SCNN:对交通场景的语义分割--源码及原文阅读
摘要
常规的CNN网络就是由一层一层的卷积层堆叠的.但是,普通的卷积并不能很好地利用像素探索图像的行列信息(空间信息).充分捕捉像素的空间信息对于拥有很强形状先验\很弱外观连接性的语义目标(例如车道线)来说很重要.在交通场景中,车道线经常被遮挡甚至没有画在图像中(也就是完全遮挡了),如下图所示:
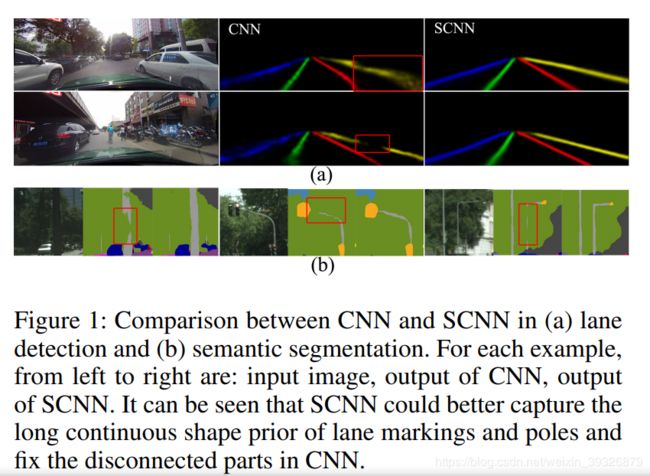
本文提出了SCNN,不同于传统的CNN一层一层卷积的连接,本文采用了一片一片的卷积,这使得每层的像素信息可以在行列间流动.SCNN有利于有强空间相关但无纹理信息的大目标,例如车道线\杆\强,我们应用SCNN在车道线检测数据集上,对比基于ReNet的RNN和MRF+CNN,分别比它们提升了8.7%和4.6%,同时在车道线检测挑战赛赢得了第一名,准确率为96.53%.
介绍
作者的贡献还在于提供了车道线数据集.现有的车道线数据量很小,场景单一,图片中都是清晰的车道线.作者提供的图片不仅有磨损的车道线,还有遮挡以及遮挡到看不见的车道线,这更加接近于真实情况.为了收集数据,作者将相机放在六辆不同的车上,由不同的司机驾驶,在不同的时间,在北京采集数据,关于数据集的标注,每一帧都是手动标注的,对于有些遮挡和看不见,也是根据周围信息手工标注的,依据大多数场景,每张图片标注四条车道线,多了的也不再标注.
Spatial CNN
传统的对空间关系建模的方法是马尔科夫链或者条件随机链.
由下图可以看出,两种方法都是先通过CNN获得输出HW*C(其中HW跟原图一样大小,C是语义分割的分割个数),但是,它们获得最终预测图的后处理却是不相同的.
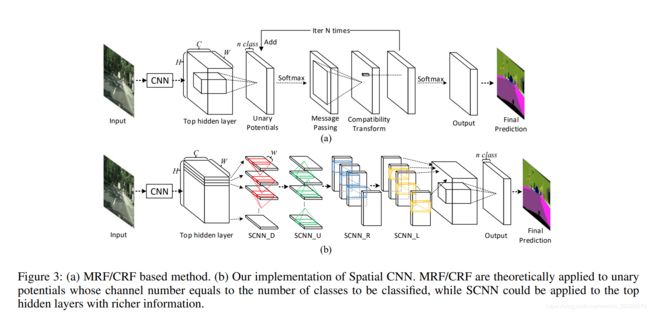
马尔可夫后处理的过程如下:1.归一化,通过softmax对每层特征图归一化;2.信息传输,用大的卷积核进行通道卷积(对于CRF而言,用跟原图一样大的卷积核,卷积核参数取决于输入图片);3.兼容性变换,通过1X1的卷积实现;4.增加一元的potentials,这个过程迭代N次再给出最终的结果.可以看出,在信息传输的过程中采用了传统算法,每一个像素要接受其他像素的信息,计算量很大,很难应用在实时的自动驾驶技术中,而且如此大的卷积核也很难去学习和初始化,但是这是用在top hidden layer,一个包含丰富信息的层,在这里运用空间卷积是很好的.为了解决这个问题,为了更有效地学习空间关系和平滑连续的车道线,或者其他交通标志,我们提出了SCNN,这里的空间指的不是空间卷积,而是通过特殊的方式在CNN结构中传输空间信息.
如上图所示,HWC的tensor要被分成H片,第一片用C个大小为C*w的卷积核进行卷积(其中w为卷积核宽度,在传统CNN当前特征图是要送到下一层进行卷积,但在这里,输出要添加到下一个片以此产生一个新的片,新的片送到下一个卷积层,这个过程一直持续知道最后一个片也被更新.
特别地,假设我们有一个3D的核K,其中i,j,k代表最后一片i通道的元素\当前片j通道的元素\两个元素K列之间的差别,对于输入的3Dtensor X ,其中i,j,k代表通道\行\列,然后SCNN的计算公式如下:
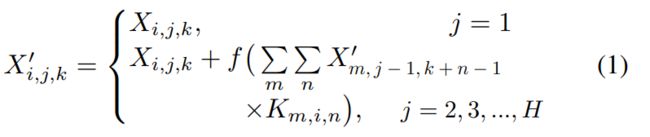
其中f是Relu(非线性的激活函数),带有上标’代表是已经更新的.卷积核的参数被所有片共享,SCNN是一种回归神经网络,同时SCNN是有方向的,四个SCNN的模块下表为D、U、R、L分别代表向下的、向上的、向右的、向左的。
分析
相比于传统的网络,SCNN主要由以下三个优势:
1.计算量更有效,在dense MRF/CRF中,每一个像素要接受其他所有像素的信息,会有大量冗余.但在SCNN中是序列传输的方式.具体如下图所示:
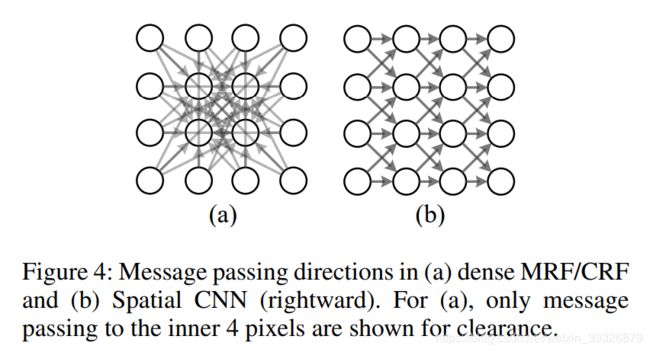
假设tensor有H行W列,在dense MRF/CRF中,信息在两个WH像素中传递,在n次迭代中,信息传递的数量是n_iterWWHH.在SCNN中,每一个像素仅仅从w个像素中接受信息,信息传递的数量n_dirWH*w,n_dir代表传输方向,w代表kernel大小,n_iter从10到100,在本文中n_dir设置为4,因为有四个方向,w通常小于10(本例中为3),对比可以看出,SCNN可以大大节约计算量,同时每个像素可以通过四个方向的传播接受其他所有像素的信息。
2.SCNN使用了残差,在深度网络里面可有利于训练;
3.灵活性,可以灵活更换骨干网络。
训练
我们使用LargeFov作为前置网络(前面13层是已经在ImagNet数据集上训练好的VGG),使用SGD,batch_size=12,lr=0.01,momentuom=0.9等等。我们的输出是要得到四张预测图,然后在测试阶段,我们需要从预测图获得曲线,当lane marking的存在可能超过0.5,我们在对应的置信图每20行取一个最高的响应值,然后所有的这些位置通过3次样条插值连接起来,作为最终的预测结果。
我们的baseline模型跟largeFov有一些细节上的区别,如下图所示:(1)全连接层fc7的输出被设置为128,(2)每一个relu后面都加上了batchNorm,(3)添加了一个小网络看车道线是否存在。在训练过程中,目标的线宽被设置为16个像素,输入和输出图都被resize成800X288,考虑到在label中目标和背景并不平衡,背景的loss要乘上0.4。
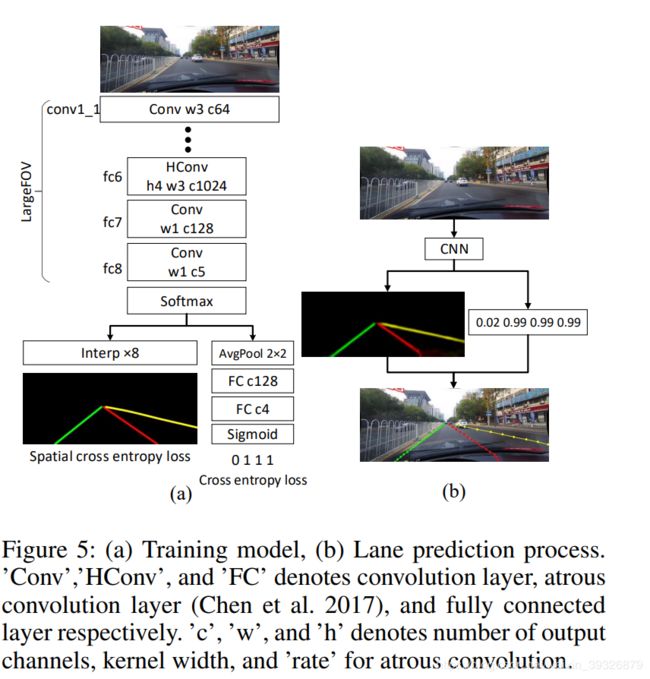
评估
我们把车道线假设成像素宽度为30的曲线,使用IOU重合度来作为衡量,将0.3和0.5作为松的和严格的标准。

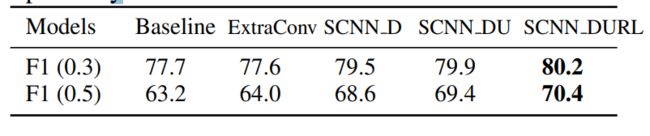
(1)关于多方向SCNN的有效性
为了对比多方向的SCNN的好处,我们添加了一个额外的5X5的卷积核的卷积网路作为对比:
其中F1代表F1-measure
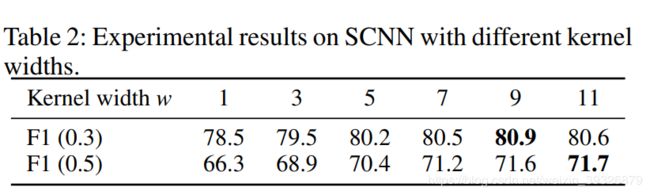
(2)关于kernel 宽度w的有效性
w代表一个像素能接受多少个周围像素的信息,w=9最好,对比baseline,两种不同的IOU阈值分别能提升8.4%和3.2%.
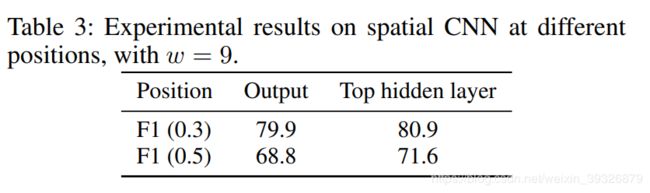
(3)SCNN接在不同的位置
前面说过SCNN可以接在不同的位置,接在output和top hidden layer之后有区别,如下图所示:
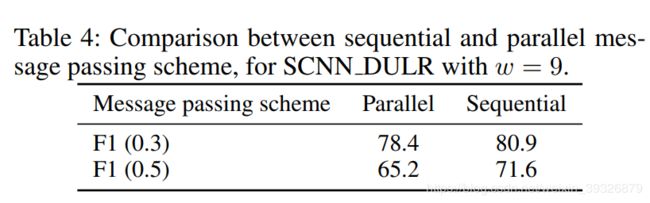
(3)验证连续传播的有效性
一个片收集完前面所有片的信息后,才传递给下一个片,我们对比一个同步方案,每一个片同步传输给下一个片,对比结果如下:,其结果很好地说明了一个像素不仅受周围像素的影响,也受远距离位置的像素的影响。
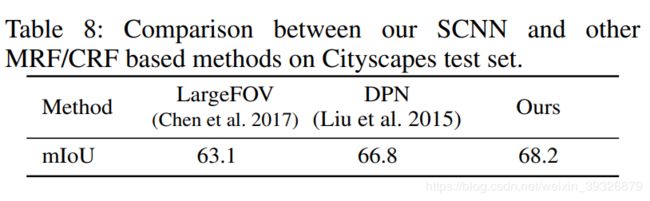
(4)为了证明我们的方案的优越性,我们对比了其他一些主流受欢迎的方案,结果如下。

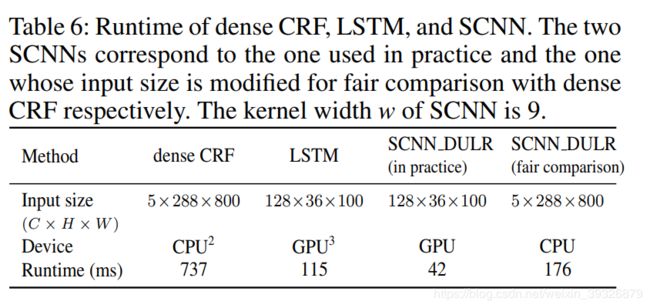
接下来给出了时间上的对比,证明SCNN比CRF计算更有效:
为了验证SCNN的有效性,我们在Cityscapes数据集上也进行了测试,结果如下:

之所以SCNN能取得比较好的效果,是因为对于长形状的物体,SCNN能够很好地捕捉其连续的结构并将不连接的地方连接起来,对于墙面、卡车等大物体,SCNN可以根据上下文的信息纠正错误分类的地方,这说明SCNN不仅适用于细长的结构,同样适用于大目标,因为SCNN很好地利用了全局的信息,但是有另外一个有趣的现象,就是车辆位于图片的顶端,在训练的时候漏了label,然后分类出来的结果是道路,这也是因为SCNN的扩散影响将车辆的头部区域也分类为道路。
为了验证我们方法的有效性,我们还进行了如下实验:
总结
本文提出了SCNN,充分利用了传播过程中的空间信息,可以很容易地接在深度网络后面,且可以进行端到端的训练,结果证明SCNN不仅对于长条状的物体有效,对于大目标也很有效,我们20层的网络比101层的Resnet的效果还要好.
代码阅读
前置网络不重要,我们主要看看SCNN的建立过程,以下代码来自github,注释自己加上去的(lua语言)
require 'nn'
require 'cudnn'
#载入VGG为前置网络
model = torch.load('vgg/vgg.t7')
last = model:get(43)
#Seq:add(buildPass(1,1,dim,s,9))
#Seq:add(buildPass(2,1,dim,s,9))
#dim=(128,1)
#scale=7
function buildPass(d,width,dim,scale,kw) --d=1:down-up d=2:right-left
local pass = nn.Sequential()
local length = 0
if d==1 then
Num = 36/scale
length = 100/scale
else
Num = 100/scale
length = 36/scale
end
local num = Num/width
local function buildParal()
local seq = nn.Sequential()
#Tensor=batch+channel+H+W
#nn.SplitTable按维度将Tensor划分成tables
#在这里是按照第三个维度进行划分,具体原因参照https://github.com/torch/nn/blob/master/SplitTable.lua#L13
#所以是按照H划分得
seq:add(nn.SplitTable(d+1, 3)) --128 36
-- view fom 100 to 1,1,100
local paralView = nn.ParallelTable()
for i=1,Num do
local view = nn.Sequential()
view:add(nn.Contiguous())
if d==1 then
view:add(nn.View(dim, 1, length):setNumInputDims(2))
else
view:add(nn.View(dim, length, 1):setNumInputDims(2))
end
paralView:add(view)
end
seq:add(paralView)
if width > 1 then
local concatM = nn.ConcatTable()
for i=1,num do
local merge = nn.Sequential()
merge:add(nn.NarrowTable((i-1)*width+1,width))
merge:add(nn.JoinTable(d+1,3))
concatM:add(merge) -- 128,36,2 * 50
end
seq:add(concatM)
end
local concat = nn.ConcatTable()
local part1 = nn.Sequential()
part1:add(nn.SelectTable(1))
local conv, conv2
if d==2 then
conv = cudnn.SpatialConvolution(dim,dim,1,kw,1,1,0,(kw-1)/2)
conv2 = cudnn.SpatialConvolution(dim,dim,1,kw,1,1,0,(kw-1)/2)
else
conv = cudnn.SpatialConvolution(dim,dim,kw,1,1,1,(kw-1)/2,0)
conv2 = cudnn.SpatialConvolution(dim,dim,kw,1,1,1,(kw-1)/2,0)
end
conv.bias = nil
conv.gradBias = nil
conv.weight:normal(0,math.sqrt(2/(kw*dim*dim*5)))
conv2.bias = nil
conv2.gradBias = nil
conv2.weight:normal(0,math.sqrt(2/(kw*dim*dim*5)))
local function buildConcat(d)
local conc = nn.ConcatTable()
if d == true then
conc:add(nn.Identity())
local seq = nn.Sequential()
seq:add(conv:clone('weight','bias','gradWeight','gradBias'))
seq:add(nn.ReLU(true))
conc:add(seq)
else
local seq = nn.Sequential()
seq:add(conv2:clone('weight','bias','gradWeight','gradBias'))
seq:add(nn.ReLU(true))
conc:add(seq)
conc:add(nn.Identity())
end
return conc
end
part1:add(buildConcat(true))
concat:add(part1)
concat:add(nn.NarrowTable(2,num-1))
seq:add(concat) -- {1, 1s}, {2, 3, ..., 18}
seq:add(nn.FlattenTable())
-- pass the rest 34+1 times
for i = 1,num-1 do
local concat = nn.ConcatTable()
local part2 = nn.Sequential()
part2:add(nn.NarrowTable(i+1, 2))
part2:add(nn.CAddTable())
if i~=num-1 then
part2:add(buildConcat(true))
else
part2:add(buildConcat(false))
end
if i==1 then
concat:add(nn.SelectTable(1))
else
concat:add(nn.NarrowTable(1, i))
end
concat:add(part2)
if i==num-2 then
concat:add(nn.SelectTable(num+1))
elseif i~=num-1 then
concat:add(nn.NarrowTable(i+3, num-1-i))
end
seq:add(concat)
seq:add(nn.FlattenTable())
end -- {1, 2', 3', ..., 17'}, {18's, 18'}
for i = 1,num-1 do
local concat = nn.ConcatTable()
local part2 = nn.Sequential()
part2:add(nn.NarrowTable(num-i, 2))
part2:add(nn.CAddTable())
if i~=num-1 then
part2:add(buildConcat(false))
end
if i==num-2 then
concat:add(nn.SelectTable(1))
elseif i~=num-1 then
concat:add(nn.NarrowTable(1, num-1-i))
end
concat:add(part2)
if i==1 then
concat:add(nn.SelectTable(num+1))
else
concat:add(nn.NarrowTable(num+2-i, i))
end
seq:add(concat)
seq:add(nn.FlattenTable())
end -- {1', 2'', 3'', ..., 17'', 18'}
seq:add(nn.JoinTable(d+1,3)) --128,36,100
return seq
end
pass:add(buildParal())
return pass
end
function buildSCNN(dim, s)
local Seq = nn.Sequential()
#显示对H进行拆分
Seq:add(buildPass(1,1,dim,s,9))
#然后对W进行拆分
Seq:add(buildPass(2,1,dim,s,9))
return Seq
end
#建立SCNN网络
last:insert(buildSCNN(128, 1),7)
print(model)
#VGG+SCNN(w=9)
torch.save('vgg_SCNN_DULR_w9/vgg_SCNN_DULR_w9.t7', model)
lua语言的大致能看懂,细节太难看懂了,下面来看看一目了然的python版的SCNN
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
class SCNN(nn.Module):
def __init__(
self,
input_size,
ms_ks=9,
pretrained=True
):
"""
Argument
ms_ks: kernel size in message passing conv
"""
super(SCNN, self).__init__()
self.pretrained = pretrained
self.net_init(input_size, ms_ks)
if not pretrained:
self.weight_init()
self.scale_background = 0.4
self.scale_seg = 1.0
self.scale_exist = 0.1
self.ce_loss = nn.CrossEntropyLoss(weight=torch.tensor([self.scale_background, 1, 1, 1, 1]))
self.bce_loss = nn.BCELoss()
def forward(self, img, seg_gt=None, exist_gt=None):
#首先,前面有一个backbone网络
x = self.backbone(img)
#然后第一个layer1执行了空洞卷积,BN,1*1的降维卷积
x = self.layer1(x)
#这里将特征图切片,从上往下切,每一片与之前更新的前面所有片的信息融合
#然后是从下往上
#然后是从左往右
#然后是从右往左
x = self.message_passing_forward(x)
#layer2进行dropout和1*1的降维卷积
x = self.layer2(x)
#双线性插值恢复指定倍数
seg_pred = F.interpolate(x, scale_factor=8, mode='bilinear', align_corners=True)
#后面是另外一个分支判断lane是否存在
#layer3 是softmax和2*2的pooling
x = self.layer3(x)
x = x.view(-1, self.fc_input_feature)
#linear和sigmoid,输出是四个值,代表四个lane是否存在的置信度
exist_pred = self.fc(x)
if seg_gt is not None and exist_gt is not None:
#语义分割的loss是多分类loss,所以使用CEloss
loss_seg = self.ce_loss(seg_pred, seg_gt)
#是否存在是二分类loss,所以使用bceloss
loss_exist = self.bce_loss(exist_pred, exist_gt)
#两个以一定系数相乘
loss = loss_seg * self.scale_seg + loss_exist * self.scale_exist
else:
#如果gt中不含有lane,那么loss=0
loss_seg = torch.tensor(0, dtype=img.dtype, device=img.device)
loss_exist = torch.tensor(0, dtype=img.dtype, device=img.device)
loss = torch.tensor(0, dtype=img.dtype, device=img.device)
return seg_pred, exist_pred, loss_seg, loss_exist, loss
#在这里进行上下\下上\左右\右左的信息传递
def message_passing_forward(self, x):
Vertical = [True, True, False, False]
Reverse = [False, True, False, True]
for ms_conv, v, r in zip(self.message_passing, Vertical, Reverse):
x = self.message_passing_once(x, ms_conv, v, r)
return x
#这里进行单次单方向的message passing
def message_passing_once(self, x, conv, vertical=True, reverse=False):
"""
Argument:
----------
x: input tensor
vertical: vertical message passing or horizontal
reverse: False for up-down or left-right, True for down-up or right-left
"""
nB, C, H, W = x.shape
#按照是垂直还是水平进行切片
if vertical:
slices = [x[:, :, i:(i + 1), :] for i in range(H)]
dim = 2
else:
slices = [x[:, :, :, i:(i + 1)] for i in range(W)]
dim = 3
#这里的reverse决定了要不要反向传输,譬如本来信息从上到下融合,要不要变成从下到上
if reverse:
slices = slices[::-1]
out = [slices[0]]
#当前层要更新,要加上之前累加的卷积结果
for i in range(1, len(slices)):
out.append(slices[i] + F.relu(conv(out[i - 1])))
if reverse:
out = out[::-1]
#将out的slices拼接成跟原始一样大的图
return torch.cat(out, dim=dim)
def net_init(self, input_size, ms_ks):
#先进行参数初始化
input_w, input_h = input_size
self.fc_input_feature = 5 * int(input_w/16) * int(input_h/16)
self.backbone = models.vgg16_bn(pretrained=self.pretrained).features
# ----------------- process backbone -----------------
for i in [34, 37, 40]:
conv = self.backbone._modules[str(i)]
dilated_conv = nn.Conv2d(
conv.in_channels, conv.out_channels, conv.kernel_size, stride=conv.stride,
padding=tuple(p * 2 for p in conv.padding), dilation=2, bias=(conv.bias is not None)
)
dilated_conv.load_state_dict(conv.state_dict())
self.backbone._modules[str(i)] = dilated_conv
#将backbone中的VGG中的全连接层去掉
self.backbone._modules.pop('33')
self.backbone._modules.pop('43')
# ----------------- SCNN part -----------------
#什么是空洞卷积https://www.zhihu.com/question/54149221
#空洞卷积+BN+RELU+1*1降维卷积+RELU
self.layer1 = nn.Sequential(
nn.Conv2d(512, 1024, 3, padding=4, dilation=4, bias=False),
nn.BatchNorm2d(1024),
nn.ReLU(),
nn.Conv2d(1024, 128, 1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU() # (nB, 128, 36, 100)
)
# ----------------- add message passing -----------------
#这是信息融合模块,包含了从上到下\从下到上\从左到右\从右到左
self.message_passing = nn.ModuleList()
self.message_passing.add_module('up_down', nn.Conv2d(128, 128, (1, ms_ks), padding=(0, ms_ks // 2), bias=False))
self.message_passing.add_module('down_up', nn.Conv2d(128, 128, (1, ms_ks), padding=(0, ms_ks // 2), bias=False))
self.message_passing.add_module('left_right',
nn.Conv2d(128, 128, (ms_ks, 1), padding=(ms_ks // 2, 0), bias=False))
self.message_passing.add_module('right_left',
nn.Conv2d(128, 128, (ms_ks, 1), padding=(ms_ks // 2, 0), bias=False))
# (nB, 128, 36, 100)
# ----------------- SCNN part -----------------
#dropout和1*1降维卷积
self.layer2 = nn.Sequential(
nn.Dropout2d(0.1),
nn.Conv2d(128, 5, 1) # get (nB, 5, 36, 100)
)
self.layer3 = nn.Sequential(
nn.Softmax(dim=1), # (nB, 5, 36, 100)
nn.AvgPool2d(2, 2), # (nB, 5, 18, 50)
)
#为了获得分类结果的fc
self.fc = nn.Sequential(
nn.Linear(self.fc_input_feature, 128),
nn.ReLU(),
nn.Linear(128, 4),
nn.Sigmoid()
)
def weight_init(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
m.reset_parameters()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data[:] = 1.
m.bias.data.zero_()
接下来看看评估过程中IOU计算的代码:
#这里是判断两条车道线的相似度
double LaneCompare::get_lane_similarity(const vector<Point2f> &lane1, const vector<Point2f> &lane2)
{
#每条车道线里面至少有两个点,因为单个点根本不能成为一条线
if(lane1.size()<2 || lane2.size()<2)
{
cerr<<"lane size must be greater or equal to 2"<<endl;
return 0;
}
#造两张值为全0的图
Mat im1 = Mat::zeros(im_height, im_width, CV_8UC1);
Mat im2 = Mat::zeros(im_height, im_width, CV_8UC1);
// draw lines on im1 and im2
vector<Point2f> p_interp1;
vector<Point2f> p_interp2;
if(lane1.size() == 2)
{
p_interp1 = lane1;
}
else
{
p_interp1 = splineSolver.splineInterpTimes(lane1, 50);
}
if(lane2.size() == 2)
{
p_interp2 = lane2;
}
else
{
p_interp2 = splineSolver.splineInterpTimes(lane2, 50);
}
#以一定线宽把点在图像上画出来
Scalar color_white = Scalar(1);
for(int n=0; n<p_interp1.size()-1; n++)
{
line(im1, p_interp1[n], p_interp1[n+1], color_white, lane_width);
}
for(int n=0; n<p_interp2.size()-1; n++)
{
line(im2, p_interp2[n], p_interp2[n+1], color_white, lane_width);
}
double sum_1 = cv::sum(im1).val[0];
double sum_2 = cv::sum(im2).val[0];
#计算重合的像素个数
double inter_sum = cv::sum(im1.mul(im2)).val[0];
#计算总的像素的个数
double union_sum = sum_1 + sum_2 - inter_sum;
#计算IOU
double iou = inter_sum / union_sum;
return iou;
}
// resize the lane from Size(curr_width, curr_height) to Size(im_width, im_height)
void LaneCompare::resize_lane(vector<Point2f> &curr_lane, int curr_width, int curr_height)
{
if(curr_width == im_width && curr_height == im_height)
{
return;
}
double x_scale = im_width/(double)curr_width;
double y_scale = im_height/(double)curr_height;
for(int n=0; n<curr_lane.size(); n++)
{
curr_lane[n] = Point2f(curr_lane[n].x*x_scale, curr_lane[n].y*y_scale);
}
}