oracle 数据库的scott帐号。
<>作为查询条件时,可以使用!= 来替换。
SQL> select * from emp;
EMPNO ENAME JOB MGR HIREDATE SAL COMM DEPTNO
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
14 rows selected
单表查询:
SQL> select ename,job,sal from emp;
ENAME JOB SAL
SMITH CLERK 800.00
ALLEN SALESMAN 1600.00
WARD SALESMAN 1250.00
JONES MANAGER 2975.00
MARTIN SALESMAN 1250.00
BLAKE MANAGER 2850.00
CLARK MANAGER 2450.00
SCOTT ANALYST 3000.00
KING PRESIDENT 5000.00
TURNER SALESMAN 1500.00
ADAMS CLERK 1100.00
JAMES CLERK 950.00
FORD ANALYST 3000.00
MILLER CLERK 1300.00
14 rows selected
查询全部列:
select * from emp;
查询经过计算的值:
SQL> select ename,job,6000-sal from emp;
ENAME JOB 6000-SAL
SMITH CLERK 5200
ALLEN SALESMAN 4400
WARD SALESMAN 4750
JONES MANAGER 3025
MARTIN SALESMAN 4750
BLAKE MANAGER 3150
CLARK MANAGER 3550
SCOTT ANALYST 3000
KING PRESIDENT 1000
TURNER SALESMAN 4500
ADAMS CLERK 4900
JAMES CLERK 5050
FORD ANALYST 3000
MILLER CLERK 4700
14 rows selected
列出ename,job,sal,并用小写字母来表示job,ename :
SQL> select lower(ename),lower(job),sal from emp;
LOWER(ENAME) LOWER(JOB) SAL
smith clerk 800.00
allen salesman 1600.00
ward salesman 1250.00
jones manager 2975.00
martin salesman 1250.00
blake manager 2850.00
clark manager 2450.00
scott analyst 3000.00
king president 5000.00
turner salesman 1500.00
adams clerk 1100.00
james clerk 950.00
ford analyst 3000.00
miller clerk 1300.00
14 rows selected
别名的使用:在select语句的执行顺序中,from子句最先被执行,然后就是where子句,最后才是select子句。当在from子句中指定表别名后,表的真实名称将被替换。同时,其他的子句只能使用表别名来限定列。
SQL> select ename 名字,job 工作,sal from emp;
名字 工作 SAL
SMITH CLERK 800.00
ALLEN SALESMAN 1600.00
WARD SALESMAN 1250.00
JONES MANAGER 2975.00
MARTIN SALESMAN 1250.00
BLAKE MANAGER 2850.00
CLARK MANAGER 2450.00
SCOTT ANALYST 3000.00
KING PRESIDENT 5000.00
TURNER SALESMAN 1500.00
ADAMS CLERK 1100.00
JAMES CLERK 950.00
FORD ANALYST 3000.00
MILLER CLERK 1300.00
14 rows selected
SQL> select ename "名字",job "工作",sal from emp;(此处双引号只能为英文双引号,汉字双引号报错)
查询的时候,比如job='clerk'这里是英文单引号
关于别名,比如select ename "名字",job "工作",sal from emp; 这里是英文双引号;这里也是英文的,中文无效
在使用列别名时,如果列别名区分大小写,并且还包含一些特殊字符,那么必须使用双引号将列别名引起来。
名字 工作 SAL
SMITH CLERK 800.00
ALLEN SALESMAN 1600.00
WARD SALESMAN 1250.00
JONES MANAGER 2975.00
MARTIN SALESMAN 1250.00
BLAKE MANAGER 2850.00
CLARK MANAGER 2450.00
SCOTT ANALYST 3000.00
KING PRESIDENT 5000.00
TURNER SALESMAN 1500.00
ADAMS CLERK 1100.00
JAMES CLERK 950.00
FORD ANALYST 3000.00
MILLER CLERK 1300.00
14 rows selected
SQL> select ename “名字”,job “工作”,sal from emp;
select ename “名字”,job “工作”,sal from emp
ORA-00911: 无效字符
消除取值重复的行:
SQL> select deptno from emp;
DEPTNO
20
30
30
20
30
30
10
20
10
30
20
30
20
10
14 rows selected
SQL> select distinct deptno from emp;
DEPTNO
30
20
10
此处: select deptno from emp; 等同于 select all deptno from emp;默认没有指定distinct关键词,则缺省值为all,即保留结果表中取值重复的行。
查询满足条件的元组: where 语句来实现!
查询关于工资的比较:
SQL> select ename,job,sal from emp where sal='800';
ENAME JOB SAL
SMITH CLERK 800.00
SQL> select deptno,ename,job from emp where ename='KING';(oracle这里区分大小写)
DEPTNO ENAME JOB
10 KING PRESIDENT
SQL> select ename,job,sal from emp where sal>=2000;
ENAME JOB SAL
JONES MANAGER 2975.00
BLAKE MANAGER 2850.00
CLARK MANAGER 2450.00
SCOTT ANALYST 3000.00
KING PRESIDENT 5000.00
FORD ANALYST 3000.00
6 rows selected
SQL> select ename,job,sal from emp where sal between 1000 and 2000;(此处not between...and...相同使用方法)
ENAME JOB SAL
ALLEN SALESMAN 1600.00
WARD SALESMAN 1250.00
MARTIN SALESMAN 1250.00
TURNER SALESMAN 1500.00
ADAMS CLERK 1100.00
MILLER CLERK 1300.00
6 rows selected
确定集合,谓词In 可以用来查找属性值属于指定集合的元组。(IN 的相对是 NOT IN)
SQL> select ename,job,sal from emp where deptno in ('10','20');
ENAME JOB SAL
SMITH CLERK 800.00
JONES MANAGER 2975.00
CLARK MANAGER 2450.00
SCOTT ANALYST 3000.00
KING PRESIDENT 5000.00
ADAMS CLERK 1100.00
FORD ANALYST 3000.00
MILLER CLERK 1300.00
8 rows selected
字符匹配:
SQL> select ename,job, sal from emp where empno like '7369';
ENAME JOB SAL
SMITH CLERK 800.00
SQL> select ename,job, sal from emp where empno='7369';
ENAME JOB SAL
SMITH CLERK 800.00
SQL> select ename,job, sal from emp where empno like '7%9';
ENAME JOB SAL
SMITH CLERK 800.00
ALLEN SALESMAN 1600.00
KING PRESIDENT 5000.00
SQL> select ename,job, sal from emp where empno like '7__9';
ENAME JOB SAL
SMITH CLERK 800.00
ALLEN SALESMAN 1600.00
KING PRESIDENT 5000.00
SQL> select ename,job, sal from emp where empno like '7_9_';
ENAME JOB SAL
ALLEN SALESMAN 1600.00
BLAKE MANAGER 2850.00
(一个汉字要占两个字符的位置,所以匹配汉字的时候要注意)
涉及空值的查询:(此处is 不能用等号(=)代替)
SQL> select ename,job,sal from emp where mgr is null;
ENAME JOB SAL
KING PRESIDENT 5000.00
多重条件查询: 逻辑运算符and 和or 可用来联结多个查询条件,and优先级比or高,可以通过括号来改变优先级。
SQL> select ename,job,sal from emp where deptno='20' and sal>2500;
ENAME JOB SAL
JONES MANAGER 2975.00
SCOTT ANALYST 3000.00
FORD ANALYST 3000.00
order by 子句:
用户可以用order by 子句对查询结果按照一个或多个属性列的升序(asc)或降序(desc)排列,缺省值为升序。
SQL> select empno,ename,job,sal from emp where deptno='20' order by sal,empno;
EMPNO ENAME JOB SAL
7369 SMITH CLERK 800.00
7876 ADAMS CLERK 1100.00
7566 JONES MANAGER 2975.00
7788 SCOTT ANALYST 3000.00
7902 FORD ANALYST 3000.00
聚集函数:
count([distinct|all]*) 统计元组个数
count([distinct|all]<列名>) 统计一列中值的个数
sum([distinct|all]<列名>) 计算一列值的总合(此列必须是数值型)
avg([distinct|all]<列名>) 计算一列值的平均值(此列必须是数值型)
max([distinct|all]<列名>) 求一列值中的最大值
min([distinct|all]<列名>) 求一列值中的最小值
SQL> select count(*) from emp;
COUNT(*)
14
SQL> select count(sal) from emp;
COUNT(SAL)
14
SQL> select avg(sal) from emp where deptno='20';
AVG(SAL)
2175
SQL> select max(sal) from emp where deptno='20';
MAX(SAL)
3000
SQL> select ename,job, min(sal) from emp where deptno='20';
select ename,job, min(sal) from emp where deptno='20'
ORA-00937: 不是单组分组函数
SQL> select min(sal) from emp where deptno='20';
MIN(SAL)
800
SQL> select sum(sal) from emp ;
SUM(SAL)
29025
Group by句子:
SQL> select avg(sal),max(sal),deptno from emp group by deptno;
AVG(SAL) MAX(SAL) DEPTNO
1566.66666 2850 30
2175 3000 20
2916.66666 5000 10
SQL> select avg(sal),min(sal),job,deptno from emp group by deptno,job;
AVG(SAL) MIN(SAL) JOB DEPTNO
950 800 CLERK 20
1400 1250 SALESMAN 30
2975 2975 MANAGER 20
950 950 CLERK 30
5000 5000 PRESIDENT 10
2850 2850 MANAGER 30
1300 1300 CLERK 10
2450 2450 MANAGER 10
3000 3000 ANALYST 20
9 rows selected
having的用法。就是起到限制,group by 后面的限制。
SQL> select avg(sal),deptno from emp group by deptno having avg(sal)<2000;
AVG(SAL) DEPTNO
1566.66666 30
对数据分组的总结:
1 分组函数只能出现在选择列表、having、order by子句中
2 如果在select 语句中同时包含有group by,having,order by 那么他们的顺序是group by,having,order by
3 在选择列中如果有列、表达式、和分组函数,那么这些列和表达式必须有一个出现在group by 子句中,否则就会出错
如select deptno,avg(sal),max(sal) from emp group by deptno having avg(sal)<2000;这里deptno就一定要出现在group by 中。
在使用group by 子句时,必须满足下面的条件:
在select 子句的后面只可以有两类表达式:统计函数和进行分组的列名。
在select子句中的列名必须是进行分组的列,除此之外添加其他的列名都是错误的,但是,group by子句后面的列名可以不出现在select子句中。
如果使用了where子句,那么所有参加分组计算的数据必须首先满足where子句指定的条件。
下面是衣蛾错误的查询,犹豫在select子句后面出现了salary列,而该列并没有出现在group by 子句中,所以该语句是一个错误的查询。
select job_id,salary,avg(salary),sumsalary),max(salary),count(*) from employees group by job_id;
这里是错误的!!!!

如果处理null值
select sal 13+nvl(comm,0)13 "年工资",ename,comm from emp;








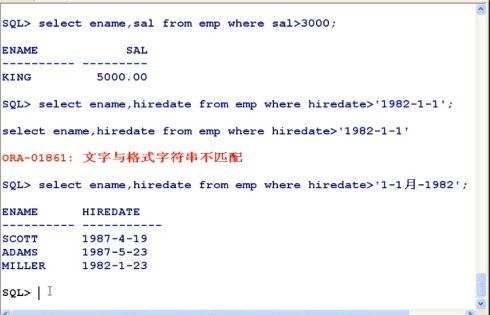




1:子查询
子查询的类型:基本有两种:单行子查询和多行子查询
单行子查询
多行子查询
另外,子查询还有3种子类型,这3种子类型返回一行或者多行的查询结果。
多列子查询
关联子查询
嵌套子查询
单行子查询:
select start_date,end_date,job_id from job_history where employee_id=(select employee_id from employees where first_name='jennifer' and last_name='whalen');
多列子查询是指返回多列数据的子查询语句。当多列子查询返回单行数据时,在where自居中可以使用单行比交付:单色如果需要返回多行数据时,那么where自居中必须使用多行比较符(in、any、all)
1:使用In操作符实现制定匹配查询
当在多行子查询中使用In操作符时,会处理匹配与子查询中任一个值的行。
以下代码查询Jobs表中最高工资分别为10000、20000、30000的职位信息。
select job_id,max_salary from jobs where max_salary in(10000,20000,30000);
2:使用any操作符实现任意匹配查询
any操作符必须与单行操作符结合使用,并且返回行只需匹配与子查询的任一个结果即可。
首先查询jobs表中最高工资小于10000的工作职位,然后在外部查询中查找最低工资大于这些工资的任意一个工作职位信息。
select job_id,min-salary,max_salary from jobs where min_salary>any(select max_salary from jobs where max_salary<10000);
3:使用all操作符实现全部匹配查询
首先查询jobs表中最高工资小于10000的工作职位,然后在外部查询中查找最低工资大于这些工资的任意一个工作职位信息。
select job_id,min_salary,max_salary from jobs where min_salary>all(select max_salary from jobs where max_salary<10000);
在update语句中使用子查询
update jobs set min_salary=min_salary+100 where min_salary>all(select max_salary from jobs where max_salary <10000);
在delete 语句中使用子查询
delete from job_history where employee _id=(select employee_id from employees where first_name='jennifer' and last_name='whalen');