python常见反爬虫类型(验证码)
目录
- 注:笔记大部分来源书本,仅供学习交流:【Python3反爬虫原理与绕过实战—韦世东】
- 6、验证码
- (1)字符验证码
- (2)计算型验证码
- (3)滑动验证码
- (4)滑动拼图验证码
- (5)文字点选验证码
- (6)鼠标轨迹的检测和原理
- (7)验证码种类
注:笔记大部分来源书本,仅供学习交流:【Python3反爬虫原理与绕过实战—韦世东】
- 将爬虫的爬取过程分为网络请求,文本获取和数据提取3个部分。
- 信息校验型反爬虫主要出现在网络请求阶段,这个阶段的反爬虫理念以预防为主要目的,尽可能拒绝反爬虫程序的请求。
- 动态渲染、文本混淆则出现在文本获取及数据提取阶段,这个阶段的反爬虫理念以保护数据为主要目的,尽可能避免爬虫获得重要数据
- 特征识别反爬虫通过客户端的特征、属性或用户行为特点来区分正常用户和爬虫程序的手段
- APP网络传输和数据收发相对隐蔽,用户无法直接查看客户端发出的请求信息和服务端返回的响应内容,也无法直接查看App的代码,构成了反爬虫
- 验证码是指能够区分用户是计算机或者是人类的全自动程序,验证码可以有效防止恶意注册、刷票、论坛“灌水”等有损网站利益的行为。验证码的原理很简单:人类有主观意识,能够根据要求执行操作,而计算机却不能。
- 1、python常见反爬虫类型(信息校验型、动态渲染、文本混淆、特征识别反爬虫等)
- 2、python常见反爬虫类型(App反爬虫等)
6、验证码
- 常见的有字符验证码、滑动验证码、拼图验证码、和文字点选验证码等
(1)字符验证码
- 字符验证码是指用数字、字母、汉字和标点符号等字符作为元素的图片验证码;
- 难点:部分验证码带有彩色背景斜线、噪点、字符扭曲、角度旋转和文字重叠等方法。图片中的字符颜色与背景颜色并没有强烈的反差,这些因素都会影响识别效果。要想提高识别成功率,就必须对图片进行处理
- 方法:例如降低斜线和噪点对文字的干扰,增强背景色与字符颜色的反差,也就是对图片进行灰度处理(去掉彩色)和二值化处理(降低干扰、增强颜色反差)
- 二值化处理:其实是根据阈值调整原图的像素值,将大于阈值的像素点颜色改为白色,小于阈值的像素点改为黑色,这样就能够达到增强颜反差的目的
- 字符验证码主要由数字、大写字母、彩色斜线、彩色噪点和彩色背景组成,图像分为3层,最底层为背景色,字符(数字和大写字母)层在背景色之上,干扰(斜线和噪点)层则在最上面,
![]()
![]()
![]()
from PIL import Image
def handler(grays, threshold=160):
"""
对灰度图片进行二值化处理,默认阈值为160,可根据实际情况调整
"""
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
anti = grays.point(table, "1")
return anti
# 灰度处理
images = "code.png"
gray = Image.open(images).convert("L")
gray.show()
# 二值化处理
image = handler(gray)
image.show()
深度学习基本了解
- 深度学习:它是机器学习研究中的一个新领域,动机在于建立能够模拟人脑进行分析学习的神经网络,希望模仿人脑的机制来解释数据,例如图像、声音和文本;
- 深度学习术语:比如教计算机认识图中的文字的过程叫做“训练”,形成的记忆叫做“模型”,而识别图片中的内容叫做“预测”;训练样本的质量直接影响预测准确率;
- 卷积神经网络:包含卷积计算且具有深度结构的前馈神经网络;卷积神经网络中常见的概念有输入层、图片数字化处理、卷积层、卷积运算、池化层、全连接层和输出层等。
- 输入层
- 用于输入整个神经网络的数据。举个例子:在用于处理图片验证码的卷积神经网络中,输入的数据是一张验证码图片。计算机擅长处理数字,在将图片传入卷积神经网络前需要将图片进行数字化处理;
- 图片数字化处理
- 先将图片转换为像素矩阵,然后将像素矩阵转换为张量的过程,图片的像素值通常在0~255,图片数字化实际上是将[0,255]的PIL.Image对象转换成取值范围是[0,1.0000]的Tesnsor对象;
- 卷积层
- 卷积层的作用是提取图片对应的像素矩阵的特征,特征提取其实就是卷积运算的过程
- 卷积运算
- 卷积运算是卷积神经网络最基本的组成部分之一
- 池化层
- 池化层能够有效缩减数据量,提高计算速度和所提取特征的健壮性。池化层缩减数据量的方法分为最大池化(将卷积层传递的矩阵拆分为n✖n单个区域,然后保留该区域像素值中的最大值)和平均池化。
- 全连接层
- 全连接层通常出现在卷积神经网络的最后几层。它将当前向量进行维度变换,对卷积层和池化层提取到的特征进行加权计算,最后经过降维转到Label的维度。它的本质是由一个特征空间线性变换到另一个特征空间。 卷积层:获取局部特征; 全连接将卷积层获取的局部特征组装成完整特征图的过程。
- 输出层
- 输出层通常使用归一化函数softmax输出分类标签,得到对应的分类结果
(2)计算型验证码
- 计算型验证码在字符验证码的基础上增加了数学运算,它也是将人类视觉和计算机视觉的差异作为区分用户的依据;

- 对于这种没有斜线、噪点等干扰元素的验证码,我们可以用PyTesseract库进行识别,根据识别结果选择运算方法即可,
import pytesseract
import re
def operator_func(a:int, b:int, oper:str) -> int:
# 接收两个值和运算符,返回数字运算结果
if oper == "+":
return a+b
if oper == "-":
return a-b
if oper == "*":
return a*b
strings = pytesseract.image_to_string("paste.png")
result = re.findall(r"\d+", strings)
operator = re.findall(r'[\+|\-|\*]', result)
res = operator_func(int(result[0]), int(result[1]), operator[0])
print(res)
(3)滑动验证码
- 计算机难以准确地完成鼠标按下、拖拽、释放等行为,所以开发出了滑动验证码;

from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.porters.vip/captcha/sliders.html")
hover = browser.find_element_by_css_selector(".hover") # 定位滑块
action = webdriver.ActionChains(browser)
action.click_and_hold(hover).perform() # 点击并保持不松开
action.move_by_offset(340, 0) # 设置滑动距离,横向距离为340px(390-50),纵向距离为0px
action.release().perform() # 松开鼠标
(4)滑动拼图验证码
- 滑动拼图验证码在滑动验证码的基础上增加了随机滑动距离,用户需要使用滑动的方式完成拼图,才能通过校验(突破口,缺口位置)。

- 简单的,缺口位置可以通过CSS样式来实现计算
from selenium import webdriver
import re
from parsel import Selector
browser = webdriver.Chrome()
browser.get("http://www.porters.vip/captcha/jigsaw.html")
jigsaw = browser.find_element_by_css_selector("#jigsawCircle") # 定位滑块
action = webdriver.ActionChains(browser)
action.click_and_hold(jigsaw).perform() # 点击并保持不松开
html = browser.page_source # 返回当前页面的html代码
sel = Selector(html)
# 获取圆角矩形和缺口的css样式
mbk_style = sel.css("#missblock::attr('style')").get()
tbk_style = sel.css("#targetblock::attr('style')").get()
# 调用匿名函数获取CSS样式中的left属性值
mbk_left = re.search(r"left: (\d+\.?\d+)px", mbk_style).group(1)
tbk_left = re.search(r"left: (\d+\.?\d+)px", tbk_style).group(1)
# 计算当前拼图验证码滑块所需的移动距离
distance = float(tbk_left) - float(mbk_left)
action.move_by_offset(distance, 0) # 设置滑动距离,横向距离为340px(390-50),纵向距离为0px
action.release().perform() # 松开鼠标
- 复杂的,缺口融入到背景图中,不再使用CSS样式显示,将缺口与背景图绘制在同一个Canvas画布上,示例;

- 方法:比较有缺口的图片和无缺口的图片像素,找出缺口位置;如使用ImageChops模块中的difference()方法==对比图片像素的不同,并获取图片差异位置的坐标
from selenium import webdriver
from PIL import ImageChops
from PIL import Image
browser = webdriver.Chrome()
browser.get("http://www.porters.vip/captcha/jigsawCanvas.html")
jigsaw = browser.find_element_by_css_selector("#jigsawCircle") # 定位滑块
canvas = browser.find_element_by_css_selector("#jigsawCanvas")
canvas.screenshot("before.png")
action = webdriver.ActionChains(browser)
action.click_and_hold(jigsaw).perform() # 点击并保持不松开
# 执行javascript隐藏圆角矩形的HTML代码
scripts = """
var missblock = document.getElementById("missblock");
missblock.style['visibility'] = 'hidden';
"""
browser.execute_script(scripts)
# 再次截图
canvas.screenshot("after.png")
image_a = Image.open("after.png")
image_b = Image.open("before.png")
# 使用ImageChops模块中的difference()方法对比图片像素的不同,并获取图片差异位置的坐标
diff = ImageChops.difference(image_b, image_a)
# 获取图片差异位置的坐标
diff_position = diff.getbbox() # (左、上、右、下)
print(diff_position)
position_x = diff_position[0]
action.move_by_offset(int(position_x)-10, 0)
action.release().perform() # 松开鼠标
(5)文字点选验证码
- 点选验证码,用户需要根据页面给出的验证要求依次点击图片中的文字通过验证,阅读验证要求,按序点击图片文字

- 目标检测:通过文字点选验证码校验的关键是找到图片中文字的具体位置。目标检测是深度学习领域的一个研究方向,常见的应用有人脸识别、自动驾驶等。目标检测主要用于确定图片中物体的位置并判断该物体类型,也就是对图片中的物体进行定位和分类
- 深度学习领域中的目标检测算法有很多,如R-CNN、SSD、YOLO和Faster等
- 方法:可以使用Darknet框架和YOLO算法实现文字点选验证码图片中的文字定位
- 突破点:目标定位和识别,通过成熟的深度学习目标检测技术即可快速而准确地定位到图片中的目标
(6)鼠标轨迹的检测和原理
- 鼠标轨迹指的是鼠标移动的坐标集合,它代表鼠标移动的位置和距离;鼠标从页面的某个位置移动到按钮的过程中,无论从哪个方向进入,都会产生轨迹;
- 虽然在移动鼠标时已经尽量避免手臂晃动,但根据黄幕上的移动轨迹和白慕中显示的坐标记录来看,移动过程中还是有一定的晃动现象

- 使用selenium套件点击按钮,只会产生1个坐标记录,并不像我们手动点击时会产生很多的坐标记录;
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.porters.vip/captcha/mousemove.html")
button = browser.find_element_by_class_name("button1")
button.click()
- 开发者可以根据人类移动鼠标时手臂会晃动这个特点区分正常用户和爬虫程序,手臂晃动的特点可以应用在滑动验证码中,开发者使用javascript代码记录移动滑块时的鼠标坐标信息,然后根据晃动的偏差(即两个相邻y坐标的差值)实现对爬虫程序的检测
- action.move_by_offset(340, 5),5px的偏移只在滑动操作的最后一刻才发生,要想接近手臂晃动的效果,需要不停的调整这个y参数
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.porters.vip/captcha/mousemove.html")
button = browser.find_element_by_class_name("button1")
action = webdriver.ActionChains(browser)
action.click_and_hold(button).perform() # 点击并保持不松开
action.move_by_offset(340, 5) # 设置滑动距离,横向距离和纵向距离
action.release().perform() # 松开鼠标
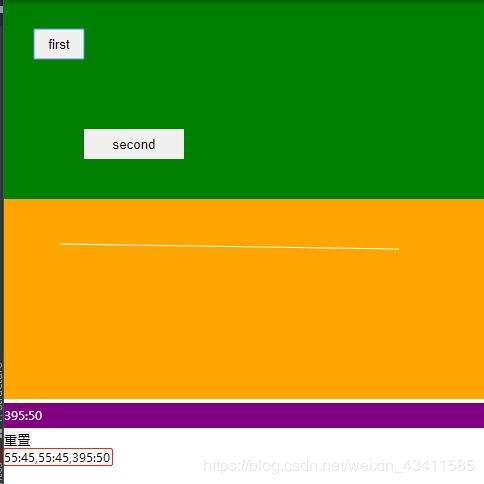
- 相同的距离,人类移动鼠标时,页面记录的坐标信息叫多,而selenium套件滑动时,页面记录的坐标信息则比较少,这是因为鼠标每移动1像素,页面都会记录当时的坐标,而selenium套件移动时记录的坐标为move_by_offset()的数量加2,其中2时鼠标按下和释放时的记录:鼠标移动50px,人类移动会产生52个坐标记录而selenium套件移动不一定能够产生52个坐标记录
- 总结:
- 开发者可以记录鼠标移动时的坐标信息,坐标信息集合就是鼠标轨迹,
- 人类移动鼠标时,手臂晃动导致y坐标小幅度变化,
- selenium套件可以模拟出人类移动鼠标时的手臂晃动效果,
- selenium套件移动鼠标时得到的坐标记录数量有可能与人类移动鼠标时得到的坐标数量不同
(7)验证码种类
- 滑动验证码:腾讯、极验、网易盾、顶象
- 图标点选验证码:螺丝帽、网易盾、极验、天验
- 空间推理验证码:腾讯、极验
- 其它:短信验证码、邮箱验证码、语语音验证码