Python数据可视化--Pandas中的绘图函数
Series和DataFrame都有一个用于生成各类图表的plot方法。默认情况下,他们所生成的是线型图
1.折线图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 折线图
df['人均GDP(元)'].plot(color='r', linestyle='--', marker='*')
plt.show()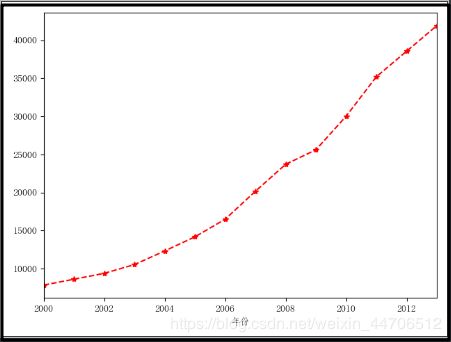
用文件中的所有数据绘制折线图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 绘制折线图
df.plot()
plt.show()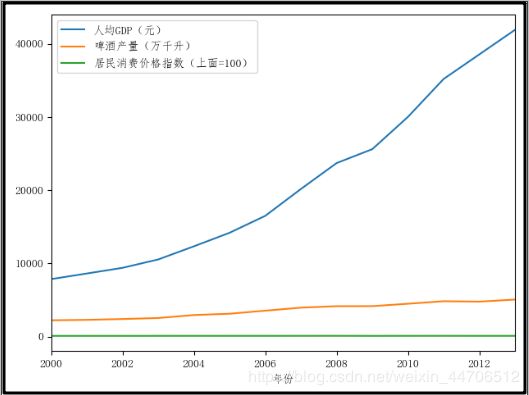
2.柱形图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 柱形图
df['人均GDP(元)'].plot(kind='bar',color='skyblue')
plt.show()
用文件中的所有数据绘制柱形图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 柱形图
df.plot(kind='bar')
plt.show()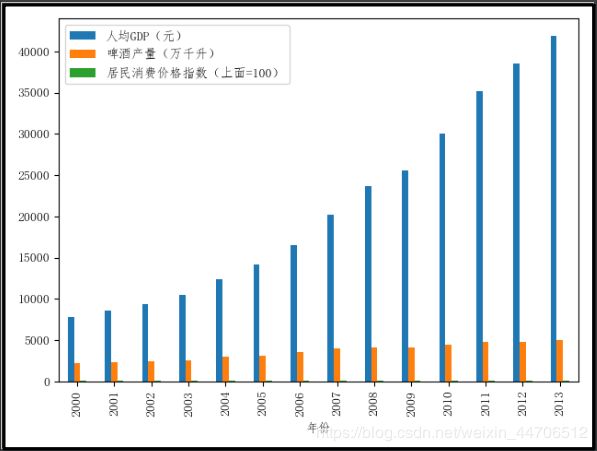
3.水平柱形图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 水平柱形图
df['人均GDP(元)'].plot(kind='barh',color='skyblue')
plt.show() 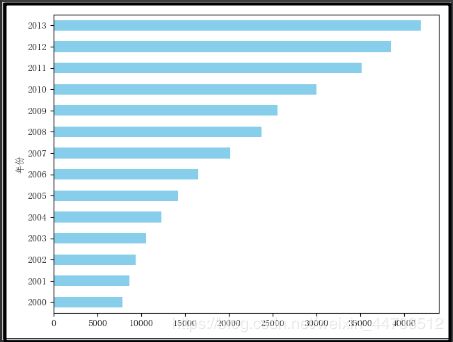
4.堆积柱形图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 堆积柱形图
df.plot(kind='bar', stacked=True)
plt.show() 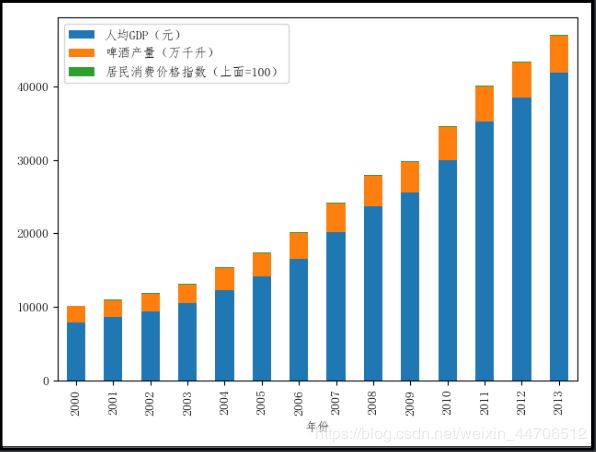
5.饼状图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 饼状图
df['人均GDP(元)'].plot(kind='pie')
plt.show()
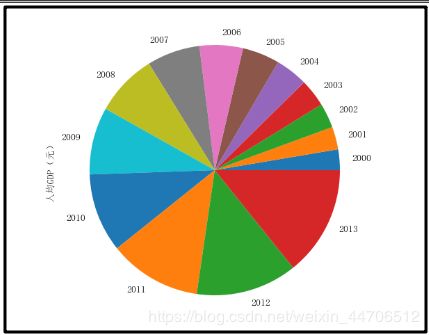
6.面积图
import pandas as pd
import matplotlib.pyplot as plt
# 指定默认字体(防止中文出现乱码)
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['FangSong'] # 指定‘仿宋’字体
# 读取数据
df = pd.read_csv('../data/data.csv', index_col='年份')
# 面积图
df['人均GDP(元)'].plot(kind='area')
plt.show() 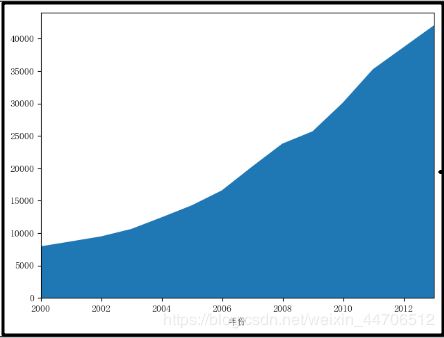
7.直方图
# 直方图
from pandas import Series
hist_data = Series([2, 3, 4, 5, 2, 3, 3, 4, 6, 5])
hist_data.plot(kind='hist')
plt.show()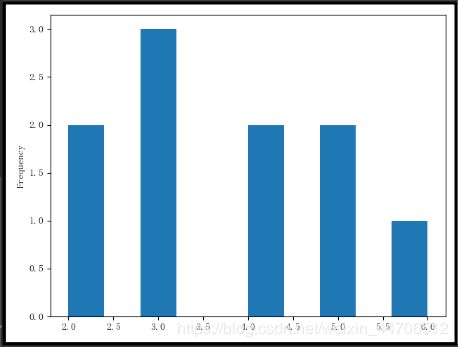
可以自定义分组
# 直方图---所有数据
from pandas import Series
hist_data = Series([2, 3, 4, 5, 2, 3, 3, 4, 6, 5])
# 自己定义分组
mybins = [1, 3, 5, 7] # 1~3,3~5,5~7分3组
hist_data.plot(kind='hist', bins=mybins) # 横坐标是分组,纵坐标是频率
plt.show()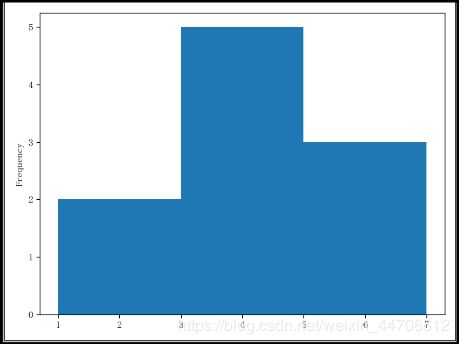
【附件】文件data.csv
年份,人均GDP(元),啤酒产量(万千升),居民消费价格指数(上面=100)
2000,7857.7,2231.3,100.4
2001,8621.7,2288.9,100.7
2002,9398.1,2402.7,99.2
2003,10542,2540.5,101.2
2004,12335.6,2948.6,103.9
2005,14185.4,3126.1,101.8
2006,16499.7,3543.58,101.5
2007,20169.5,3954.07,104.8
2008,23707.7,4156.91,105.9
2009,25607.5,4162.18,99.3
2010,30015,4490.16,103.3
2011,35197.8,4834.5,105.4
2012,38549.5,4778.58,102.6
2013,41907.6,5061.5,102.6