleaseFences(layers, fences);
return true;
}
}
// Present has failed. We need to fallback to validate
std::vector changedLayers;
std::vector compositionTypes;
uint32_t displayRequestMask = 0x0;
std::vector requestedLayers;
std::vector requestMasks;
auto err = mHal->validateDisplay(mCurrentDisplay, &changedLayers, &compositionTypes,
&displayRequestMask, &requestedLayers, &requestMasks);
if (err == Error::NONE) {
mWriter.setPresentOrValidateResult(0);
mWriter.setChangedCompositionTypes(changedLayers, compositionTypes);
mWriter.setDisplayRequests(displayRequestMask, requestedLayers, requestMasks);
} else {
mWriter.setError(getCommandLoc(), err);
}
return true;
}
两件核心的事情:
- 1.如果在Hal层中的mCapability中包含了HWC2_CAPABILITY_SKIP_VALIDATE这个属性,说明此时可以跳过验证,直接进行present显示的标志位。这种一个是在特殊的设备中才有的,如msm8996等。他们不关心校验,直接在这一步中进行刷新屏幕的显示。所以presentDisplay实际上就是HWC刷新屏幕的核心方法。换句话mCapability集合,在Hal层中决定了Display的行为能力。说在这里我们先放下,后文会有介绍。
- 2.validateDisplay 就是校验屏幕,并且准备刷新屏幕需要的Hal层数据。
validateDisplay 会调用HWC2On1Adapter的我们直接看对应的核心方法validate。
HWC2On1Adapter::Display::validate
文件:/hardware/interfaces/graphics/composer/2.1/utils/hwc2on1adapter/HWC2On1Adapter.cpp
Error HWC2On1Adapter::Display::validate(uint32_t* outNumTypes,
uint32_t* outNumRequests) {
std::unique_lock lock(mStateMutex);
if (!mChanges) {
if (!mDevice.prepareAllDisplays()) {
return Error::BadDisplay;
}
} else {
}
*outNumTypes = mChanges->getNumTypes();
*outNumRequests = mChanges->getNumLayerRequests();
...
return *outNumTypes > 0 ? Error::HasChanges : Error::None;
}
mChanges不为空,换句话说,一般都会执行prepareAllDisplays方法,更新了mChanges集合之后就会返回。
HWC2On1Adapter::prepareAllDisplay
bool HWC2On1Adapter::prepareAllDisplays() {
std::unique_lock lock(mStateMutex);
for (const auto& displayPair : mDisplays) {
auto& display = displayPair.second;
if (!display->prepare()) {
return false;
}
}
if (mHwc1DisplayMap.count(HWC_DISPLAY_PRIMARY) == 0) {
return false;
}
mHwc1Contents.clear();
auto primaryDisplayId = mHwc1DisplayMap[HWC_DISPLAY_PRIMARY];
auto& primaryDisplay = mDisplays[primaryDisplayId];
mHwc1Contents.push_back(primaryDisplay->getDisplayContents());
if (mHwc1DisplayMap.count(HWC_DISPLAY_EXTERNAL) != 0) {
...
} else {
mHwc1Contents.push_back(nullptr);
}
if (mHwc1MinorVersion >= 3) {
if (mHwc1DisplayMap.count(HWC_DISPLAY_VIRTUAL) != 0) {
...
} else {
mHwc1Contents.push_back(nullptr);
}
}
{
mHwc1Device->prepare(mHwc1Device, mHwc1Contents.size(),
mHwc1Contents.data());
}
....
for (size_t hwc1Id = 0; hwc1Id < mHwc1Contents.size(); ++hwc1Id) {
if (mHwc1Contents[hwc1Id] == nullptr) {
continue;
}
auto displayId = mHwc1DisplayMap[hwc1Id];
auto& display = mDisplays[displayId];
display->generateChanges();
}
return true;
}
- 1.调用每一个保存在HWC2On1Adapter中的display的prepare方法
- 2.getDisplayContents获取主屏幕需要显示的数据保存在mHwc1Contents,这个数据实际上就是在prepare中准备的。
- 3.调用硬件设备的mHwc1Device->prepare方法,告诉硬件准备渲染了。
- 4.遍历每一个display的generateChanges,刷新里面的mChanges集合。
HWC2On1Adapter::Display::prepare
bool HWC2On1Adapter::Display::prepare() {
std::unique_lock lock(mStateMutex);
...
allocateRequestedContents();
assignHwc1LayerIds();
mHwc1RequestedContents->retireFenceFd = -1;
mHwc1RequestedContents->flags = 0;
if (mGeometryChanged) {
mHwc1RequestedContents->flags |= HWC_GEOMETRY_CHANGED;
}
mHwc1RequestedContents->outbuf = mOutputBuffer.getBuffer();
mHwc1RequestedContents->outbufAcquireFenceFd = mOutputBuffer.getFence();
// +1 is for framebuffer target layer.
mHwc1RequestedContents->numHwLayers = mLayers.size() + 1;
for (auto& layer : mLayers) {
auto& hwc1Layer = mHwc1RequestedContents->hwLayers[layer->getHwc1Id()];
hwc1Layer.releaseFenceFd = -1;
hwc1Layer.acquireFenceFd = -1;
layer->applyState(hwc1Layer);
}
prepareFramebufferTarget();
resetGeometryMarker();
return true;
}
1.allocateRequestedContents 初始化hwc需要显示的数据结构体hwc_display_contents_1_t。mHwc1RequestedContents 这个数据结构将会包裹hwc_display_contents_1_t数据。
2.初始化mHwc1RequestedContents对象,设置输出到真正渲染硬件so的outbuf,outbufAcquireFenceFd(有的硬件不会使用)。核心下面那个循环,会获取Display的Layer集合,遍历每一个Layer.applyState给mHwc1RequestedContents中的hwcLayer进行赋值。如本次需要绘制的图元。
void HWC2On1Adapter::Layer::applyState(hwc_layer_1_t& hwc1Layer) {
applyCommonState(hwc1Layer);
applyCompositionType(hwc1Layer);
switch (mCompositionType) {
case Composition::SolidColor : applySolidColorState(hwc1Layer); break;
case Composition::Sideband : applySidebandState(hwc1Layer); break;
default: applyBufferState(hwc1Layer); break;
}
}
void HWC2On1Adapter::Layer::applyBufferState(hwc_layer_1_t& hwc1Layer) {
hwc1Layer.handle = mBuffer.getBuffer();
hwc1Layer.acquireFenceFd = mBuffer.getFence();
}
void HWC2On1Adapter::Layer::applyCompositionType(hwc_layer_1_t& hwc1Layer) {
if (mHasUnsupportedPlaneAlpha || mDisplay.hasColorTransform() ||
hasUnsupportedBackgroundColor()) {
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
hwc1Layer.flags = HWC_SKIP_LAYER;
return;
}
hwc1Layer.flags = 0;
switch (mCompositionType) {
case Composition::Client:
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
hwc1Layer.flags |= HWC_SKIP_LAYER;
break;
case Composition::Device:
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
break;
case Composition::SolidColor:
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
hwc1Layer.flags |= HWC_SKIP_LAYER;
break;
case Composition::Cursor:
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
if (mDisplay.getDevice().getHwc1MinorVersion() >= 4) {
hwc1Layer.hints |= HWC_IS_CURSOR_LAYER;
}
break;
case Composition::Sideband:
if (mDisplay.getDevice().getHwc1MinorVersion() < 4) {
hwc1Layer.compositionType = HWC_SIDEBAND;
} else {
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
hwc1Layer.flags |= HWC_SKIP_LAYER;
}
break;
default:
hwc1Layer.compositionType = HWC_FRAMEBUFFER;
hwc1Layer.flags |= HWC_SKIP_LAYER;
break;
}
}
能看到这里的mBuffer就是上文中进行setPerFrame缓存下来的GraphicBuffer对象。这样就准备好了在HWC中需要绘制的图元对象。同时把每一个Layer中的compositionType统一设置为HWC_FRAMEBUFFER,目的是为了尽可能使用fb驱动进行绘制。
硬件层的初始化和prepare
硬件层的初始化回顾
在聊准备工作之前,我们需要先对msm8960的初始化重新梳理一遍之前忽略的方法,在之前的文章,介绍Hal层的初始化时候,有介绍到在硬件进行初始化方法:
static int hwc_device_open(const struct hw_module_t* module, const char* name,
struct hw_device_t** device)
{
int status = -EINVAL;
if (!strcmp(name, HWC_HARDWARE_COMPOSER)) {
struct hwc_context_t *dev;
dev = (hwc_context_t*)malloc(sizeof(*dev));
memset(dev, 0, sizeof(*dev));
initContext(dev);
//Setup HWC methods
dev->device.common.tag = HARDWARE_DEVICE_TAG;
...
}
return status;
}
在initContext方法中初始化了很多核心的参数。我们从msm8960来一探HWC的初始化究竟。
initContext
void initContext(hwc_context_t *ctx)
{
if(openFramebufferDevice(ctx) < 0) {
}
overlay::Overlay::initOverlay();
ctx->mOverlay = overlay::Overlay::getInstance();
ctx->mRotMgr = new RotMgr();
ctx->mMDP.version = qdutils::MDPVersion::getInstance().getMDPVersion();
ctx->mMDP.hasOverlay = qdutils::MDPVersion::getInstance().hasOverlay();
ctx->mMDP.panel = qdutils::MDPVersion::getInstance().getPanelType();
overlay::Overlay::initOverlay();
ctx->mOverlay = overlay::Overlay::getInstance();
ctx->mRotMgr = new RotMgr();
ctx->mFBUpdate[HWC_DISPLAY_PRIMARY] =
IFBUpdate::getObject(ctx->dpyAttr[HWC_DISPLAY_PRIMARY].xres,
HWC_DISPLAY_PRIMARY);
int compositionType =
qdutils::QCCompositionType::getInstance().getCompositionType();
if (compositionType & (qdutils::COMPOSITION_TYPE_DYN |
qdutils::COMPOSITION_TYPE_MDP |
qdutils::COMPOSITION_TYPE_C2D)) {
ctx->mCopyBit[HWC_DISPLAY_PRIMARY] = new CopyBit();
}
...
ctx->mMDPComp[HWC_DISPLAY_PRIMARY] =
MDPComp::getObject(ctx->dpyAttr[HWC_DISPLAY_PRIMARY].xres,
HWC_DISPLAY_PRIMARY);
MDPComp::init(ctx);
ctx->vstate.enable = false;
ctx->vstate.fakevsync = false;
ctx->mExtDispConfiguring = false;
ctx->mBasePipeSetup = false;
QService::init();
sp client = new QClient(ctx);
interface_cast(
defaultServiceManager()->getService(
String16("display.qservice")))->connect(client);
connectPPDaemon(ctx);
}
- 1.openFramebufferDevice 初始化dev,并且关联到fb驱动。
- 2.初始化Overlay 对象
- 3.根据主屏幕参数初始化mFBUpdate数组中FBUpdate对象。
- 4.初始化mCopyBit 像素缓存对象
- 5.初始化MDPComp数组中MDP对象,以及MDP模块的init判断MDP是否开启
- 6.初始化QService和QClient。
- 7.连通守护线程
openFramebufferDevice
static int openFramebufferDevice(hwc_context_t *ctx)
{
struct fb_fix_screeninfo finfo;
struct fb_var_screeninfo info;
int fb_fd = openFb(HWC_DISPLAY_PRIMARY);
if (ioctl(fb_fd, FBIOGET_VSCREENINFO, &info) == -1)
return -errno;
if (int(info.width) <= 0 || int(info.height) <= 0) {
// the driver doesn't return that information
// default to 160 dpi
info.width = ((info.xres * 25.4f)/160.0f + 0.5f);
info.height = ((info.yres * 25.4f)/160.0f + 0.5f);
}
float xdpi = (info.xres * 25.4f) / info.width;
float ydpi = (info.yres * 25.4f) / info.height;
....
if (ioctl(fb_fd, FBIOGET_FSCREENINFO, &finfo) == -1)
return -errno;
if (finfo.smem_len <= 0)
return -errno;
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].fd = fb_fd;
//xres, yres may not be 32 aligned
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].stride = finfo.line_length /(info.xres/8);
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].xres = info.xres;
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].yres = info.yres;
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].xdpi = xdpi;
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].ydpi = ydpi;
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].vsync_period = 1000000000l / fps;
if(ioctl(fb_fd, FBIOBLANK,FB_BLANK_UNBLANK) < 0) {
ALOGE("%s: Failed to unblank display", __FUNCTION__);
return -errno;
}
ctx->dpyAttr[HWC_DISPLAY_PRIMARY].isActive = true;
return 0;
}
- 1.openFb先打开fb驱动
- 2.向fb发送消息FBIOGET_VSCREENINFO ,获取屏幕可变信息,如分辨率,宽高,颜色属性
- 3.向fb发送FBIOGET_FSCREENINFO,获取屏幕不变信息,如帧缓冲长度,加速标志位,扫描线长度等。最后全部赋值给dpyAttr数组缓存下来,包括fd句柄。
- 4.向fb驱动发送FB_BLANK_UNBLANK ,点亮屏幕。
从这里我们可以知道,实际上xres和yres是指上是指x轴和y轴对应的dpi,屏幕像素密度。
初始化FBUpdate对象
文件:/hardware/qcom/display/msm8960/libhwcomposer/hwc_fbupdate.cpp
在msm8960中,会根据屏幕返回的xres,x轴的像素像素资源大小超过2048则会使用高密度的FBUpdateHighRes来承载像素,否则则会FBUpdateLowRes承载。
一般来说,我们的手机FBUpdateLowRes承载,TV这些就会使用FBUpdateHighRes承载。
#define MAX_DISPLAY_DIM 2048
IFBUpdate* IFBUpdate::getObject(const int& width, const int& dpy) {
if(width > MAX_DISPLAY_DIM) {
return new FBUpdateHighRes(dpy);
}
return new FBUpdateLowRes(dpy);
}
初始化 MDP对象
MDPComp* MDPComp::getObject(const int& width, int dpy) {
if(width <= MAX_DISPLAY_DIM) {
return new MDPCompLowRes(dpy);
} else {
return new MDPCompHighRes(dpy);
}
}
同理手机一般可以得到MDPCompLowRes。接下来我们回头来看看prepare做了什么?
硬件层初始化
还记得HWC2On1Adapter实际上是管理硬件层的hw_device_t结构体吗。我们接下里继续以msm8960为线索看看硬件做了什么事情。
文件:/hardware/qcom/display/msm8960/libhwcomposer/hwc.cpp
调用函数如下:
mHwc1Device->prepare(mHwc1Device, mHwc1Contents.size(),
mHwc1Contents.data());
把之前保存好的数据传入硬件。
在结构体中prepare对应着hwc_prepare函数指针。
static int hwc_prepare(hwc_composer_device_1 *dev, size_t numDisplays,
hwc_display_contents_1_t** displays)
{
int ret = 0;
hwc_context_t* ctx = (hwc_context_t*)(dev);
Locker::Autolock _l(ctx->mBlankLock);
reset(ctx, numDisplays, displays);
ctx->mOverlay->configBegin();
ctx->mRotMgr->configBegin();
ctx->mNeedsRotator = false;
for (int32_t i = numDisplays - 1; i >= 0; i--) {
hwc_display_contents_1_t *list = displays[i];
switch(i) {
case HWC_DISPLAY_PRIMARY:
ret = hwc_prepare_primary(dev, list);
break;
case HWC_DISPLAY_EXTERNAL:
ret = hwc_prepare_external(dev, list, i);
break;
case HWC_DISPLAY_VIRTUAL:
ret = hwc_prepare_virtual(dev, list, i);
break;
default:
ret = -EINVAL;
}
}
ctx->mOverlay->configDone();
ctx->mRotMgr->configDone();
return ret;
}
我们只需要关系主屏幕的绘制准备hwc_prepare_primary。
static int hwc_prepare_primary(hwc_composer_device_1 *dev,
hwc_display_contents_1_t *list) {
hwc_context_t* ctx = (hwc_context_t*)(dev);
const int dpy = HWC_DISPLAY_PRIMARY;
if(UNLIKELY(!ctx->mBasePipeSetup))
setupBasePipe(ctx);
if (LIKELY(list && list->numHwLayers > 1) &&
ctx->dpyAttr[dpy].isActive) {
reset_layer_prop(ctx, dpy, list->numHwLayers - 1);
uint32_t last = list->numHwLayers - 1;
hwc_layer_1_t *fbLayer = &list->hwLayers[last];
if(fbLayer->handle) {
setListStats(ctx, list, dpy);
int fbZOrder = ctx->mMDPComp[dpy]->prepare(ctx, list);
if(fbZOrder >= 0)
ctx->mFBUpdate[dpy]->prepare(ctx, list, fbZOrder);
}
}
return 0;
}
准备阶段做了三件事情:
- 1.mBasePipeSetup一开始默认是false,所以setupBasePipe 初始化MDP
- 2.hwc_layer_1_t 通过mMDPComp获取屏幕id的MDP,找到对应屏幕对应的数据,找到在硬件中的z轴位置。
- 3.通过prepare更新对应屏幕的mFBUpdate
setupBasePipe
bool MDPComp::setupBasePipe(hwc_context_t *ctx) {
const int dpy = HWC_DISPLAY_PRIMARY;
int fb_width = ctx->dpyAttr[dpy].xres;
int fb_height = ctx->dpyAttr[dpy].yres;
int fb_fd = ctx->dpyAttr[dpy].fd;
mdp_overlay ovInfo;
msmfb_overlay_data ovData;
memset(&ovInfo, 0, sizeof(mdp_overlay));
memset(&ovData, 0, sizeof(msmfb_overlay_data));
ovInfo.src.format = MDP_RGB_BORDERFILL;
ovInfo.src.width = fb_width;
ovInfo.src.height = fb_height;
ovInfo.src_rect.w = fb_width;
ovInfo.src_rect.h = fb_height;
ovInfo.dst_rect.w = fb_width;
ovInfo.dst_rect.h = fb_height;
ovInfo.id = MSMFB_NEW_REQUEST;
if (ioctl(fb_fd, MSMFB_OVERLAY_SET, &ovInfo) < 0) {
return false;
}
ovData.id = ovInfo.id;
if (ioctl(fb_fd, MSMFB_OVERLAY_PLAY, &ovData) < 0) {
return false;
}
return true;
}
这个方法是向fb驱动进行通信:
- 1.先向fb发送MSMFB_OVERLAY_SET命令初始化overlayer浮层的参数
- 2.MSMFB_OVERLAY_PLAY 推一个空的overlayer缓冲到fb驱动中进行渲染,判断fb驱动是否有问题。
MDP prepare
文件:/hardware/qcom/display/msm8960/libhwcomposer/hwc_mdpcomp.cpp
int MDPComp::prepare(hwc_context_t *ctx, hwc_display_contents_1_t* list) {
const int numLayers = ctx->listStats[mDpy].numAppLayers;
mCurrentFrame.reset(numLayers);
...
//Check whether layers marked for MDP Composition is actually doable.
if(isFullFrameDoable(ctx, list)){
mCurrentFrame.map();
if(!programMDP(ctx, list)) {
mCurrentFrame.reset(numLayers);
mCachedFrame.cacheAll(list);
} else { //Success
if(mCurrentFrame.fbCount &&
((mCurrentFrame.mdpCount != mCachedFrame.mdpCount) ||
(mCurrentFrame.fbCount != mCachedFrame.cacheCount) ||
(mCurrentFrame.fbZ != mCachedFrame.fbZ) ||
(!mCurrentFrame.mdpCount) ||
(list->flags & HWC_GEOMETRY_CHANGED) ||
isSkipPresent(ctx, mDpy) ||
(mDpy > HWC_DISPLAY_PRIMARY))) {
mCurrentFrame.needsRedraw = true;
}
}
} else if(isOnlyVideoDoable(ctx, list)) {
...
if(!programYUV(ctx, list)) {
...
}
} else {
mCurrentFrame.reset(numLayers);
mCachedFrame.cacheAll(list);
}
//UpdateLayerFlags
setMDPCompLayerFlags(ctx, list);
mCachedFrame.updateCounts(mCurrentFrame);
return mCurrentFrame.fbZ;
}
这里面做的逻辑其实十分复杂,我只会挑选重点进行分析:
- 1.isFullFrameDoable 判断MDP是否能执行下去,并且更新本次即将刷新的层级,最核心是计算出,那一层开始是由FBUpdate对象进行处理
- 2.一般来说一个判断走完,就会进行programMDP,最后把准备的信息通信给OverLayer对象。
- 3.设置mCachedFrame的参数,setMDPCompLayerFlags更新每一个layer中的type(HWC_OVERLAY)。返回mCurrentFrame.fbZ,这个fbZ代表从第几层开始交给FBUpdate处理。
我们主要看看isFullFrameDoable中的核心逻辑,看看MDP控制的图层。
MDPComp isFullFrameDoable
bool MDPComp::isFullFrameDoable(hwc_context_t *ctx,
hwc_display_contents_1_t* list){
const int numAppLayers = ctx->listStats[mDpy].numAppLayers;
//标志位判断
...
for(int i = 0; i < numAppLayers; ++i) {
hwc_layer_1_t* layer = &list->hwLayers[i];
private_handle_t *hnd = (private_handle_t *)layer->handle;
if(isYuvBuffer(hnd) ) {
if(isSecuring(ctx, layer)) {
return false;
}
} else if(layer->transform & HWC_TRANSFORM_ROT_90) {
return false;
}
if(!isValidDimension(ctx,layer)) {
return false;
}
}
bool ret = false;
if(fullMDPComp(ctx, list)) {
ret = true;
} else if (partialMDPComp(ctx, list)) {
ret = true;
}
return ret;
}
- 1.isValidDimension 校验裁剪区域和即将显示区域。如果宽高小于5则返回false,如果裁剪区域和即将显示区域相比发现需要缩小4倍,也不会执行下去。因为HWC和OpenGL es的实现有点不一致,太小的区域绘制出来的效果可能和OpenGL es不太一样。
- 2.fullMDPComp 校验是否有足够的管道数组空间可用。
- 3.不够,则会执行这个方法partialMDPComp进行分配。
我们主要看partialMDPComp方法。
MDPComp partialMDPComp
bool MDPComp::partialMDPComp(hwc_context_t *ctx, hwc_display_contents_1_t* list)
{
int numAppLayers = ctx->listStats[mDpy].numAppLayers;
mCurrentFrame.reset(numAppLayers);
updateLayerCache(ctx, list);
updateYUV(ctx, list);
batchLayers(); //sets up fbZ also
int mdpCount = mCurrentFrame.mdpCount;
if(mdpCount > (sMaxPipesPerMixer - 1)) { // -1 since FB is used
return false;
}
int numPipesNeeded = pipesNeeded(ctx, list);
int availPipes = getAvailablePipes(ctx);
if(numPipesNeeded > availPipes) {
return false;
}
return true;
}
int MDPCompLowRes::pipesNeeded(hwc_context_t *ctx,
hwc_display_contents_1_t* list) {
return mCurrentFrame.mdpCount;
}
numAppLayers是指在Hal层保存了多少的Layer对象。mCurrentFrame将会对这个Z轴上的Layer保存下来。
- 1.updateLayerCache 根据Layer的数据更新mCurrentFrame的layoutCount,mdpCount
- 2.updateYUV 刷新YUV对应的fbCount
- 3.batchLayers 找到Layer中需要交给FBUpdate处理的图层
- 4.检测是否有足够的pipe空间进行分配。
updateLayerCache
void MDPComp::updateLayerCache(hwc_context_t* ctx,
hwc_display_contents_1_t* list) {
int numAppLayers = ctx->listStats[mDpy].numAppLayers;
int numCacheableLayers = 0;
for(int i = 0; i < numAppLayers; i++) {
if (mCachedFrame.hnd[i] == list->hwLayers[i].handle) {
numCacheableLayers++;
mCurrentFrame.isFBComposed[i] = true;
} else {
mCurrentFrame.isFBComposed[i] = false;
mCachedFrame.hnd[i] = list->hwLayers[i].handle;
}
}
mCurrentFrame.fbCount = numCacheableLayers;
mCurrentFrame.mdpCount = mCurrentFrame.layerCount -
mCurrentFrame.fbCount;
}
这里面会判断多少的Layer保存着handle(GraphicBuffer)并更新mCurrentFrame。每校验对应的isFBComposed 为true,mCurrentFrame.fbCount就加1.因此layerCount 实际上就是指hal层有多少Layer,fbCount是指有多少Layer有handle,mdpCount是指多少Layer是没有图元handle的。
updateYUV
void MDPComp::updateYUV(hwc_context_t* ctx, hwc_display_contents_1_t* list) {
int nYuvCount = ctx->listStats[mDpy].yuvCount;
for(int index = 0;index < nYuvCount; index++){
int nYuvIndex = ctx->listStats[mDpy].yuvIndices[index];
hwc_layer_1_t* layer = &list->hwLayers[nYuvIndex];
if(!isYUVDoable(ctx, layer)) {
if(!mCurrentFrame.isFBComposed[nYuvIndex]) {
mCurrentFrame.isFBComposed[nYuvIndex] = true;
mCurrentFrame.fbCount++;
}
} else {
if(mCurrentFrame.isFBComposed[nYuvIndex]) {
mCurrentFrame.isFBComposed[nYuvIndex] = false;
mCurrentFrame.fbCount--;
}
}
}
mCurrentFrame.mdpCount = mCurrentFrame.layerCount -
mCurrentFrame.fbCount;
}
校验每一个Layer中有多少Layer是支持YUV格式的。
此时会校验到Layer不支持YUV且isFBComposed为false(没有handle),对应的isFBComposed变为true,fbCount+1.可以让fb进行渲染。
支持YUV格式,但是发现isFBComposed 为true,则isFBComposed变为false,fbCount - 1。
说明Layer可以没有handle,如果是YUV格式将不会交给fb处理。mdpCount此时就是计算上YUV没有handle的Layer数量。
batchLayers
void MDPComp::batchLayers() {
int maxBatchStart = -1;
int maxBatchCount = 0;
/* All or Nothing is cached. No batching needed */
if(!mCurrentFrame.fbCount) {
mCurrentFrame.fbZ = -1;
return;
}
if(!mCurrentFrame.mdpCount) {
mCurrentFrame.fbZ = 0;
return;
}
int i = 0;
while (i < mCurrentFrame.layerCount) {
int count = 0;
while(mCurrentFrame.isFBComposed[i] && i < mCurrentFrame.layerCount) {
count++; i++;
}
if(count > maxBatchCount) {
maxBatchCount = count;
maxBatchStart = i - count;
mCurrentFrame.fbZ = maxBatchStart;
}
if(i < mCurrentFrame.layerCount) i++;
}
for(int i = 0; i < mCurrentFrame.layerCount; i++) {
if(i != maxBatchStart){
mCurrentFrame.isFBComposed[i] = false;
} else {
i += maxBatchCount;
}
}
mCurrentFrame.fbCount = maxBatchCount;
mCurrentFrame.mdpCount = mCurrentFrame.layerCount -
mCurrentFrame.fbCount;
}
如果此时fbCount和mdpCount为0,fbZ则返回-1和0.没有一个Layer需要交给fb处理。
这做的事情实际上就是找最大连续的fb图层,找到最顶层的那个作为mCurrentFrame.fbZ。说明从着一段连续的开始可以交给FBUpdateLowRes处理。
mdpCount 代表有多少图层可以叫MDP处理,fbCount代表交给FBUpdateLowRes处理。最终能得出一个结论:
fbCount + mdpCount = layerCount - (YUV和handle冲突的图层数量)
programMDP
bool MDPComp::programMDP(hwc_context_t *ctx, hwc_display_contents_1_t* list) {
ctx->mDMAInUse = false;
if(!allocLayerPipes(ctx, list)) {
return false;
}
bool fbBatch = false;
for (int index = 0, mdpNextZOrder = 0; index < mCurrentFrame.layerCount;
index++) {
if(!mCurrentFrame.isFBComposed[index]) {
int mdpIndex = mCurrentFrame.layerToMDP[index];
hwc_layer_1_t* layer = &list->hwLayers[index];
MdpPipeInfo* cur_pipe = mCurrentFrame.mdpToLayer[mdpIndex].pipeInfo;
cur_pipe->zOrder = mdpNextZOrder++;
if(configure(ctx, layer, mCurrentFrame.mdpToLayer[mdpIndex]) != 0 ){
return false;
}
} else if(fbBatch == false) {
mdpNextZOrder++;
fbBatch = true;
}
}
return true;
}
经过isFullFramedoable对mdp需要处理对图层进行处理后,就会使用programMDP进行申请相关的内存。
- 1.allocLayerPipes 申请用于承载参数的管道内存
- 2.遍历左右的Layer,找到isFBComposed为false不交给FBUpdateLowRes处理的图层,进行configure 配置处理。
allocLayerPipes
bool MDPCompLowRes::allocLayerPipes(hwc_context_t *ctx,
hwc_display_contents_1_t* list) {
//处理YUV
...
for(int index = 0 ; index < mCurrentFrame.layerCount; index++ ) {
if(mCurrentFrame.isFBComposed[index]) continue;
hwc_layer_1_t* layer = &list->hwLayers[index];
private_handle_t *hnd = (private_handle_t *)layer->handle;
if(isYuvBuffer(hnd))
continue;
int mdpIndex = mCurrentFrame.layerToMDP[index];
PipeLayerPair& info = mCurrentFrame.mdpToLayer[mdpIndex];
info.pipeInfo = new MdpPipeInfoLowRes;
info.rot = NULL;
MdpPipeInfoLowRes& pipe_info = *(MdpPipeInfoLowRes*)info.pipeInfo;
ePipeType type = MDPCOMP_OV_ANY;
if(!qhwc::needsScaling(layer) && !ctx->mNeedsRotator
&& ctx->mMDP.version >= qdutils::MDSS_V5) {
type = MDPCOMP_OV_DMA;
}
pipe_info.index = getMdpPipe(ctx, type);
if(pipe_info.index == ovutils::OV_INVALID) {
return false;
}
}
return true;
}
核心是getMdpPipe申请一段Mdp管道内存。这里会根据版本号,如果不需要旋转和缩放则设置成MDPCOMP_OV_DMA,否则则是MDPCOMP_OV_ANY。
ovutils::eDest MDPComp::getMdpPipe(hwc_context_t *ctx, ePipeType type) {
overlay::Overlay& ov = *ctx->mOverlay;
ovutils::eDest mdp_pipe = ovutils::OV_INVALID;
switch(type) {
case MDPCOMP_OV_DMA:
mdp_pipe = ov.nextPipe(ovutils::OV_MDP_PIPE_DMA, mDpy);
if(mdp_pipe != ovutils::OV_INVALID) {
ctx->mDMAInUse = true;
return mdp_pipe;
}
case MDPCOMP_OV_ANY:
case MDPCOMP_OV_RGB:
mdp_pipe = ov.nextPipe(ovutils::OV_MDP_PIPE_RGB, mDpy);
if(mdp_pipe != ovutils::OV_INVALID) {
return mdp_pipe;
}
if(type == MDPCOMP_OV_RGB) {
break;
}
case MDPCOMP_OV_VG:
return ov.nextPipe(ovutils::OV_MDP_PIPE_VG, mDpy);
default:
return ovutils::OV_INVALID;
};
return ovutils::OV_INVALID;
}
此时会调用Overlay中的nextPipe申请一段内存。其中ANY和RGB都是一种类型OV_MDP_PIPE_RGB,DMA则是OV_MDP_PIPE_DMA。
OverLayer nextPipe
eDest Overlay::nextPipe(eMdpPipeType type, int dpy) {
eDest dest = OV_INVALID;
for(int i = 0; i < PipeBook::NUM_PIPES; i++) {
//Match requested pipe type
if(type == OV_MDP_PIPE_ANY || type == PipeBook::getPipeType((eDest)i)) {
if((mPipeBook[i].mDisplay == PipeBook::DPY_UNUSED ||
mPipeBook[i].mDisplay == dpy) &&
PipeBook::isNotAllocated(i)) {
dest = (eDest)i;
PipeBook::setAllocation(i);
break;
}
}
}
if(dest != OV_INVALID) {
int index = (int)dest;
mPipeBook[index].mDisplay = dpy;
if(not mPipeBook[index].valid()) {
mPipeBook[index].mPipe = new GenericPipe(dpy);
}
} else {
...
}
return dest;
}
在这里面会遍历NUM_PIPES中限制的PipeBook数量,找到一段type一样的mPipeBook中的index;如果是ANY则会随便找一个type。如果发现没有申请过则会调用setAllocation,在内存位图sAllocatedBitmap打上一个标志位。由于这个bitmap是一个32位的int型,所以最多只有32个内存允许申请。
最后在mPipeBook对应的index申请GenericPipe缓存下去,作为这个Layer通信到管道的缓存。
mPipeBook:NUM_PIPES是怎么获取的呢?
uint8_t getTotalPipes() { return (mRGBPipes + mVGPipes + mDMAPipes);}
其实是由三个管道数量进行决定的。而这三个管道数量实际上由fb驱动决定的。
hwc_fbupdate 准备
bool FBUpdateLowRes::prepare(hwc_context_t *ctx, hwc_display_contents_1 *list,
int fbZorder) {
if(!ctx->mMDP.hasOverlay) {
return false;
}
mModeOn = configure(ctx, list, fbZorder);
return mModeOn;
}
// Configure
bool FBUpdateLowRes::configure(hwc_context_t *ctx, hwc_display_contents_1 *list,
int fbZorder) {
bool ret = false;
hwc_layer_1_t *layer = &list->hwLayers[list->numHwLayers - 1];
if (LIKELY(ctx->mOverlay)) {
overlay::Overlay& ov = *(ctx->mOverlay);
private_handle_t *hnd = (private_handle_t *)layer->handle;
ovutils::Whf info(getWidth(hnd), getHeight(hnd),
ovutils::getMdpFormat(hnd->format), hnd->size);
//Request an RGB pipe
ovutils::eDest dest = ov.nextPipe(ovutils::OV_MDP_PIPE_ANY, mDpy);
if(dest == ovutils::OV_INVALID) { //None available
return false;
}
mDest = dest;
ovutils::eMdpFlags mdpFlags = ovutils::OV_MDP_BLEND_FG_PREMULT;
ovutils::eZorder zOrder = static_cast(fbZorder);
ovutils::PipeArgs parg(mdpFlags,
info,
zOrder,
ovutils::IS_FG_OFF,
ovutils::ROT_FLAGS_NONE,
ovutils::DEFAULT_PLANE_ALPHA,
(ovutils::eBlending) getBlending(layer->blending));
ov.setSource(parg, dest);
hwc_rect_t sourceCrop;
getNonWormholeRegion(list, sourceCrop);
// x,y,w,h
ovutils::Dim dcrop(sourceCrop.left, sourceCrop.top,
sourceCrop.right - sourceCrop.left,
sourceCrop.bottom - sourceCrop.top);
ov.setCrop(dcrop, dest);
int transform = layer->transform;
ovutils::eTransform orient =
static_cast(transform);
ov.setTransform(orient, dest);
hwc_rect_t displayFrame = sourceCrop;
ovutils::Dim dpos(displayFrame.left,
displayFrame.top,
displayFrame.right - displayFrame.left,
displayFrame.bottom - displayFrame.top);
if(mDpy)
getActionSafePosition(ctx, mDpy, dpos.x, dpos.y, dpos.w, dpos.h);
ov.setPosition(dpos, dest);
ret = true;
if (!ov.commit(dest)) {
ret = false;
}
}
return ret;
}
在fb底层会生成一个Overlayer对象。每一次需要有命令进行退出,将会从Pipe管道数组PipeBook中推出一个用于承载GraphicBuffer的句柄,参见参数,颜色空间,像素格式,位置等等,最后调用commit把数据推回PipeBook数组中,等待消费。
后面的解析,我们就围绕着fb驱动逻辑进行分析。
generateChanges
void HWC2On1Adapter::Display::generateChanges() {
std::unique_lock lock(mStateMutex);
mChanges.reset(new Changes);
size_t numLayers = mHwc1RequestedContents->numHwLayers;
for (size_t hwc1Id = 0; hwc1Id < numLayers; ++hwc1Id) {
const auto& receivedLayer = mHwc1RequestedContents->hwLayers[hwc1Id];
if (mHwc1LayerMap.count(hwc1Id) == 0) {
continue;
}
Layer& layer = *mHwc1LayerMap[hwc1Id];
updateTypeChanges(receivedLayer, layer);
updateLayerRequests(receivedLayer, layer);
}
}
void HWC2On1Adapter::Display::updateTypeChanges(const hwc_layer_1_t& hwc1Layer,
const Layer& layer) {
auto layerId = layer.getId();
switch (hwc1Layer.compositionType) {
case HWC_FRAMEBUFFER:
if (layer.getCompositionType() != Composition::Client) {
mChanges->addTypeChange(layerId, Composition::Client);
}
break;
case HWC_OVERLAY:
if (layer.getCompositionType() != Composition::Device) {
mChanges->addTypeChange(layerId, Composition::Device);
}
break;
case HWC_BACKGROUND:
...
break;
case HWC_FRAMEBUFFER_TARGET:
// Do nothing, since it shouldn't be modified by HWC1
break;
case HWC_SIDEBAND:
...
break;
case HWC_CURSOR_OVERLAY:
...
break;
}
}
当此时如果在Hal层设置的HWC_FRAMEBUFFER,则会把每一个hwcLayer渲染模式都转化为Composition::Client。HWC_OVERLAY绘制overlayer层时候才会设置为 Composition::Device。Hal层的Composition::Client不要和上层的HWC2::Composition::Client弄混淆了。
当上层和Hal层都准备好了需要HWC绘制的图元,再来回头看看FrameBufferSurface的准备工作prepareFrame
FrameBufferSurface prepareFrame
文件:/frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cpp
status_t FramebufferSurface::prepareFrame(CompositionType /*compositionType*/) {
return NO_ERROR;
}
没做任何事情。
总结
在绘制准备流程中做了如下几个步骤:
-
- preComposition 预处理合成,校验有没有在图元缓冲队列中还有没有需要消费的,没有或者没有打开自动刷新的开关,则不会进行刷新。
-
- rebuildLayerStacks 重新构建Layer mVisibleRegionsDirty发现有Layer增加或者有新的图元进行了latch,则会重组Layer的可视区域,透明区域,遮挡区域,不透明区域。
-
- setUpHWComposer HWC进行渲染的准备,遍历每一个Layer,分为如下几个步骤:beginFrame(没做事情);createLayer为每一个Layer创建对应在HWC下的Layer对象,一旦失败则会强制变成Client渲染模式;setPerFrameData把通过latch消费图元缓存在cache的图元取出,并且设置到hwcLayer中;prepareFrame将会对hwcLayer中对应在Hal层的Device和Layer进行准备工作,主要是把Layer中缓存的GraphicBuffer保存在hw_content_t中,最红输送到硬件中处理。
在硬件层中,分为2部分,一个是MDP渲染overlayer,一个是fb渲染overlayer。其实两者都是采用相似的设计,通过一个管道数组管理传递下来的图元句柄,裁剪等参数,等待消费。
准备的流程有点长,一路到了硬件层。但实际上除了准备相关的数据到Hal之外。我们需要关注一个知识点,那就是prepareFrame中Composer的几个type渲染type的转化,大致经历如下流程:
- 1.Hal层的validate方法中会进行校验和准备需要的数据保存到mHwc1RequestedContents,在这个过程会为把之前创造的hwclayer中的参数拷贝一份到其中,其中就有定义如下一个type的表格参数:
| mCompositionType | compositionType | flag |
|---|---|---|
| Composition::Client | HWC_FRAMEBUFFER(FRAMEBUFFER最后都会强制刷新) | HWC_SKIP_LAYER |
| Composition::Device | HWC_OVERLAY(强制更新) | - |
| Composition::SolidColor | HWC_FRAMEBUFFER | HWC_SKIP_LAYER |
| Composition::Cursor | HWC_FRAMEBUFFER | HWC_IS_CURSOR_LAYER |
| Composition::Sideband | HWC_SIDEBAND 或者HWC_FRAMEBUFFER | 如果是HWC_FRAMEBUFFER,添加HWC_SKIP_LAYER |
| 其他 | HWC_FRAMEBUFFER | HWC_SKIP_LAYER |
能看到在HWC中会添加一个标志位HWC_SKIP_LAYER,来判断是否需要跳过当前Layer在Hwc中的绘制。换句话说,HWC绘制overlayer的说法是正确的。其他它还可能绘制了Cursor这种焦点窗口以及在高版本中绘制Sideband边带。
- 2.当Hal层处理结束后,保存在HWC的Display数据集合,就会判断当前的Layer是否包含Client或者Device,也就是我们常说的是混合HWC和OpenGL es的模式,以及是纯粹的HWC模式,OpenGLes模式。
对应的,我们能得出如下表格:
| Composition的Layer的Type | hasClientComposition | hasDeviceComposition | 渲染方式 |
|---|---|---|---|
| HWC2::Composition::Client | true | - | OpenGL es |
| HWC2::Composition::Device | - | true | HWC |
| HWC2::Composition::SolidColor | - | true | HWC |
| HWC2::Composition::Sideband | - | true | HWC或者OpenGL es |
如果发现是纯粹的OpenGL es模式,就不要进行Hwc的绘制了。这样就能在下一步合成图元中减少一些不必要的操作。记住如果Hwc下的Layer创建失败了,所有的渲染模式将会强制设置为Client。
那么又是什么决定这些渲染模式呢?其实在setPerFrame步骤中
if (getBE().compositionInfo.hwc.sidebandStream.get()) {
setCompositionType(hwcId, HWC2::Composition::Sideband);
error = hwcLayer->setSidebandStream(getBE().compositionInfo.hwc.sidebandStream->handle());
return;
}
// Device or Cursor layers
if (mPotentialCursor) {
setCompositionType(hwcId, HWC2::Composition::Cursor);
} else {
setCompositionType(hwcId, HWC2::Composition::Device);
}
在BufferLayer中会根据通过Surface设置在Layer中的flag打开对应的type。对应Client来说,HWC_FRAMEBUFFER都会强制设置为Client模式进行OpenGL es渲染。