ElasticSearch安装及使用
前言
网上关于ES的文章非常多,为什么还要去重复的写一篇呢?
别人的终归是别人的,自己总结出来的看起来最方便。由于javaEE框架非常多,你冷落其中几个,过段时间就忘记了,只记得个大概,然后到使用时再搜索资料,那为什么不自己总结好,便于日后使用查看呢?
本文内容多数都来自互联网,包括官网资料、博客、其他人分享的资料,这块是对自己使用需要的一个总结。
简单介绍
ES是一个强大的搜索引擎,它是基于lucene实现的,lucene被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。而且ES是开源的,基于apache开源协议,社区非常活跃,可以说是最为流行的搜索引擎框架。
使用场景
1.像百度搜索、京东、淘宝的商品搜索,都可以使用ES来实现,它的优点就是基于海量数据的搜索。
2.像庞大的日志文件,如何从日志中搜索和统计想要的信息,比如访问量统计、某个ip的数据统计等,都可以通过访问时写入日志,然后通过es来做搜索和分析。
环境
Centos7、内存最好2g以上,环境这块没有准备好的话,参考我的另一篇文章,Linux复习
Java环境
es基于java环境,所以需要安装jdk。
首先将安装包导入到/opt/es目录,
接着解压安装包,
tar -zxvf jdk-8u171-linux-x64.tar.gz通过ll命令发现,现在使用的非root用户,而文件夹是root用户所属,权限不够,那么修改下当前用户的权限。改为当前非root用户。命令如下:
chown -R ming:ming es再通过ll命令查看,所属用户已经改变
![]()
然后通过su root切换到root用户,打开profile文件,修改环境变量
su root
vi /etc/profile
export JAVA_HOME=/opt/es/jdk1.8.0_171
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/LIB:$JRE_HOME/LIB:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
source /etc/profile修改成功后,通过如下命令查看是否配置成功,
java -version安装运行es
解压es的安装包,然后进入到bin目录运行如下命令,启动es
./elasticsearch当出现如下截图,代表启动成功。
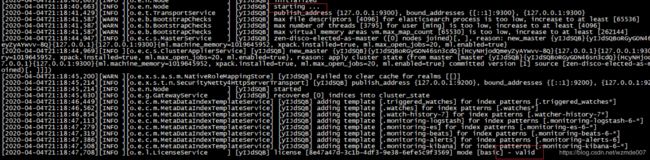
接着复制一个窗口,通过如下命令测试是否运行正常:
curl 127.0.0.1:9200如果出现如下内容,代表启动成功

这时,在浏览器访问地址是访问不通的,因为还需要配置ip地址
具体方式修改es下/config/elasticsearch.yml文件,在文件中找到如下截图,然后修改为本机ip

修改完成后,重新启动es。
期间可能遇到启动失败问题,参考这篇文章:https://www.cnblogs.com/zhi-leaf/p/8484337.html
启动成功后,通过浏览器就可以访问了,返回信息与上边curl的信息是一样的。
数据结构
在使用api之前,先了解下es是如何存储的,最顶层是index索引,然后是type类型,然后是doc文档,他们的层级可以理解父子关系,也就是index的儿子是type,type的儿子是doc,这种关系。但是对于type:
在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index 下只能存在一个 type;
在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type。(参考:https://www.cnblogs.com/miracle-luna/p/10998670.html)
就是说对于type,我们不要去管它,假如当前版本中还存在type,让它为默认值就好。所以数据结构就更简单了,数据库包含多个index,一个index包含多个doc。这样理解即可。
增删改查
es是基于restful的api风格,使用json来收发数据。
新增文档
如上边数据结构叙述,最小的单元是doc文档,所以新增数据也就是新增文档,因为文档的父亲是index,所以新增时指定index和doc的id即可,假如doc的id不指定,就会自动生成。
通过postman来新增一个doc。

请求方式为put,请求地址后跟的参数分别为index/type/id,注意为json格式,假如插入成功后,会返回下方的结果。
在返回结果中,可以看到_version是1,result为created代表初次创建, _shards代表分片。
也可以通过post的方式新增文档,适用于不指定id的情况,如下:
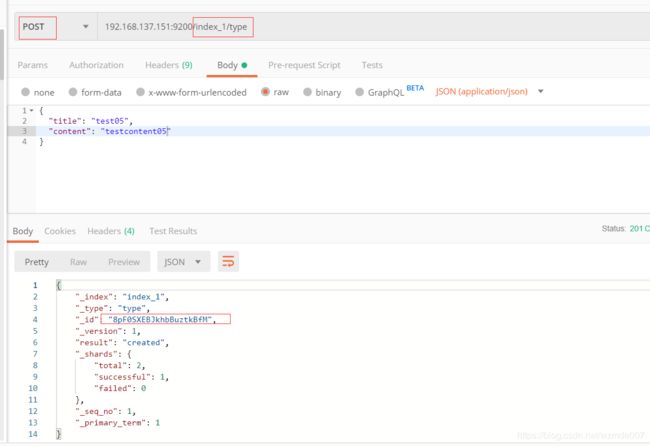
查询文档
获取文档比较简单,在地址后输入index/type/id即可查到指定的数据

也可以通过 地址/index/type/_search来获取指定index下的所有数据 。
也可以通过 地址/_search来获取所有数据。
也可以通过 地址/index/type/_source=title 来获取指定字段而不是全部。
还有很多方式:
GET /_search #查询所有索引文档
GET /my_index/_search #查询指定索引文档
GET /my_index1,my_index2/_search #多索引查询
GET /my_*/_search也可以通过 在_search后边加上?q=查询关键字来进行模糊搜索。例如q=test01或q=title:test01
详细规则如下:
GET /my_index/_search?q=keyword&df=user&sort=age:asc&from=4&size=10&timeout=1sq : 指定查询的语句,例如q=aa或q=user:aa
df:q中不指定字段默认查询的字段,如果不指定,es会查询所有字段
sort:排序,asc升序,desc降序
timeout:指定超时时间,默认不超时
from,size:用于分页
还可以通过mget的方式来获取多个检索条件的结果,这样省去了多次发送请求,如:
POST /_mget
{
"docs" : [
{
"_index" : "website",
"_type" : "blog",
"_id" : 2
},
{
"_index" : "website",
"_type" : "pageviews",
"_id" : 1,
"_source": "views"
}
]
}
或者
POST /website/blog/_mget
{
"ids" : [ "2", "1" ]
}
修改文档
更新文档和新增文档是一样的,只要指定id即可更新。
删除文档
删除文档基于delete请求方式,格式参考如下
DELETE /website/blog/123高级搜索
- 查询语句执行计划查看
GET test_search_index/_search?q=alfred { "profile":true } - term查询
看如下语句中,alfred 和way 逗号分隔,他们之间是属于or的关系,数据中,包含alfred或者way的都会搜索出来。GET test_search_index/_search?q=username:alfred way #alfred OR way - phrase查询
看如下语句中,“alfred way” 会被当做一句话或者说一个单词来搜索。GET test_search_index/_search?q=username:"alfred way" - group查询
group查询跟mysql的groupby查询是一样的,想讲明白的话是需要一点篇幅的,这块直接参考这篇文章吧:https://blog.csdn.net/ydwyyy/article/details/79487995GET test_search_index/_search?q=username:(alfred way) - 布尔操作符
(1)AND(&&),OR(||),NOT(!)
例如:name:(tom NOT lee)
#表示name字段中可以包含tom但一定不包含lee
- +、-分别对应must和must_not
例如:name:(tom +lee -alfred)
#表示name字段中,一定包含lee,一定不包含alfred,可以包含tom
注意:+在url中会被解析成空格,要使用encode后的结果才可以,为%2B
GET test_search_index/_search?q=username:(alfred %2Bway)
- 范围查询,支持数值和日期
- 区间:闭区间:[],开区间:{}
age:[1 TO 10] #1<=age<=10
age:[1 TO 10} #1<=age<10
age:[1 TO ] #1<=age
age:[* TO 10] #age<=10
- 算术符号写法
age:>=1
age:(>=1&&<=10)或者age:(+>=1 +<=10)
- 通配符查询
?:1个字符
*:0或多个字符
例如:name:t?m
name:tom*
name:t*m
注意:通配符匹配执行效率低,且占用较多内存,不建议使用,如无特殊要求,不要讲?/*放在最前面
- 正则表达式
name:/[mb]oat/
- 模糊匹配fuzzy query
name:roam~1
匹配与roam差1个character的词,比如foam、roams等
- 近似度查询proximity search
“fox quick”~5
以term为单位进行差异比较,比如”quick fox” “quick brown fox”
搜索原理
原理:结合分词生成正排索引和倒排索引,搜索基于这2种索引,速度飞起。
分词:是指将文本转换成一系列单词(term or token)的过程,也可以叫做文本分析,在es里面称为Analysis。比如说hello world
就会被拆分成2个单词,一般英文都是按照空格来拆分单词。中文的话一般都需要另下分词器插件,比如IK分词器。
通过上边的介绍,可以知道,分词是需要制定分词规则的,尤其是中文的分词。我们可以自定义分词规则,也可以直接使用ik分词器,根据需求而定。制定好规则后,就可以测试了。
POST _analyze
{
"analyzer": "standard",//分词器名称
"text":"hello 1111"//待分词的语句。
}
正排索引:记录文档Id到文档内容、单词的关联关系.比如:
看如下表格,是3条文档数据,对于php关键字,只有1、2两条有,那么对于php这个单词,会有这样的关系【php:1,2】其中1、2是对应的文档id。这个关系就是正排索引。
| docid |
content |
| 1 |
php呵呵 |
| 2 |
php是世界上最好的语言 |
| 3 |
hello world |
倒排索引:记录单词倒排列表的关联信息。我们知道分词后会有一个字典库(Term DicTionary):记录所有文档的单词,一般比较大,倒排索引会依赖这个库建立关联信息。如下:
Posting List
| DocId |
TF |
Position |
Offset |
| 1 |
1 |
0 |
<0,2> |
| 2 |
1 |
0 |
<0,2> |
DocId:文档id,文档的原始信息
TF:单词频率,记录该词再文档中出现的次数,用于后续相关性算分
Position:位置,记录Field分词后,单词所在的位置,从0开始
Offset:偏移量,记录单词在文档中开始和结束位置,用于高亮显示等
每个文档都有自己的倒排索引,倒排索引是基于B+tree实现的,跟mysql的innerdb引擎一样。
索引配置
类似mysql中表的设置一样,可以通过下列方式获取索引的默认配置
GET /index/_mapping通过设置,可以修改分词器和具体doc的字段类型。
es依靠json文档字段类型来实现自动识别字段类型,支持的类型
| JSON类型 |
es类型 |
| null |
忽略 |
| boolean |
boolean |
| 浮点类型 |
float |
| 整数 |
long |
| object |
object |
| array |
由第一个非null值的类型决定 |
| string |
匹配为日期则设为data类型(默认开启) 匹配为数字的话设为float或long类型(默认关闭) 设为text类型,并附带keyword的子字段 |
配置中有一个字段需要注意dynamic,它的value含义如下:
- true:允许自动新增字段(默认的配置)(比如第一个文档插入2个字段,第二个文档插入3个字段,这就是自动新增一个)
- False:不允许自动新增字段,但是文档可以正常写入,无法对字段进行查询操作
- strict:文档不能写入(如果写入会报错)
相关参考文章:https://www.cnblogs.com/cjsblog/p/10327673.html
集群
集群配置挺简单的这里也不做记录了。最少2台机器。
Java操作es
两种方式,一种是通过es官方提供的jar包操作。这种方式使用起来比较麻烦,类似mysql的jdbc。
另外一种方式是使用SpringDataElasticSearch。看到SpringData就知道,使用起来非常方便,前边文章介绍过SrpingDataJpa。上手非常容易,SpringDataElasticSearch使用方式跟SrpingDataJpa基本一样。所以这块就不做介绍,具体参见SrpingDataJpa或者去网上搜索相关教程。
这里注意一点,SpringDataElasticSearch再做条件查询时,一句话会分成多个词去查询,但是词与词之间是通过and来搜索的,就是都满足条件才会返回。假如想用or来实现就需要通过NativeSearchQuery来实现。
es图形客户端
es的图形界面操作工具参考使用elasticsearch-head。
安装参考:https://www.cnblogs.com/commissar-Xia/p/10507769.html
Kibana
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在Elasticsearch索引中的数据。使用Kibana,可以通过各种图表进行高级数据分析及展示
参考文章:https://www.jianshu.com/p/e37d0ecef451
------------后续可能还会补充------------