漏洞挖掘 | 简单高效的模糊测试Fuzzing
文章目录
- 定义
- 用途
- 技术
- 详细说明
- 流程图
- 1.大量的测试用例
- 2.对测试用例做过滤
- 3.要用正确的方法
- 4.花90%时间阅读文档
- 5.Fuzzing工具
摘要:Fuzzing是一种通过构造输入来发现软件中的漏洞的一个简单高效的模糊测试方法。
前言:打CTF的时候就听说过几次fuzzing方法,大概知道是一种检测漏洞的方法,一直没了解过,今天抽个时间学习了一下。
定义
Fuzzing方法是指通过构造测试输入,对软件进行大量测试来发现软件中的漏洞的一种模糊测试方式。在现实的漏洞挖掘中,fuzzing因其简单高效的优势,成为非常主流的漏洞挖掘方法。
模糊测试 (fuzz testing, fuzzing)是一种软件测试技术。其核心思想是将自动或半自动生成的随机数据输入到一个程序中,并监视程序异常,如崩溃,断言(assertion)失败,以发现可能的程序错误,比如内存泄漏。模糊测试常常用于检测软件或计算机系统的安全漏洞。
——来自Wikipedia
用途
模糊测试通常被用于黑盒测试。其回报率通常比较高。当然,模糊测试只是相当于对系统的行为做了一个随机采样,所以在许多情况下通过了模糊测试只是说明软件可以处理异常以避免崩溃,而不能说明该软件的行为完全正确。这表明模糊测试更多是一种对整体质量的保证,并不能替代全面的测试或者形式化方法。作为一种粗略的可靠性度量方法,模糊测试可以提示程序哪些部件需要特殊的注意。对于这些部件可以进一步使用代码审计,静态分析以及代码重写。
技术
模糊测试工具通常可以被分为两类。变异测试通过改变已有的数据样本去生成测试数据。生成测试则通过对程序输入的建模来生成新的测试数据。
最简单的模糊测试是通过命令行,网络包或者事件向一个程序输入一段随机比特流。这种技术当前依然是有效的发现程序错误的方法。另一个常见且易于实现的技术是通过随机反转一些比特或者整体移动一些数据块来变异已有的输入数据。但是,最有效的模糊测试需要能够理解被测试对象的格式或者协议。这可以通过阅读设计规格来实现。基于设计规格的模糊工具包含完整的规格,并通过基于模型的测试生成方法去遍历规格,并在数据内容,结构,消息,序列中引入一些异常。这种“聪明的”模糊测试也被称作健壮性测试,句法测试,语法测试以及错误注入。这种协议感知的特性也可以启发式的从例子中生成。相关的工具有Sequitur。
模糊测试也可以与其他技术结合。白盒模糊测试结合了符号执行技术与约束求解技术。演化模糊测试则利用了一个启发的反馈来有效的实现自动的探索性测试。
详细说明
流程图
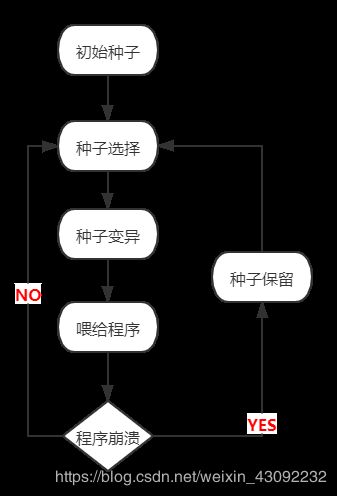
1.大量的测试用例
进行模糊测试的首要条件就是需要大量的测试用例(即种子输入),例如Charlie Miller对Reader 9.2.0进行的fuzzing测试,他首先从网上的1515个文件变异得到3036000个测试用例进行测试,最后得到crash。在对Preview这个软件做测试时,用了大概2790000个测试用例进行测试才得以拿到crash。这些数字跟我们的直观感受就是我们需要获得大量的测试用例,才能保证模糊测试过程中拿到程序的crash。
2.对测试用例做过滤
实际情况中,并不是说拿很多的测试用例就可以去测试软件就可以拿到漏洞,即fuzzing测试并不是简单的关于生成测试用例去做测试的故事,而是一个关于怎么对测试用例做过滤的故事。并不是说得到几十万量级的测试用例之后,就可以拿到漏洞了,而实际上,这几十万个测试用例都是精品,用这些精品进行测试才得以发现的漏洞,那么怎么把这些精品过滤出来,这才是关键,也是我们在进行fuzzing测试过程中需要做的第二件重要的准备工作。
比如Charlie Miller在测试PDF的时候,他把网上所有能够下载到的80000个PDF文档都下载下来,然后找到一个最小的子集,这个子集的代码覆盖率和全集的代码覆盖率是一样的,这个最小的子集也就是软件测试中的最初始的集合—1515个文件,在这个最初始的集合上再去做fuzz,这就是一个筛选的过程,我们可以用代码覆盖率作为衡量标准,当然也可以选择其他合适的标准来完成这一筛选过程。
3.要用正确的方法
Laurent Gaffié说过,他在研究SMB协议的远程调用接口的时候,最先做了很多工作,结果都失败了,直到他将策略改变成了用单字节的网络数据包,才有了大量的产量。所以fuzzing是要讲方法的,要想清楚可能出问题的是什么地方,你要用什么样的方法去把这个东西找出来,关于方法,每年都有很多的论文,大家可以去看。
Charlie Miller也说,很多关于fuzzing的报告都是讲述如何成功,但是现实中的fuzzing大部分都是讲关于失败的。可见在现实中做fuzz测试的时候,你会遇到很多挫折。所以找到正确的方法非常重要!CharlieMiller和Laurent Gaffié给出的代码虽然看起来很不起眼,但一旦找到了正确的方法,得到的结果往往很令人惊喜。
4.花90%时间阅读文档
还有一个问题,就是做fuzzing的人,并不是简单的写几行代码,对着软件一通测试就会出来结果。在做fuzzing之前,会有很多的时间是花在阅读文档上的。
对于复杂的程序,我们要去分析这个程序的功能是什么,它可能出问题的地方在什么位置,会有大量的几乎90%的时间是花在这上面的,这是Charlie Miller和Laurent Gaffié的一个评估。
5.Fuzzing工具
AFL,它是目前最受欢迎的一个工具,是一个导向型的fuzzing工具。 Fuzzing通常由盲fuzzing(blind fuzzing)和导向性fuzzing(guided fuzzing)两种。blind fuzzing生成测试数据的时候不考虑数据的质量,通过大量测试数据来概率性地触发漏洞。Guided fuzzing则关注测试数据的质量,期望生成更有效的测试数据来触发漏洞的概率。比如,通过测试覆盖率来衡量测试输入的质量,希望生成有更高测试覆盖率的数据,从而提升触发漏洞的概率。
AFL这个工具出来的一个起因就是AFL的开发者认为盲fuzzing的效率是比较低的;第二个原因就是Charlie Miller和Laurent Gaffié所做的样本筛选的方法是有效果的;还有第三个原因就是符号执行,符号执行在理论是非常不错的,但在实际中经常受到可行性、性能等方面的限制。于是在这样一个背景下,AFL出现了。
AFL有两个关键词:指令插桩和边覆盖。首先AFL是基于插桩的,能够辅助程序分析;其次AFL是基于边覆盖的,是对Charlie Miller等人基于块覆盖用样本筛选的一个改进和提升。
参考:
1.模糊测试-维基百科
2.简单高效的模糊测试Fuzzing