利用 Python 进行量化投资分析 - 利率及风险资产的超额收益
本文是 利用 Python 进行量化投资分析 系列的第一篇文章,这个系列主要以 Python 作为工具,结果国内金融市场情况,及使用真实历史数据来实践一些基础的金融投资概念。
这篇文章主要讲述了真实利率及名义利率的区别,运用 Python 以及 Tushare 库来获取存款利率及 CPI 数据用来计算真实利率。同时,结合当前投资的实际情况,详细阐述了如何获取余额宝历史收益数据以及利用余额宝收益计算真实利率。接着,我们还探讨了利用近一年来沪深300指数与余额宝匹配,计算近一年来的沪深300超额收益率。
通过本文,你将能了解一下概念:
- 真实利率
- 名义利率
- 无风险收益率
- 超额收益
同时,你将能掌握以下使用Python进行量化投资分析的技巧:
- 通过 Tushre 库获取 CPI、存款利率数据
- 计算近似真实利率及准确的真实利率
- 通过编写爬虫程序,获取余额宝历史数据
- 计算资产持有期收益率 HPR
- 计算风险资产与无风险资产的超额收益率
真实利率与名义利率
假设一年前在银行存了 10,000 元人民币,期限一年,那么按一年定期利率 1.50% 计算,现在可以得到 10,150 元。而实际上,我们真实的收益取决于现在的 10,150元可以买多少东西以及一年前 10,000元可以买多少东西,针对这一问题,我们通常使用消费者物价指数(CPI)来代表通胀率,来分析我们的实际收益。
首先,我们先要得到历史的 CPI 数据,才能进行下一步分析。CPI 可以通过国家统计局公布的CPI数据查询,然而,我们在实际中,可以通过实用 Tushare 库中所封装好的方法获取实用。
# 获取近一年的 CPI 数据
import tushare as ts
cpi = ts.get_cpi()
cpi[:12]
>>>>> 输出结果 >>>>>
month cpi
0 2017.8 101.77
1 2017.7 101.40
2 2017.6 101.64
3 2017.5 101.04
4 2017.4 101.26
5 2017.3 99.98
6 2017.2 102.39
7 2017.1 101.99
8 2016.12 103.04
9 2016.11 102.25
10 2016.10 102.10
11 2016.9 101.90接下来,我们计算一下年均 CPI 涨幅:
yearly_cpi = sum(cpi['cpi'][:12]) / 12
yearly_cpi
>>>>> 输出结果 >>>>>
101.73这里我们就得到加权年均 CPI 为 101.73,即我们认为这一年的通胀率为 1.73%。这意味着我们手中的货币购买力在过去一年贬值 1.73%,那么我们的利益收益计算用于弥补通胀,那么最终实际增加的购买力是 -0.23%,也就是说,假如我们这一年把钱存银行定期,那么一年过去了,我们实际亏损 0.23%。
我们刚刚是通过名义利率减去通胀率来获得真实利率,这是一种近似的计算方法,我们舍名义利率为R,真实利率为r, 通胀率为i,计算公式如下:
![]()
严格意义上,名义利率和真实利率之间的关系,是购买力增长值等于货币增长值除以新的价格水平,即:
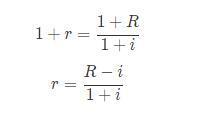
因此,我们可以编写一个函数,来计算精确的真实利率:
def accurate_real_interest_rate(nir, ir):
return (nir - ir) / (1 + ir)
arir = accurate_real_interest_rate(0.015, 0.0173)
arir
>>>>> 输出结果 >>>>>
-0.002260886660768701更符合真实情况的利率
伴随现在各种互联网金融工具的兴起,我们通常情况下不会将钱放到银行存定期,我们往往会购买各种短期、中长期的理财产品。然而, 由于不同的理财产品有着不同其期限以及其特殊的申购赎回方式,这里为了方便分析,我们选取了存取条件较为简单的余额宝作为新的工具用来分析。
获取余额宝历史数据的方法可以参考 《利用 Python 获取余额宝历史收益数据》一文,具体代码入下:
# 获取余额宝历史数据
import requests
import bs4
import pandas as pd
SYMBOL_YEBAO = '000198'
def obtain_info_of_data(symbol):
response = requests.get('http://fund.eastmoney.com/f10/F10DataApi.aspx?type=lsjz&code=' + str(symbol))
# return format: var apidata={...};
# filter the tag
content = str(response.text.encode('utf8')[13:-2])
content_split = content.split(',')
# obtain the info of data, curpage, pages, records
curpage = content_split[-1].split(':')[-1]
pages = content_split[-2].split(':')[-1]
records = content_split[-3].split(':')[-1]
return {'curpage': curpage, 'pages': pages, 'records': records}
def obtain_data(symbol):
dict_data_info = obtain_info_of_data(symbol)
cur_pages = int(dict_data_info['pages'])
pages = dict_data_info['pages']
records = dict_data_info['records']
data_return = []
url = 'http://fund.eastmoney.com/f10/F10DataApi.aspx?type=lsjz&code=%s&page=%s'
for cp in range(int(pages), 0, -1):
response = requests.get(url % (symbol, str(cp)))
content = response.text[13:-2]
data = content.split(',')[0][10:-1]
data_soup = bs4.BeautifulSoup(data, 'lxml')
line_of_data = len(data_soup.select('table > tbody > tr'))
for i in range(line_of_data, 0, -1):
row_of_data = []
date = data_soup.select('table > tbody > tr:nth-of-type(%i) > td:nth-of-type(1)' % i)[0].text
earning_per_10k = float(data_soup.select('table > tbody > tr:nth-of-type(%i) > td:nth-of-type(2)' % i)[0].text) / 10000.0
annualized_return = float(data_soup.select('table > tbody > tr:nth-of-type(%i) > td:nth-of-type(3)' % i)[0].text[:-1]) / 100.0
row_of_data.append(date)
row_of_data.append(earning_per_10k)
row_of_data.append(annualized_return)
data_return.append(row_of_data)
print('Finished %i' % cp)
cur_pages -= 1
if cur_pages == 1 and len(data_return) != int(records):
print('Data Missing..')
return pd.DataFrame(data_return, columns=["date", "rate10k", "rate7d"])
# data_info = obtain_info_of_data(SYMBOL_YEBAO)
rs = obtain_data(SYMBOL_YEBAO)接下来,我们将计算最近一年的余额宝收益:
yeb_yearly_rate = sum(rs[-360:]["rate7d"]) / 360 # rs 为上文 rs = obtain_data(SYMBOL_YEBAO) 获得
yeb_yearly_rate
>>>>> 输出结果 >>>>>
0.035411472222222247我们这里得到余额宝近一年的收益为 3.54%,比上文获取到的一年期银行利率高,我们再次用上面的真实利率函数计算一下余额宝的真实收益率:
# 余额宝真实收益率
yeb_arir = accurate_real_interest_rate(yeb_yearly_rate, 0.0173)
yeb_arir
>>>>> 输出结果 >>>>>
0.01780347215395876我们可以看到,最近一年,将钱用于购买余额宝,真实的收益率是可以达到正数的。
无风险利率与风险资产的超额收益
在分析风险之前,我们先了解一个概念 —— 持有期收益率 HPR,所谓持有期收益率,就是资产期末价格与期初价格之差除以期初价格。用公式表示如下:
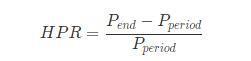
如果是股票类资产,还需要考虑现金红利以及除权等问题。
接下来,我们以沪深300指数为例,计算持有一年收益率:
# 获取沪深300历史数据
hs300 = ts.get_k_data("hs300")
# 计算 HPR 函数
def hpr(endPrice, periodPrice):
endPrice = float(endPrice)
periodPrice = float(periodPrice)
return (endPrice - periodPrice) / periodPrice
hpr_yearly = hpr(hs300[hs300["date"] == "2017-09-25"]["close"], hs300[hs300["date"] == "2017-01-03"]["close"])
hpr_yearly
>>>>> 输出结果 >>>>>
0.14228823270690524我们从上面程序运行结果可以得出,最近一年,沪深300指数的年均收益率为14.22%。
接下来,我们继续探讨另外一个概念 —— 超额收益 excess return,所谓超额收益,就是指特定时期风险资产同无风险资产之间的差,用公式表示:
![]()
我们同样编写一个计算超额收益的函数,用来计算近一年来 余额宝-沪深300指数 之间的超额收益。
# 计算超额收益函数
def excess_return(rp, rfr):
return rp - rfr
yeb_hs300_er = excess_return(hpr_yearly, yeb_yearly_rate)
yeb_hs300_er
>>>>> 输出结果 >>>>>
0.106876760484683通过运行上面的程序,我们可以计算出,近一年来,投资沪深300指数的超额收益为 10.69%。
小结
通过这篇文章,我们了解了什么是名义利率、真实利率,以及如何计算近似和准确的真实利率,同时,我们还知道了什么是无风险资产和风险资产的超额收益。此外,我们还掌握了如何借助 Tushare 库来获取历史存款利率数据以及 CPI 历史数据,还了解了如何使用爬虫程序来获取余额宝历史数据。
参考资料
[1] 滋维·博迪.投资学(原书第7版) [9787111269441].机械工业出版社