Spark的伪分布安装和wordcount测试
基于hadoop2.6伪分布的Spark安装和wordcount测试
一:环境说明
Ubuntu:15.10(不稳定版,建议安装在稳定版,Ubuntu下XX..4是稳定的)
Hadoop:2.6
Scala:2.11.8
Java:1.7.0
Spark:1.6.1
二:hadoop伪分布安装
参考之前我写的一篇博客:http://blog.csdn.net/gamer_gyt/article/details/46793731
三:Scala安装
scala下载地址:http://www.scala-lang.org/download/
解压到指定目录:tar zxvf scala-2.11.8.tgz -C /usr/local/
进入/usr/local/:cd /usr/local
重命名为scala:mv scala-2.11.8 scala
配置环境变量:sudo vim /etc/profile
加入如下信息:
#scala home
export SCALA_HOME=/usr/local/scala
export Path=$SCALA_HOME/bin:$PATH
命令行输入scala -versiom,显示如下
![]()
使用时只需要输入scala即可,退出时输入 :quit
四:Spark安装
1:官网下载最新版本1.6.1
下载链接:http://archive.apache.org/dist/spark/
2:解压到指定目录,我这里是/usr/local/hadoop
tar zxvf spark-1.6.1-bin-hadoop2.6.tgz -C /usr/local/hadoop
重命名为spark(个人习惯):sudo mv spark-1.6.1-bin-hadoop2.6 spark
3:配置环境变量
sudo vim /etc/profile
输入以下:
#spark home
export SPARK_HOME=/usr/local/hadoop/spark
export PATH=$SPARK_HOME/bin:$PATH
4:配置spark-env.sh
cd $SPARK_HOME/conf
cp spark-env.sh.template spark-env.sh
vim spark-env.sh export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/usr/share/scala
export SPARK_HOME=/usr/local/hadoop/spark
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=10G
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
5:配置Slave
cp slaves.template slaves vim slaves
添加以下代码(默认就是localhost):
localhost6:启动(前提是hadoop伪分布已经启动)
启动spark-master.sh
cd $SPARK_HOME/sbin
./start-master.sh
启动Spark Slave
./start-slaves.sh(注意是slaves)
此时便可以访问Spark的web界面了:输入http://127.0.0.1:8099/

进入spark-shell界面
进入spark目录下的bin目录,执行:./spark-shell
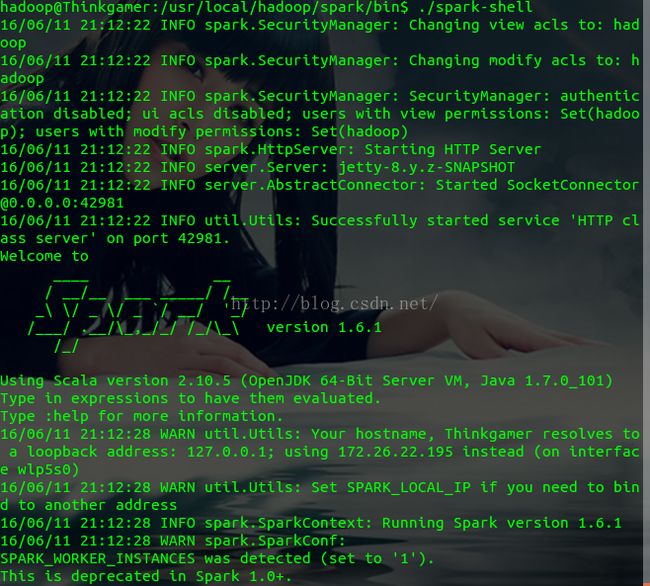
......
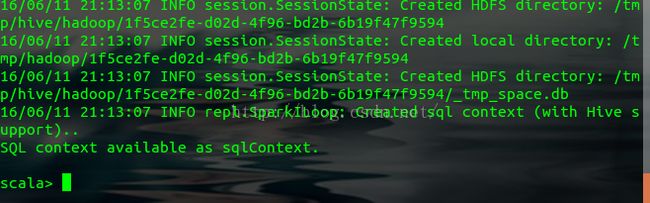
(是不是和scala的shell一样呀)
Spark-shell的web界面访问地址:http://127.0.0.1:4040
六:Spark的WordCount实例
1:上传Spark目录下的README.txt到hdfs上,例如我这里的存放为 /mr/spark/test (test是个文件,内容同README.txt一致)
2:用第五步的命令进入spark-shell
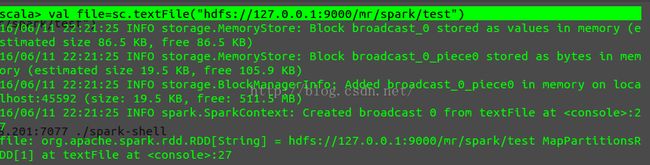
执行:val file=sc.textFile("hdfs://172.16.48.202:9000/mr/spark/README.txt")
val count=file.flatMap(line => line.split(" ")).map(word => (word,1)).reduceByKey(_+_)
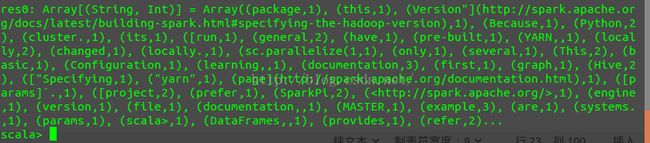
count.collect()
每一步的执行结果为:


最终的运行结果为:
至此,我们已经了解了Spark的安装过程和在spark shell 中用scala运行wordcount,更多精彩请关注gamer_gyt