Docker搭建Hadoop HA高可用集群
hadoop高可用的部署,需要有2个namenode,一个是active的,一个是standby的,两个namenode需要有一个管理员来管理,来决定决定谁active,谁standby,如果处于active状态的的namenode坏了,立即启动standby状态的namenode。这个管理员就是zookeeper。
主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode。
既然是高可用,那么,只有一个管理员zookeeper也不行,万一这个管理员坏了呢。所以要配一个zookeeper集群。同样只有一个JournalNode也不行,要配置多个JournalNode。
| 主机名 | ip | 要安装的软件及部署好后运行的进程 |
|---|---|---|
| master0 | 172.17.0.2 | jdk、hadoop、hadoopNameNode、DFSZKFailoverController(zkfc)、ResourceManager |
| master1 | 172.17.0.3 | jdk、hadoop、hadoopNameNode、DFSZKFailoverController(zkfc)、ResourceManager |
| slave0 | 172.17.0.4 | jdk、hadoop、zookeeperDataNode、NodeManager、JournalNode、QuorumPeerMain |
| slave1 | 172.17.0.4 | jdk、hadoop、zookeeperDataNode、NodeManager、JournalNode、QuorumPeerMain |
| slave2 | 172.17.0.4 | jdk、hadoop、zookeeperDataNode、NodeManager、JournalNode、QuorumPeerMain |
一.docker环境搭建
查看镜像
sudo docker images
拉取一个ubutnu镜像
sudo docker pull ubuntu:16.04
使用ubuntu镜像创建一个容器,并进入
sudo docker run -it ubuntu /bin/bash
退出容器命令
exit
docker常用指令
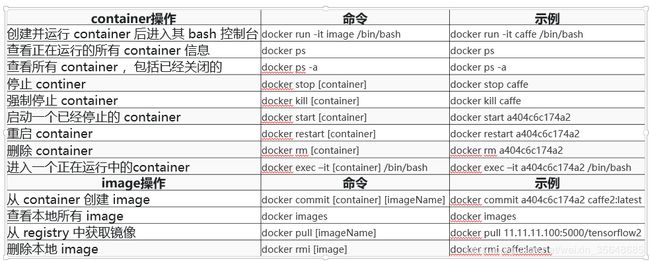
二.ubuntu安装JDK1.8
安装jdk
sudo apt-get install software-properties-common python-software-properties
sudo add-apt-repository ppa:webupd8team/java
sudo apt-get update
sudo apt-get install oracle-java8-installer
update-java-alternatives -s java-8-oracle
查看安装情况
java –version
安装vim
sudo apt-get install vim
配置java环境变量
vim /etc/profile
增加
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
使环境生效
source /etc/profile
检查
echo $JAVA_HOME
保存容器为本地镜像
使用ps查看docker容器id
sudo docker ps -a
提交容器为镜像
sudo docker commit 容器id 镜像名称
三.下载hadoop、spark、scala、hive、hbase、zookeeper
下载hadoop
wget http://archive.apache.org/dist/hadoop/common/hadoop-2.7.6/hadoop-2.7.6.tar.gz
tar -zxvf hadoop-2.7.6.tar.gz
spark
wget http://archive.apache.org/dist/spark/spark-2.0.2/spark-2.0.2-bin-hadoop2.7.tgz
tar -zxvf scala-2.11.11.tgz
scala
wget https://downloads.lightbend.com/scala/2.11.11/scala-2.11.11.tgz
tar -zxvf scala-2.11.11.tgz
hive
wget http://archive.apache.org/dist/hive/hive-2.3.3/apache-hive-2.3.3-bin.tar.gz
tar -zxvf apache-hive-2.3.3-bin.tar.gz
zookeeper
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
tar -zxvf zookeeper-3.4.11.tar.gz
删除安装包
rm *.gz
配置环境变量
vim /etc/profile
增加如下内容
#zookeeper
export ZOOKEEPER_HOME=/root/zookeeper-3.4.11
export PATH=$ZOOKEEPER_HOME/bin:$PATH
#hadoop
export HADOOP_HOME=/root/hadoop-2.7.6
export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_ROOT_LOGGER=INFO,console
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
#scala
export SCALA_HOME=/root/scala-2.11.11
export PATH=${SCALA_HOME}/bin:$PATH
#spark
export SPARK_HOME=/root/spark-2.0.2-bin-hadoop2.7
export PATH=${SPARK_HOME}/bin:${SPARK_HOME}/sbin:$PATH
#hive
export HIVE_HOME=/root/apache-hive-2.3.3-bin
export PATH=$PATH:$HIVE_HOME/bin
#hbase
export HBASE_HOME=/root/hbase-1.2.6
export PATH=$PATH:$HBASE_HOME/bin
使之生效
source /etc/profile
验证
hadoop

四.网络配置
安装网络工具
sudo apt-get install net-tools
sudo apt-get install inetutils-ping
更新下软件库
sudo apt-get update
安装ssh服务
sudo apt-get install openssh-server
启动服务
service ssh start
查看服务是否启动
ps -e |grep ssh
![]()
生成公钥(一路回车)
ssh-keygen -t rsa
将本机公钥放到本机认证的密钥中,使得本机ssh本机不需要密码
cat /root/.ssh/id_rsa.pub >>/root/.ssh/authorized_keys
ssh本机测试
ssh localhost

五.初步配置上述组件
配置hadoop
cd ~/hadoop-2.7.6/etc/hadoop/
修改core-site.xml如下:
fs.defaultFS
hdfs://mycluster
hadoop.tmp.dir
/home/hadoop-2.7.3/tmp
ha.zookeeper.quorum
slave0:2181,slave1:2181,slave2:2181
修改 hadoop - env. sh
vim hadoop-env.sh
增加:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
修改hdfs-site.xml
vim hdfs-site.xml
增加如下内容:
dfs.nameservices
mycluster
dfs.ha.namenodes.mycluster
nn1,nn2
dfs.namenode.rpc-address.mycluster.nn1
master0:9000
dfs.namenode.http-address.mycluster.nn1
master0:50070
dfs.namenode.rpc-address.mycluster.nn2
master1:9000
dfs.namenode.http-address.mycluster.nn2
master1:50070
dfs.namenode.shared.edits.dir
qjournal://slave0:8485;slave1:8485;slave2:8485/mycluster
dfs.journalnode.edits.dir
/home/hadoop-2.7.3/journaldata
dfs.ha.automatic-failover.enabled
true
dfs.client.failover.proxy.provider.mycluster
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/root/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout
30000
修改mapred-site.xml
vim mapred-site.xml
增加如下内容:
mapreduce.framework.name
yarn
修改slaves文件,记录hadoop的datanode地址
vim slaves
增加如下内容:
localhost
修改yarn-site.xml
vim yarn-site.xml
增加如下内容:
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
mycluster
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
master0
yarn.resourcemanager.hostname.rm2
master1
yarn.resourcemanager.recovery.enabled
true
启用RM重启的功能,默认为false
yarn.resourcemanager.store.class
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore
用于状态存储的类,采用ZK存储状态类
yarn.resourcemanager.zk-address
slave0:2181,slave1:2181,slave2:2181
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.webapp.address.rm1
master0:8001
提供给web页面访问的地址,可以查看任务状况等信息
yarn.resourcemanager.webapp.address.rm2
master1:8001
提供给web页面访问的地址,可以查看任务状况等信息
yarn.resourcemanager.scheduler.address.rm1
master0:8030
yarn.resourcemanager.resource-tracker.address.rm1
master0:8031
yarn.resourcemanager.address.rm1
master0:8032
yarn.resourcemanager.admin.address.rm1
master0:8033
yarn.resourcemanager.scheduler.address.rm2
master1:8030
yarn.resourcemanager.resource-tracker.address.rm2
master1:8031
yarn.resourcemanager.address.rm2
master1:8032
yarn.resourcemanager.admin.address.rm2
master1:8033
Spark初步配置
切换到spark配置文件目录
cd ~/spark-2.0.2-bin-hadoop2.7/conf
修改slaves文件
vim slaves
增加如下内容:
localhost
修改spark-defaults.conf
vim spark-defaults.conf
增加如下内容:
spark.master spark://localhost:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:9000/historyserverforSpark
spark.yarn.historyServer.address localhost:18080
spark.history.fs.logDirectory hdfs://localhost:9000/historyserverforSpark
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 4g
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
修改spark- env. sh
vim spark-env.sh
增加如下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-oracle
export SCALA_HOME=/root/scala-2.11.11
export HADOOP_HOME=/root/hadoop-2.7.6
export HADOOP_CONF_DIR=/root/hadoop-2.7.6/etc/hadoop
export SPARK_MASTER_IP=localhost
export SPARK_WORKER_MEMORY=4g
export SPARK_EXECUTOR_MEMORY=4g
export SPARK_DRIVER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_MEM=4G
保存镜像
sudo docker commit 75bea785a41e ubuntu_bigdata
六.集群网络配置
开启容器
使用之前镜像创建5个容器
sudo docker run -d -it -h master0 -p 50070 -p 8088 --name master0 ubuntu_bigdata bash
–name bbbbb,表示这个容器的名字是bbbbb.
-h aaaaa,表示容器内的主机名为aaaaa.
-d ,表示detach模式.
-p 50070 -p 8088,表示将这个容器的端口50070和8088,绑定到你的主机上。
hd_image 镜像名
这时,就可以在外网中,用你的主机的eth0的ip再加上映射的端口号,访问你容器内的应用了。
sudo docker run -it ubuntu_bigdata /bin/bash
网络相关设置
对于每个容器,查看其IP,执行
ifconfig
计划作为master0 172.17.0.2 d6ab2641dcf3
计划作为master1 172.17.0.3 a15ae831e68b
计划作为slave1 172.17.0.4 207343b5d21d
计划作为slave2 172.17.0.5 br7d43b5d21d
计划作为slave3 172.17.0.6 e07343b5d21d
修改每个容器的hosts文件
vim /etc/hosts
增加如下内容:
172.17.0.2 d6ab2641dcf3 master0
172.17.0.3 a15ae831e68b master1
172.17.0.4 207343b5d21d slave0
172.17.0.5 a15ae831e68b slave2
172.17.0.6 207343b5d21d slave3
对于每个节点:启动ssh服务:
service ssh start
对于每个节点,将其ssh公钥拷贝到其它节点的认证密钥中:
ssh-copy-id -i ~/.ssh/id_rsa.pub 其它节点的主机名或者IP
可选:对于每个节点,ssh其它节点验证是否能免密登录:
七.zookeeper配置
修改配置
cd $ZKHOME/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改:dataDir=$ZKHOME/tmp
在最后添加:
server.1=slave0:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
保存退出
在dataDir设置的位置创建一个空文件myid
touch dataDir/myid
最后向该文件写入ID
echo 1 > $ZKHOME/tmp/myid
将配置好的zookeeper拷贝到其他节点
scp -r $ZKHOME slave1:~
scp -r $ZKHOME slave2:~
注意:修改slave02、slave03对应dataDir设置的位置/tmp/myid内容
slave02:
echo 2 > dataDir设置的位置/myid
slave03:
echo 3 > dataDir设置的位置/myid
=========zookeeper安装配置完毕。
可以用#zkServer.sh start来启动zookeeper了,
然后用#zkServer.sh status来查看三个zookeeper server上,哪个是leader,哪两个是follower。
启动
在slave1,slave2,slave0启动journalnode :
sbin/hadoop-daemon.sh start journalnode
在master0上执行命令:
hdfs namenode -format
在master1上执行:
hdfs namenode -bootstrapStandby
格式化ZKFC(在master0上执行即可)
hdfs zkfc -formatZK
启动zookeeper
在zookeeper的三格节点上执行
zkServer.sh start
然后在master0上执行
start-dfs.sh --启动分布式文件系统
start-yarn.sh --启动分布式计算
启动后各节点上的jps信息如下:
master0:
4961 Jps
4778 DFSZKFailoverController //zookeeper控制器进程(可以看作监控namenode的状态)
4465 NameNode //hdfs的namenode节点进程
4890 ResourceManager //yarn的resourcemanager节点进程
master1:
2984 DFSZKFailoverController
3059 Jps
2873 NameNode
slaver0,slaver1,slaver2:
5171 NodeManager //yarn的nodemanager进程
4311 QuorumPeerMain //zookeeper(选举)进程
4958 DataNode //hdfs的datanode进程
5292 Jps
5060 JournalNode //用于主备同步的journalNode进程
如果这几个进程都有的话,那么hadoop就算是运行起来了。其他一些单独启动某个进程的指令
#hdfs dfsadmin -report 查看hdfs的各节点状态信息
#hdfs haadmin -getServiceState nn1 获取一个namenode节点的HA状态
#hadoop-daemon.sh start namenode 单独启动一个namenode进程
#hadoop-daemon.sh start zkfc 单独启动一个zkfc进程
(*如果出现找不到命令的情况,看看环境变量是否配置好了,或者可以直接到hadoop的bin和sbin下调相应命令)
3.4,浏览器访问
到此,hadoop-2.6.2配置完毕,可以通过浏览器访问,查看节点信息:(win10的edge浏览器不行)
http://192.168.231.8:50070
NameNode ‘master01:9000’ (active)
http://192.168.231.9:50070
NameNode ‘master02:9000’ (standby)
可通过浏览器访问查看yarn任务信息(resourcemanager运行节点的ip)
http://192.168.231.8:8001(端口号是上面文件中配置的)
测试集群的高可用性
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /
然后再kill掉active的NameNode
kill -9
通过浏览器访问:http://192.168.231.9:50070
NameNode ‘master02:9000’ (active)
这个时候master02上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r–r-- 3 root supergroup 1926 2014-02-06 15:36 /profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode
通过浏览器访问:http://192.168.231.8:50070
NameNode ‘weekend01:9000’ (standby)
问题:不能完成主备namenode节点之间的自动切换?
查看配置hdfs-site.xml密匙文件位置是否配置正确
4.2,验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar wordcount /profile /out
可以在http://192.168.231.8:8001查看yarn任务的执行信息。还可以看到历史任务。
参考:
https://blog.csdn.net/tanjun592/article/details/72637954
https://blog.csdn.net/u014182745/article/details/78381472
https://blog.csdn.net/lslin405/article/details/69788322
https://blog.csdn.net/csj941227/article/details/80025066