LeetCode 第189场周赛 题解
第三题卡了一点时间 最后暴力过的 第四题原题做过 90名还行
文章目录
- a.在既定时间做作业的学生人数
- a.题目
- a.分析
- a.参考代码
- b.
- b.题目
- b.分析
- b.参考代码
- c.
- c.题目
- c.分析
- c.参考代码
- d.
- d.题目
- d.分析
- d.参考代码
a.在既定时间做作业的学生人数
a.题目
给你两个整数数组 startTime(开始时间)和 endTime(结束时间),并指定一个整数 queryTime 作为查询时间。
已知,第 i 名学生在 startTime[i] 时开始写作业并于 endTime[i] 时完成作业。
请返回在查询时间 queryTime 时正在做作业的学生人数。形式上,返回能够使 queryTime 处于区间 [startTime[i], endTime[i]](含)的学生人数。
示例 1
输入:startTime = [1,2,3], endTime = [3,2,7], queryTime = 4
输出:1
解释:一共有 3 名学生。
第一名学生在时间 1 开始写作业,并于时间 3 完成作业,在时间 4 没有处于做作业的状态。
第二名学生在时间 2 开始写作业,并于时间 2 完成作业,在时间 4 没有处于做作业的状态。
第二名学生在时间 3 开始写作业,预计于时间 7 完成作业,这是是唯一一名在时间 4 时正在做作业的学生。
示例 2
输入:startTime = [4], endTime = [4], queryTime = 4
输出:1
解释:在查询时间只有一名学生在做作业。
示例 3
输入:startTime = [4], endTime = [4], queryTime = 5
输出:0
示例 4
输入:startTime = [1,1,1,1], endTime = [1,3,2,4], queryTime = 7
输出:0
示例 5
输入:startTime = [9,8,7,6,5,4,3,2,1], endTime = [10,10,10,10,10,10,10,10,10], queryTime = 5
输出:5
提示
- startTime.length == endTime.length
- 1 <= startTime.length <= 100
- 1 <= startTime[i] <= endTime[i] <= 1000
- 1 <= queryTime <= 1000
a.分析
非常直观 对于每个同学都去看一下queryTime是否在他们的学习时间内就行了
要注意的地方是边界结束和开始也包含在内
遇到一个符合的计数加就行了
总的时间复杂度只有遍历的时间复杂度O(n)
a.参考代码
class Solution {
public:
int busyStudent(vector<int>& startTime, vector<int>& endTime, int queryTime) {
int ans=0;
for(int i=0;i<startTime.size();i++)
if(queryTime>=startTime[i]&&queryTime<=endTime[i])ans++; //符合要求的计数增加
return ans;
}
};
b.
b.题目
「句子」是一个用空格分隔单词的字符串。给你一个满足下述格式的句子 text :
- 句子的首字母大写
text中的每个单词都用单个空格分隔。
请你重新排列 text 中的单词,使所有单词按其长度的升序排列。如果两个单词的长度相同,则保留其在原句子中的相对顺序。
请同样按上述格式返回新的句子。
示例 1
输入:text = “Leetcode is cool”
输出:“Is cool leetcode”
解释:句子中共有 3 个单词,长度为 8 的 “Leetcode” ,长度为 2 的 “is” 以及长度为 4 的 “cool” 。
输出需要按单词的长度升序排列,新句子中的第一个单词首字母需要大写。
示例 2
输入:text = “Keep calm and code on”
输出:“On and keep calm code”
解释:输出的排序情况如下:
“On” 2 个字母。
“and” 3 个字母。
“keep” 4 个字母,因为存在长度相同的其他单词,所以它们之间需要保留在原句子中的相对顺序。
“calm” 4 个字母。
“code” 4 个字母。
示例 3
输入:text = “To be or not to be”
输出:“To be or to be not”
提示
- text 以大写字母开头,然后包含若干小写字母以及单词间的单个空格。
- 1 <= text.length <= 10^5
b.分析
从题目可以得知这是需要对单词重排的
那么首先你就得把单词拆分存到一个地方 而这道题只要用数组存就好了
单词拆分就直接碰到空格push一个单词就好了 记得最后无空格 要手动push最后一个
那么既然是重排序 那么当然就是对数组里的单词排序就好了 然后根据题目要求自己写一个比较函数
- 如果两个单词长度不一样 长度短的在前
- 如果两个长度一样 那么原来顺序谁在前面谁就在前 这里原来顺序可以在单词拆分的时候同时做了
单词排序好了之后直接按顺序塞进一个字符串就好了
然后这道题还有个坑点
- 排序前的首单词首字母大写了 我们把它变成小写 在重排序原来的大写无意义
- 塞进字符串后记得把答案首字母大写
总的复杂度为排序的O(nlogn)加上其他操作都是O(n)所以最后还是O(nlogn)
b.参考代码
class Solution {
public:
string arrangeWords(string text) {
if(text.size())text[0]=tolower(text[0]); //原来的首字母变小写
vector<pair<string,int>> words;
string tmp;
for(int i=0;i<text.size();i++) //拆分单词
if(text[i]!=' ')tmp.push_back(text[i]);
else {
words.push_back({tmp,i}); //记得把顺序也加进去
tmp="";
}
words.push_back({tmp,text.size()+2});
sort(words.begin(),words.end(),[](pair<string,int> &a,pair<string,int> &b)->bool{ //按照分析说的排序并写上比较函数
if(a.first.size()==b.first.size())return a.second<b.second;
return a.first.size()<b.first.size();
});
string ans;
for(int i=0;i<words.size();i++) //单词合并
{
ans+=words[i].first;
ans+=" ";
}
ans.pop_back(); //方便就多写了 其实可以判断下是否是最后一个的
if(ans.size())ans[0]=toupper(ans[0]); //首字母大写
return ans;
}
};
c.
c.题目
给你一个数组 favoriteCompanies ,其中 favoriteCompanies[i] 是第 i 名用户收藏的公司清单**(下标从 0 开始)**。
请找出不是其他任何人收藏的公司清单的子集的收藏清单,并返回该清单下标。下标需要按升序排列。
示例 1
输入:favoriteCompanies = [[“leetcode”,“google”,“facebook”],[“google”,“microsoft”],[“google”,“facebook”],[“google”],[“amazon”]]
输出:[0,1,4]
解释:
favoriteCompanies[2]=[“google”,“facebook”] 是 favoriteCompanies[0]=[“leetcode”,“google”,“facebook”] 的子集。
favoriteCompanies[3]=[“google”] 是 favoriteCompanies[0]=[“leetcode”,“google”,“facebook”] 和 favoriteCompanies[1]=[“google”,“microsoft”] 的子集。
其余的收藏清单均不是其他任何人收藏的公司清单的子集,因此,答案为 [0,1,4] 。
示例 2
输入:favoriteCompanies = [[“leetcode”,“google”,“facebook”],[“leetcode”,“amazon”],[“facebook”,“google”]]
输出:[0,1]
解释:favoriteCompanies[2]=[“facebook”,“google”] 是 favoriteCompanies[0]=[“leetcode”,“google”,“facebook”] 的子集,因此,答案为 [0,1] 。
示例 3
输入:favoriteCompanies = [[“leetcode”],[“google”],[“facebook”],[“amazon”]]
输出:[0,1,2,3]
提示
- 1 <=
favoriteCompanies.length<= 100
- 1 <=
favoriteCompanies[i].length<= 500 - 1 <=
favoriteCompanies[i][j].length<= 20 favoriteCompanies[i]中的所有字符串 各不相同 。- 用户收藏的公司清单也 各不相同 ,也就是说,即便我们按字母顺序排序每个清单,
favoriteCompanies[i] != favoriteCompanies[j]仍然成立。 - 所有字符串仅包含小写英文字母。
c.分析
其实这题我并没有什么优化思路 所以还是用的暴力
设有n个人 每个人有m个公司 每个公司名字长k
看了下范围nmk=100*500*20=1e6 这个复杂度还是很危险的 所以纯暴力我估摸着不可行 (后来发现这题数据能过
纯暴力的做法如下:
- 对n个人每个人的m间公司进行字典序排序 O((nmk)log(nmk))
- 对n个人进行排序 m越小排越前面 这一步的复杂度是O(nlogn)
- 排序后的第i个人的收藏清单只可能是后面的人的收藏清单的子集 因为
- 假如收藏清单长度不同 那么只能是后面长的包含前面短的
- 假如长度一样 那么前面的肯定判断过当前的关系
- 然后需要用O(n^2)的时间来枚举两两之间是否为子集关系 (虽然预处理过了 但是复杂度还是平方的
- 判断是否为子集关系可以用双指针去看前面的是否在后面的都有 因为公司已经用字典序排好了 所以后面的指针只需要不断后移就行 O(mk)
我们来算一下复杂度
预处理两个sort不是嵌套关系 所以是O((nmk)log(nmk))约为2e7 还行吧
再看后面的遍历判断是O(mkn^2)约为1e8 这就好像不太行了啊
所以总的时间复杂度是O(mkn^2)但是具体遍历判断子集的时候是向后判断到是子集就立刻停止了的
所以我怀疑这次比赛数据没有出极限数据就是每个都不是子集
优化了点的做法:
其实这道题重要的就是在判断是否是子集
而又因为题目给的收藏清单集合是无序的 排序其实浪费了点时间
所以我想着我需要预处理出来每个人都有一个集合且集合是可以直接比较的
于是这里我就想到了用位压缩表示集合 首先是位运算相当快 其次如果想要表示是否是子集 那么只需要判断下A|B是否和A或B其中一个相等就行了
预处理的话就直接每个公司给他hash一个编号就好了 这里采用递增idx就行了
具体步骤如下:
- 给n人每人分配一个大小为nm的bitset (因为最多共有nm的不同的公司)
- 遍历每个人的公司 把他收藏的公司的hashcode作为标志位放进bitset中 获取hashcode可以约为O(1)而因为键是string所以是O(k)所以总的预处理出来每个人的bitset是O(nmk)
- 设置一个标志集合ok表示谁还在里面 (可以比较的)
- 对于每个人两两比较手中的bitset 如果某个是某个的子集的话就把子集那个从ok剔除 以后就不比较它了 此处两两比较为O(n^2)bitset比较是O(nm)但是实际因为位运算要快得多 所以总的是O(mn^3)
所以总的复杂度为O(nmk) 因为bitset比较O(nm)实际上速度应该只要O(nm/64)且64位的还是用位运算会更快 (bitset就是骚操作
c.参考代码
class Solution {
public:
int idx=0;
bool ok[105]; //false表示还在集合里 true表示剔除了
vector<int> peopleIndexes(vector<vector<string>>& FC) {
vector<bitset<50010>> arr(FC.size());
unordered_map<string,int> mp;
for(int i=0;i<FC.size();i++) //预处理出每个人的bitset
for(int j=0;j<FC[i].size();j++)
if(mp.count(FC[i][j]))arr[i][mp[FC[i][j]]]=1;
else {
mp[FC[i][j]]=idx;
arr[i][idx++]=1;
}
vector<int> ans;
for(int i=0;i<arr.size();i++) //bitset暴力比较
for(int j=0;j<arr.size();j++)
if(ok[i]||ok[j])continue;
else if(i==j)continue;
else{
if((arr[i]|arr[j])==arr[i]){
ok[j]=true;
}
else if((arr[i]|arr[j])==arr[j]){
ok[i]=true;
}
}
for(int i=0;i<arr.size();i++)if(!ok[i])ans.push_back(i); //安排答案 已经是顺序的了
return ans;
}
};
d.
d.题目
墙壁上挂着一个圆形的飞镖靶。现在请你蒙着眼睛向靶上投掷飞镖。
投掷到墙上的飞镖用二维平面上的点坐标数组表示。飞镖靶的半径为 r 。
请返回能够落在 任意 半径为 r 的圆形靶内或靶上的最大飞镖数。
示例 1
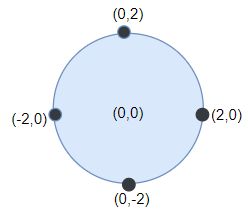
输入:points = [[-2,0],[2,0],[0,2],[0,-2]], r = 2
输出:4
解释:如果圆形的飞镖靶的圆心为 (0,0) ,半径为 2 ,所有的飞镖都落在靶上,此时落在靶上的飞镖数最大,值为 4 。
示例 2
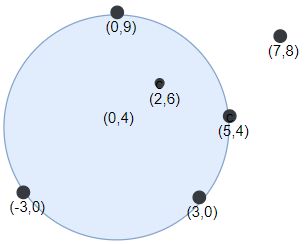
输入:points = [[-3,0],[3,0],[2,6],[5,4],[0,9],[7,8]], r = 5
输出:5
解释:如果圆形的飞镖靶的圆心为 (0,4) ,半径为 5 ,则除了 (7,8) 之外的飞镖都落在靶上,此时落在靶上的飞镖数最大,值为 5 。
示例 3
输入:points = [[-2,0],[2,0],[0,2],[0,-2]], r = 1
输出:1
示例 4
输入:points = [[1,2],[3,5],[1,-1],[2,3],[4,1],[1,3]], r = 2
输出:4
提示
- 1 <= points.length <= 100
- points[i].length == 2
- -10^4 <= points[i][0], points[i][1] <= 10^4
- 1 <= r <= 5000
d.分析
纯几何题
想要尽量小的圆包含尽量多的点 那么这些点最好是能恰好落在圆边缘上
最优解必定有一个是可以最少包含两个点在边缘上的
因为你想象一下 一个最优解的圆必定可以通过移动这个圆 直到某两个点碰到了边缘而限制了它的移动
那么我们可以暴力枚举哪两个点在边缘以达到枚举这些圆
- 枚举两个点a,b出来
- 根据初中知识 已知圆半径r 且知道两个点在圆弧上 那么我们可以得到两个圆 一个是根据劣弧生成的 一个是根据优弧生成的
- 先得出两点中点的边长 与斜边半径做勾股定律即可求出圆心位置
- 然后对于每个圆我们遍历一下有多少个点就行了
- 对于每个圆能包含的点更新下最大值答案
总的时间复杂度是O(n^3)
其实对于优劣弧没必要把两个圆都列出来 因为总能找到两个点是在最优圆左半边 那么我们只需要不断同一个方向的圆即可 比如总是生成正方向的圆
d.参考代码
class Solution {
public:
const double eps=1e-8; //合理误差范围
int R;
int numPoints(vector<vector<int>>& points, int r) {
for(int i=0;i<points.size();i++) //塞进全局点集里 方便用模板
{
p[i].x=points[i][0];
p[i].y=points[i][1];
}
R=r;
int ans=1;
int n=points.size();
for(int i=0;i<n;i++) //对于每对点 枚举圆
for(int j=i+1;j<n;j++)
{
if(dist(p[i],p[j]) > 2.0*r) continue; //两点距离大于直径
Point center = GetCircleCenter(p[i],p[j]);
int cnt = 0;
for(int k=0;k<n;k++) //枚举出圆之后判断有多少个点在圆内
if(dist(center,p[k]) < 1.0*r+eps) cnt++;
ans = max(ans,cnt);
}
return ans;
}
struct Point
{
double x,y;
Point(){}
Point(double tx,double ty){x=tx;y=ty;}
}p[105];
inline double dist(Point p1,Point p2) //两点距离
{
return sqrt(pow(p1.x-p2.x,2)+pow(p1.y-p2.y,2));
}
Point GetCircleCenter(Point p1,Point p2) //计算圆心模板
{
Point mid = Point((p1.x+p2.x)/2,(p1.y+p2.y)/2);
double angle = atan2(p1.x-p2.x,p2.y-p1.y);
double d = sqrt(R*R-pow(dist(p1,mid),2));
return Point(mid.x+d*cos(angle),mid.y+d*sin(angle));
}
};