解决spark saveAsTable生成的parquet格式的表的问题
问题一:直接在命令行创建的parquet格式的表通过spark saveAsTable 无法写入
1.建表语句
CREATE TABLE parquet_test (
name string,
sex string,
age int
)
STORED AS PARQUET;
2.查看表结构

3.通过代码直接save
//save 主要代码
sparksession.createDataFrame(rdd1).write.mode("append").saveAsTable("parquet_test")
//因为spark默认格式为parquet,所以format("parquet")写于不写影响不大
//sparksession.createDataFrame(rdd1).write.format("parquet").mode("append").saveAsTable("parquet_test")
直接save发现会报错,然后将写入的表名字换掉让spark自动去建表,然后去查看和上边的表有什么不同
4.查看spark自动建表的表结构
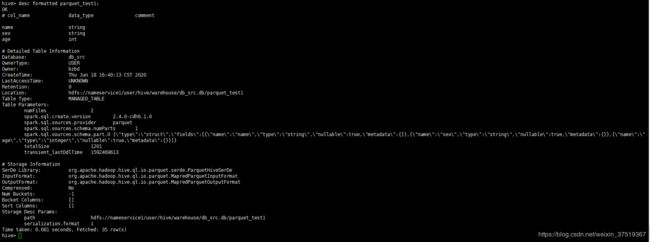
5.根据不同的报错信息对表结构进行修改
//报错信息
Exception in thread "main" org.apache.spark.sql.AnalysisException: The format of the existing table db_src.parquet_test is `HiveFileFormat`. It doesn't match the specified format `ParquetFileFormat`.;
//解决办法
ALTER TABLE parquet_test SET TBLPROPERTIES ('spark.sql.sources.provider'='parquet');
//报错信息
Exception in thread "main" org.apache.spark.sql.AnalysisException: The column number of the existing table db_src.parquet_test(struct<>) doesn't match the data schema(struct<name:string,sex:string,age:int>);
//解决办法
ALTER TABLE parquet_test SET TBLPROPERTIES ('spark.sql.sources.schema.part.0'='{\"type\":\"struct\",\"fields\":[{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"sex\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"age\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}}]}');
//报错信息
Exception in thread "main" org.apache.spark.sql.AnalysisException: Could not read schema from the hive metastore because it is corrupted.;
//解决办法
ALTER TABLE parquet_test SET TBLPROPERTIES ('spark.sql.sources.schema.numParts'='1');
//报错信息
Exception in thread "main" java.lang.IllegalArgumentException: Expected exactly one path to be specified, but got:
//解决办法
ALTER TABLE parquet_test SET SERDEPROPERTIES ('path'='hdfs://nameservice1/user/hive/warehouse/db_src.db/parquet_test');
将上述操作做完之后就能正常写入,需要注意的是不同的环境可能修改的参数不同,我是在生产和测试两个环境修改的参数都不一样,主要思路就是根据报错信息,选择性的进行参数修改。另外也可以在建表的时候直接指定参数,但是我这里没有成功,下面我会贴出来hive官方文档的建表语句,如果后面我试验成功了,我会继续分享出来
6.官方文档,详细的建表语句
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
array_type
: ARRAY < data_type >
map_type
: MAP < primitive_type, data_type >
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
问题二:对已经存在的表进行加字段
//添加字段class
alter table test_mm add columns(class string);
//在schema增加class的信息
ALTER TABLE test_mm SET TBLPROPERTIES ('spark.sql.sources.schema.part.0'='{\"type\":\"struct\",\"fields\":[{\"name\":\"name\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"sex\",\"type\":\"string\",\"nullable\":true,\"metadata\":{}},{\"name\":\"age\",\"type\":\"integer\",\"nullable\":true,\"metadata\":{}},{\"name\":\"class \",\"type\":\"string\",\"nullable\":true,\"metadata\":{}}]}');
如有不对的地方,欢迎大家指正