Hadoop学习笔记(五)—— 搭建Hadoop HA集群
文章目录
- 三台虚拟机的集群节点规划
- 搭建环境准备
- 搭建Hadoop HA集群
- 配置core-site.xml文件
- 配置hdfs-site.xml文件
- 配置mapred-site.xml文件
- 配置yarn-site.xml文件
- 配置slaves文件
- 配置hadoop-env.sh文件
- 分发目录
- 初次启动Hadoop HA集群步骤
- 效果验证
- 问题
三台虚拟机的集群节点规划
| 服务器 | Name Node | Data Node | Resource Manager | Node Manager | Journal Node | Zookeeper | ZKFC |
|---|---|---|---|---|---|---|---|
| node-01 | + | + | + | + | + | + | + |
| node-02 | + | + | + | + | + | + | |
| node-03 | + | + | + | + |
搭建环境准备
之前我们只是搭建了hadoop的高性能集群,该集群并不是这里的高可用集群,在HDFS高可用的架构中,部署了两个NameNode节点并且加入了ZKFC(故障恢复控制器)监控NameNode的健康状态,并通过心跳的方式与Zookeeper保持通信,解决了单点故障的问题。
这里的搭建环境只需要一个普通的Hadoop集群,安装好JDK和Zookeeper即可。
注意:这里只需要将Hadoop的安装包上传至虚拟机,并不需要安装。
搭建Hadoop HA集群
配置core-site.xml文件
在该文件最末行,删去configuration,并添加如下代码
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://ns1value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/export/servers/hadoop-2.7.4/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>node-01:2181,node-02:2181,node-03:2181value>
property>
configuration>
配置hdfs-site.xml文件
在该文件最末行,删去configuration,并添加如下代码
<configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/export/data/hadoop/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/export/data/hadoop/datavalue>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>ns1value>
property>
<property>
<name>dfs.ha.namenodes.ns1name>
<value>nn1,nn2value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1name>
<value>node-01:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn1name>
<value>node-01:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2name>
<value>node-02:9000value>
property>
<property>
<name>dfs.namenode.http-address.ns1.nn2name>
<value>node-02:50070value>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>
qjournal://node-01:8485;node-02:8485;node-03:8485/ns1
value>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/export/data/hadoop/journaldatavalue>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.ns1name>
<value>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
value>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>
sshfence
shell(/bin/true)
value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/root/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>30000value>
property>
configuration>
配置mapred-site.xml文件
这个文件在"…/hadoop-2.7.4/etc/hadoop/"目录下并不存在,只存在"mapred-site.xml.template"文件,这个是MapReduce的配置模板文件,这里只需要使用cp mapred-site.xml.template mapred-site.xml拷贝一份并重命名为mapred-site.xml即可。
之后使用vi编辑器打开mapred-site.xml,在该文件最末行,删去configuration,并添加如下代码
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>
配置yarn-site.xml文件
在该文件最末行,删去configuration,并添加如下代码
<configuration>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>2048value>
property>
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>2048value>
property>
<property>
<name>yarn.nodemanager.resource.cpu-vcoresname>
<value>1value>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yrcvalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>node-01value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>node-02value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>node-01:2181,node-02:2181,node-03:2181value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
配置slaves文件
删去该文件的全部内容,在文件中加入三台主机的名称,达到配置集群主机名称的目的。
例如:

配置完成后保存退出即可。
配置hadoop-env.sh文件
在该文件中找到"export JAVA_HOME=",找到后删去其后的内容,并添加自己的jdk的安装路径。
例如:

配置完成后保存退出即可。
分发目录
将配置好的Hadoop HA集群文件分发给其他主机,命令如下
$ scp -r hadoop-2.7.4/ node-02:/export/servers/
$ scp -r hadoop-2.7.4/ node-03:/export/servers/
分发完成后,配置profile文件,添加hadoop的环境变量,具体如下
export HADOOP_HOME=/export/servers/hadoop-2.7.4
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
配置完成后,使用如下命令将profile文件分发到其他主机
$ scp /etc/profile node-02:/etc/profile
$ scp /etc/profile node-03:/etc/profile
分发完成后,使用source命令使文件生效即可。
初次启动Hadoop HA集群步骤
第一步:在三台主机上输入zkServer.sh start启动zookeeper服务。
- 注意:部分zookeeper安装包生成的启动脚本不同,有的需要进入zookeeper安装路径下的bin目录中,使用命令
./zkServer.sh start才能启动,具体的启动方式需根据个人配置的实际情况而定。
第二步:在三台主机上输入hadoop-daemon.sh start journalnode启动JournalNode。
第三步:在node-01节点格式化NameNode,并将格式化后的目录分发给node-02中,具体命令如下。
$ hadoop namenode -format
$ scp -r /export/data/hadoop node-02:/export/data/
第四步:在node-01节点输入命令hdfs zkfc -formatZK格式化ZKFC。
第五步:在node-01节点输入命令start-dfs.sh启动HDFS。
第六步:在node-01节点输入命令start-yarn.sh启动YARN。
效果验证
输入jps命令查看进程
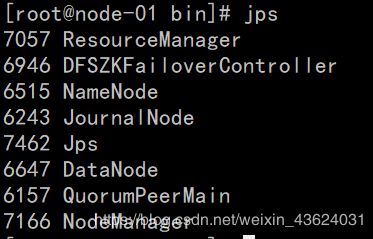
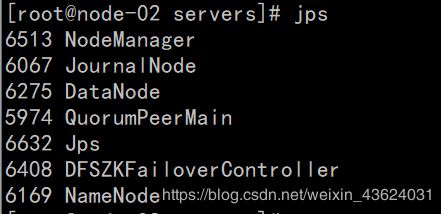
这里只需要核对前面的集群节点规划,判断自己的Hadoop HA集群是否搭建成功。
问题
在通过webUI界面查看时,直接在浏览器中输入node-01:50070,浏览器会提示无法访问,原因是未对本地操作系统中的hosts文件中添加IP映射。(如果不想配置,也可输入节点的IP+端口号访问web界面)
解决方案:WIN10下hosts文件路径:C:\Windows\System32\drivers\etc
在hosts文件中添加如下配置
192.168.114.140 node-01
192.168.114.141 node-02
192.168.114.142 node-03
添加完成后,保存退出即可。(效果如下)

