经典CNN网络(Lenet、Alexnet、GooleNet、VGG、ResNet、DenseNet)
Lenet(1986)
主要用于识别10个手写邮政编码数字,5*5卷积核,stride=1,最大池化。

Alexnet(2012)
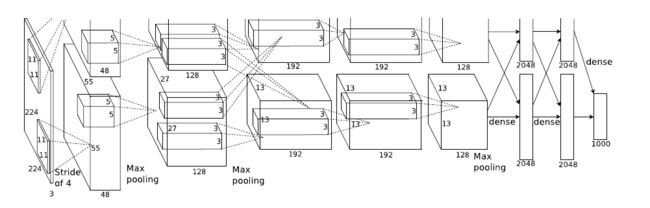
卷积部分都是画成上下两块,意思是说把这一层计算出来的feature map分开,但是前一层用到的数据要看连接的虚线。
引入Group群卷积概念,最早是为了应对训练时硬件限制问题,额外的好处是减少参数,抑制过拟合,具体做法是:假设上一层的输出feature map有N个,即通道数channel=N,也就是说上一层有N个卷积核。再假设群卷积的群数目M。那么该群卷积层的操作就是,先将channel分成M份。每一个group对应N/M个channel,与之独立连接。然后各个group卷积完成后将输出叠在一起(concatenate),作为这一层的输出channel。
局部响应归一化LRN:利用前后几层(对应位置的点)对中间这一层做一下平滑约束,增加泛化能力,公式为:
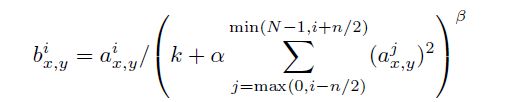

GooleNet(2014)
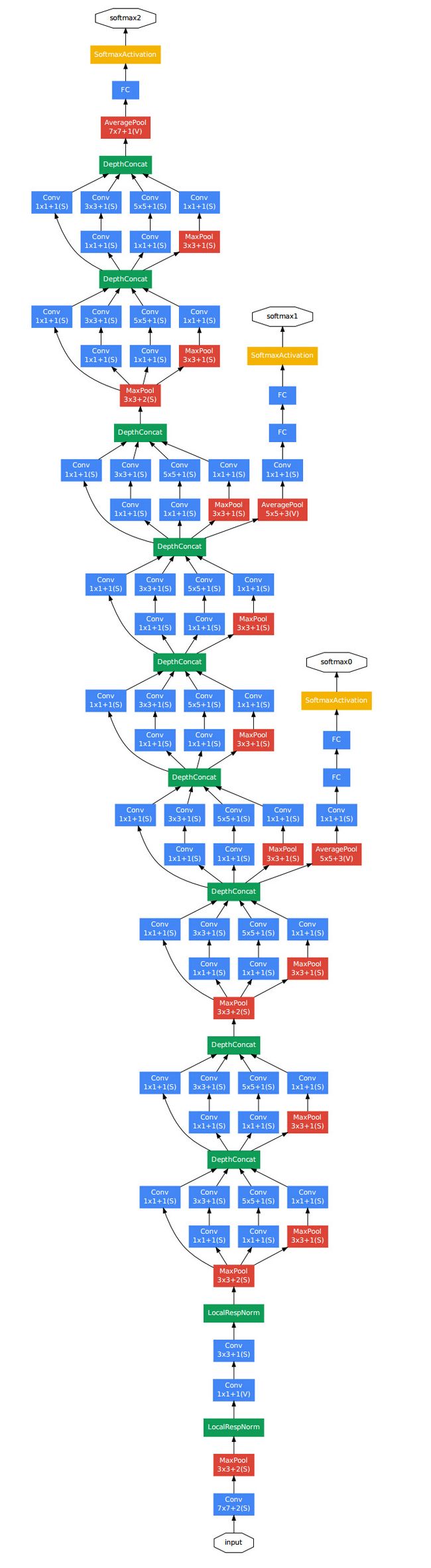
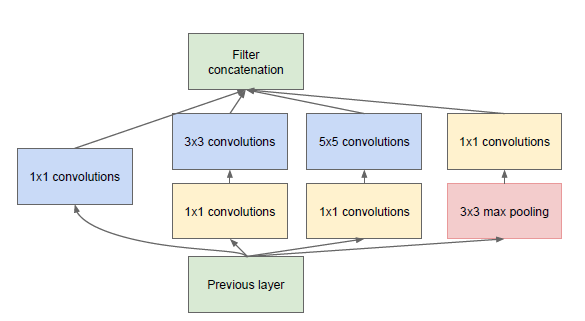
inception的结构,一分四,然后做一些不同大小的卷积,之后再堆叠feature map。
Googlenet的核心思想是inception,通过不垂直堆砌层的方法得到更深的网络(我的理解是变宽且视野范围种类多)
这里黄色的1*1的卷积核是改进googlenet时添加的(最初没有这种设计),目的是降低输入层维度,例如50通道的200*200 Feature map 通过20个1*1卷积核后输出为20通道的200*200 Feature map。中间过程是跨通道线性聚合feature map。
1*1卷积核的主要作用:1.降维 2.使网络更深 3.增加RELU等非线性(图中每一个a*a卷积都是conv+BN+relu的操作)。
VGG(2014)
由5层卷积层、3层全连接层、softmax输出层构成。用了3*3的卷积核(c模型用了1*1的卷积核,但一般都只用d、e模型,1*1不必管它),步长stride=1,padding=1,max池化,pooling窗口为2*2,pooling步长为2
VGG系列网络使用的是3x3的小卷积核,这是有中心和上下左右的最小单元(中心+八邻域);两个3x3的卷积层连在一起可视为5x5的filter,三个连在一起可视为一个7x7的。和大卷积核相比:(1)可以减少参数(2)进行了更多的非线性映射,增加网络的拟合、表达能力。
VGG缺陷:参数量大,有140M
需要注意到LRN只在A-LRN出现,且A-LRN结果没有A好,说明LRN作用不大。A效果不如更深的BCDE;B与C比较:增加1x1filter,增加了额外的非线性提升效果;与D比较:3x3 的filter(结构D)比1x1(结构C)的效果好。
全连层的作用:从特征空间映射到样本标记空间。
可以顺便看一下卷积层代替全连层的说明。
假设最后一个卷积层的输出为7×7×512,连接此卷积层的全连接层为1×1×4096。连接层实际就是卷积核大小为上层特征大小的卷积运算,卷积后的结果为一个节点,就对应全连接层的一个点。如果将这个全连接层转化为卷积层:
1.共有4096组滤波器
2.每组滤波器含有512个卷积核
3.每个卷积核的大小为7×7
4.则输出为1×1×4096
------------------------------------------
若后面再连接一个1×1×4096全连接层。相当于就是将特征组合起来进行4096个分类分数的计算,得分最高的就是划到的正确的类别。则其对应的转换后的卷积层的参数为:
1.共有4096组滤波器
2.每组滤波器含有4096个卷积核
3.每个卷积核的大小为1×1
4.输出为1X1X4096
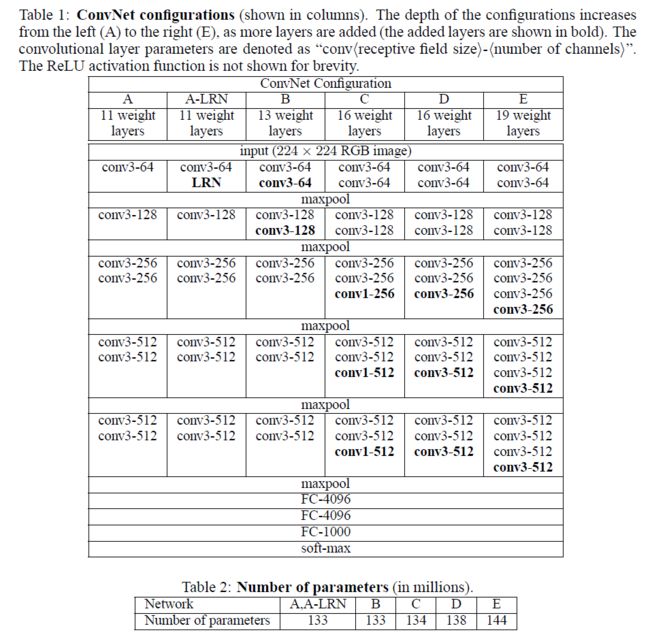
VGG16模型(2+2+3+3+3个卷积层,3个全连接层):

VGG19模型:
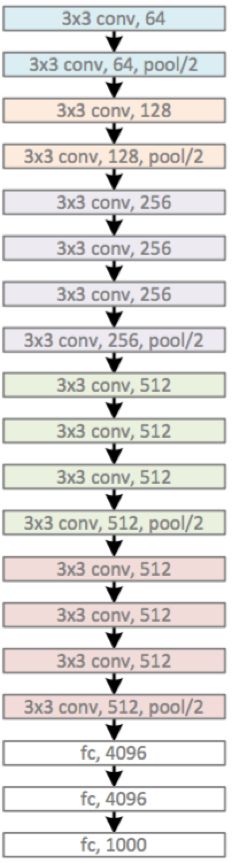
ResNet(2015)
设计了“bottleneck”形式的block(有跨越几层的直连)
用全局平均池化GAP代替全连层FC,解决全连接层参数冗余的问题,但FC的优势在于在迁移学习中可改善微调的效果。
resnet18:

DenseNet(CVPR 2017的最佳论文奖):


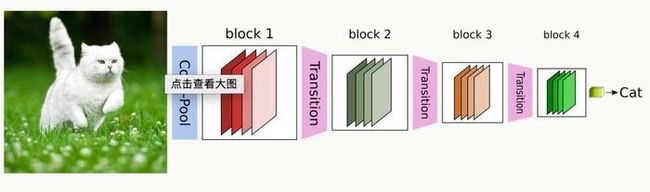
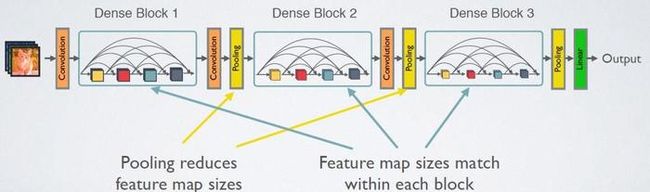
含义:前面所有层与后面层的密集连接(dense connection), 每一层的输入都是前面所有层输出的并集,而该层所学习的特征图也会被直接传给其后面所有层作为输入
优点:缓解梯度消失问题,特征复用,加强特征传播,减少参数量
缺点:内存占用高
缓解梯度消失原因:每一层都直接连接input和loss
参数量少原因:每一层已经能够包含前面所有层的输出,只需要很少的特征图就可以了
基本结构是:dense block(BN-ReLU-Conv(1×1)-BN-ReLU-Conv(3×3))+transition layers(BN−>Conv(1×1)−>averagePooling(2×2))
紧密连接位置:dense connectivity 仅仅是在一个dense block里的,不同dense block 之间是没有dense connectivity的
Transition作用:1)连接不同block 2)降低特征图尺寸
参考网站:https://www.cnblogs.com/skyfsm/p/8451834.html
https://www.imooc.com/article/36508
1*1卷积核
本质上其实就是channels的线性叠加
作用:
(1)升/降特征的维度,指改变通道数(厚度),不改变宽高。举个例子:W*H*6——用5个1*1厚度为6的卷积核卷积——W*H*5
(2)加入非线性,卷积后经过激励层,提高网络表达能力,实现泛化。
卷积后计算feature map尺寸大小

参考网址:
https://blog.csdn.net/oppo62258801/article/details/73525505
https://blog.csdn.net/Teeyohuang/article/details/75214758
https://www.cnblogs.com/zhenggege/p/9000414.html
https://blog.csdn.net/gyh_420/article/details/78569225
https://blog.csdn.net/hhy_csdn/article/details/80030468