2019独角兽企业重金招聘Python工程师标准>>> 
为什么进行数据挖掘
一、数据爆炸问题
二、数据转化为信息,数据丰富,信息贫乏
三、挖掘信息
什么是数据挖掘?
数据挖掘 (从数据中发现知识),从大量的数据中挖掘哪些令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识
挖掘的不仅仅是数据(所以“数据挖掘”并非一个精确的用词),数据挖掘的替换词如从数据库中的知识挖掘(KDD---Knowledge Discovery in Database)、知识提炼、数据/模式分析、数据考古、数据捕捞、信息收获等等。
数据挖掘: 数据库中的知识挖掘(KDD)
KDD的步骤
从KDD对数据挖掘的定义中可以看到当前研究领域对数据挖掘的狭义和广义认识
数据清理: (消除噪音和删除不一致的数据,这个可能要占全过程60%的工作量)
数据集成:(多种数据源组合在一起)
数据选择:(从数据库中提取与分析任务相关的数据)
数据变换:(通过汇总和聚集操作,把数据变换和统一成适合挖掘的形式)
数据挖掘:(选择适当的算法来找到感兴趣的模式)
模式评估:(根据某种兴趣度度量,识别代表知识的真正有趣的模式)
知识表示:(使用可视化和知识表示技术,像用户提供挖掘的知识)
在何种数据上进行数据挖掘
关系数据库
数据仓库
事务数据库
及其他数据:高级数据库系统和信息库、空间数据库、时间数据库和时间序列数据库、流数据、多媒体数据库、面向对象数据库和对象-关系数据库、异种数据库和历史(legacy)数据库、文本数据库和万维网(WWW)
可以挖掘什么类型的模式
两类:描述性和预测性的
通常,用户并不知道在数据中能挖掘出什么东西,对此我们会在数据挖掘中应用一些常用的数据挖掘功能,挖掘出一些常用的模式,包括:
概念/类描述:特性化和区分
数据可以与类或概念相关联。例如,在AllElectronics商店,销售的商品类包括计算机和打印机,顾客概念包括bigSpenders和budgetSpenders。用汇总的、简洁的、精确的表达方式描述每个类和概念是有用的。这种类或概念的描述称为类/概念描述。这种描述可以通过下述方法得到:(1)数据特征化,一般地汇总所研究类(通常称为目标类)的数据;(2)数据区分,将目标类与一个或多个可比较类(通常称为对比类)进行比较;(3)数据特征化和区分。
特征化:目标类数据的一般特性或特征的汇总。输出形式多种,如饼图、柱状图、曲线图、多维数据立方体等。
例:对AllElectronic公司的“大客户”(年消费额$1000以上)的特征化描述:40-50岁,有固定职业,信誉良好,等等
区分:提供两个或多个数据集的比较描述。
数据区分:是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
挖掘频繁模式、关联和相关性
正如名称所示,频繁模式(frequent pattern)是在数据中频繁出现的模式。存在多种类型的频繁模式,包括频繁项集、频繁子序列(又称序列模式)和频繁子结构。频繁项集一般是指频繁地在事务数据集中一起出现的商品的集合,如小卖部中被许多顾客频繁地一起购买的牛奶和面包。频繁出现的子序列,如顾客倾向于先购买便携机,再购买数码相机,然后再购买内存卡这样的模式就是一个(频繁)序列模式。子结构可能涉及不同的结构形式(例如,图、树或格),可以与项集或子序列结合在一起。如果一个子结构频繁地出现,则称它为(频繁)结构模式。挖掘频繁模式导致发现数据中有趣的关联和相关性。
用于预测分析的分类与回归
分类(classification)是这样的过程,它找出描述和区分数据类或概念的模型(或函数),以便能够使用模型预测类标号未知的对象的类标号。导出模型是基于对训练数据集(即,类标号已知的数据对象)的分析。该模型用来预测类标号未知的对象的类标号。
聚类分析
不像分类和回归分析标记类的(训练)数据集,聚类(clustering)分析数据对象,而不考虑类标号。在许多情况下,开始并不存在标记类的数据。19可以使用聚类产生数据组群的类标号。对象根据最大化类内相似性、最小化类间相似性的原则进行聚类或分组。也就是说,对象的簇(cluster)这样形成,使得相比之下在同一个簇中的对象具有很高的相似性,而与其他簇中的对象很不相似。所形成的每个簇都可以看做一个对象类,由它可以导出规则。聚类也便于分类法形成(taxonomy formation),即将观测组织成类分层结构,把类似的事件组织在一起。
例:对WEB日志的数据进行聚类,以发现相同的用户访问模式
离群点分析
数据集中可能包含一些数据对象,它们与数据的一般行为或模型不一致。这些数据对象是离群点(outlier)。大部分数据挖掘方法都将离群点视为噪声或异常而丢弃。20然而,在一些应用中(例如,欺诈检测),罕见的事件可能比正常出现的事件更令人感兴趣。离群点数据分析称做离群点分析或异常挖掘。
应用
信用卡欺诈检测
移动电话欺诈检测
客户划分
医疗分析(异常)
所有模式都是有趣的吗?
数据挖掘系统具有产生数以千计,甚至数以万计模式或规则的潜在能力。
你可能会问:“所有模式都是有趣的吗?”答案通常是否定的。实际上,对于给定的用户,在可能产生的模式中,只有一小部分是他感兴趣的。
这对数据挖掘提出了一系列严肃的问题。你可能会想:“什么样的模式是有趣的?数据挖掘系统能够产生所有有趣的模式吗?数据挖掘系统能够仅产生有趣的模式吗?”
对于第一个问题,一个模式是有趣的(interesting),如果它:(1)易于被人理解;(2)在某种确信度上,对于新的或检验数据是有效的;(3)是潜在有用的;(4)是新颖的。如果一个模式证实了用户寻求证实的某种假设,则它也是有趣的。有趣的模式代表知识。
数据挖掘使用什么技术
数据库系统、统计学、机器学习、模式识别、数据库和数据仓库、信息检索、算法、可视化、高性能计算等其他学科
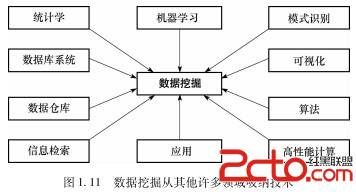
面向什么类型的应用
商务智能
WEB搜索引擎
数据挖掘的主要问题
挖掘方法
用户界面
有效性和可伸缩性
数据库类型的多样性
数据挖掘与社会