HDFS:NN、SNN、DN剖析
namenode被格式化之后,将在HADOOP_HOME/tmp/dfs/name/current (默认)产生以下文件:
参数:core-site.xml : hadoop.tmp.dir 指定hadoop运行时产生文件的存储目录
参数: hdfs-site.xml : dfs.namenode.name.dir 指定namenode产生的文件存放的目录
dfs.datanode.data.dir 指定datanode产生的文件存放的目录
fsimage文件 : 命名空间镜像文件,HDFS文件系统元数据的一个永久性的检查点,包含HDFS文件系统的所有目录和文件的序列化信息。 查看:hdfs oiv -p [转换格式(一般用XML)] -i [输入文件] -o [输出文件]
edits 文件:记录对namenode中元数据更新的每一步操作。查看:hdfs oev -p [转换格式(一般用XML)] -i [输入文件] -o [输出文件]
seen_txid:保存最后一个edits_的数字
每次NameNode启动的时候都会将fsimage文件读入内存,并从00001开始到seen_txid中记录的数字依次执行每个edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,NameNode启动的时候就将fsimage和edits文件进行了合并。
NN与SNN的工作机制
NN启动流程:
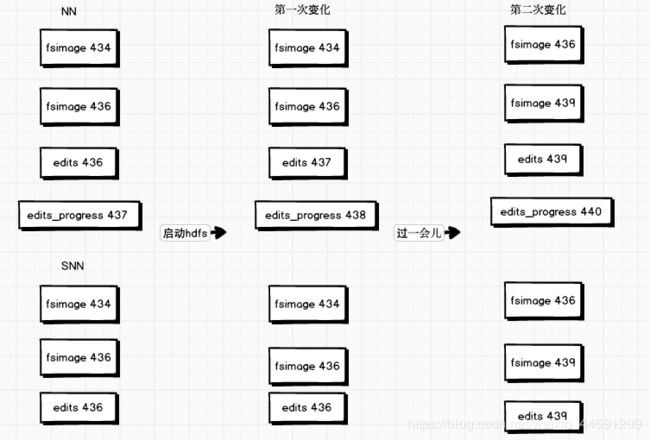
第一次变化:先滚动edits,s edits_progress437 分成了 edits437和edits_progress438 。 NN将fsimage和edits(edits的序号从fsimage的序号——seen_txid中的值)加载到内存中进行合并,并生成新的edits_progress,此时内存中是最新的元数据映像。
合并:即将fsimage中的元数据新的,按照edits中的操作执行一次。
第二次变化: SNN执行一次checkpoint操作,将edits 437-437 和 edits 438-439 和fsimage 436 发送到了SNN上,并合并生成了fsimage 439 。在本地目录下生成最新的映像,并加载回内存中。
启动完毕。
NN、SNN运行流程:

1、NN启动(见上)
2、Client对NN发送增删改查的请求,这些操作会被先记录在edits_inprogress中,再在内存中执行(查询的操作不会记录在edits中,因为不会改变元数据信息)。
3、由于edits中的记录越来越多,edits文件越来越大,导致NN在启动时加载edits会很慢。所以需要合并,SNN就是帮助NN进行fsimage和edits的合并工作。
当触发checkpoint条件时 (定时时间到,或者edits中数据满了),SNN会询问NN是否进行checkpoint操作,直接带回检查结果,SNN执行checkpoint操作。 首先会滚动edits,形成一个新的edits_progress,然后将滚动前的editis和其他未合并的editis和最新的fsimage将会被拷贝到SNN本地。
4、SNN加载edits和fsimage到内存,并合并。生成新的镜像文件:fsimage.ckpt。
5、拷贝fsimage.ckpt到NN,NN将它重新命名为fsimage。
checkpoint时间设置
hdfs-site.xml:
dfs.namenode.checkpoint.period 每隔多久做一次checkpoint ,默认3600s
dfs.namenode.checkpoint.txns 每隔多少操作次数做一次checkpoint,默认1000000次
dfs.namenode.checkpoint.check.period 每个多久检查一次操作次数,默认60s
安全模式
NN启动时,首先将fsimage载入内存,并执行edits中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个新的edits_progress。此时,NameNode开始监听DataNode请求,NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。集群处于安全模式,不能执行重要操作(写操作)。
在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别。
对应参数:
hdfs-site.xml :
dfs.namenode.replication.min 块满足最小副本级别 (默认为1)
dfs.namenode.safemode.threshold-pct 集群中满足正常配置的数据块比例 (默认为0.999f)
命令:
bin/hdfs dfsadmin -safemode get 查看安全模式状态
bin/hdfs dfsadmin -safemode enter 进入安全模式状态
bin/hdfs dfsadmin -safemode leave 离开安全模式状态
bin/hdfs dfsadmin -safemode wait 等待安全模式状态
DN工作机制
1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件:一个是数据本身,一个是元数据(数据块的长度,块数据的校验和,以及时间戳)。
2)DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。
参数(hdfs-site.xml):dfs.blockreport.intervalMsec 多久周期做一次blockreport, 默认21600000s
3)DN每3秒发送一次心跳信息。如果超过10分钟没有收到某个DataNode的心跳,则认为该节点不可用。
参数(hdfs-site.xml):dfs.heartbeat.interval 多久发送一次心跳信息 ,默认为3s
dfs.namenode.stale.datanode.interval 将数据节点标记为“过时”的时间间隔, 默认为300000ms
注:“过时”的节点不一定“死亡“。默认五分钟没有心跳就过时,十分钟没有心跳死亡。
4)当DataNode读取block的时候,它会进行校验,如果计算后的校验和,与block创建时值不一样,说明block已经损坏。client读取其他DataNode上的block。datanode在其文件创建后周期(三周)验证校验和。
5)集群运行中可以安全加入和退出一些机器