云主机tar包离线部署cdh
环境: 阿里云三台:centos7.2 hadoop001 hadoop002 hadoop003
上传所需要的安装包到hadoop001
[root@hadoop001 ~]# ll
total 3605076
-rw-r--r-- 1 root root 2127506677 Oct 19 00:00 CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
-rw-r--r-- 1 root root 41 Oct 18 23:48 CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1
-rw-r--r-- 1 root root 841524318 Oct 18 23:57 cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz
-rw-r--r-- 1 root root 173271626 Oct 18 23:49 jdk-8u45-linux-x64.gz
-rw-r--r-- 1 root root 66538 Oct 18 23:48 manifest.json
-rw-r--r-- 1 root root 548193637 Oct 18 23:53 mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz
-rw-r--r-- 1 root root 1007502 Oct 18 23:48 mysql-connector-java-5.1.47.jar
1.配置三台机器的hosts文件(云主机使用内网)
172.17.124.159 hadoop001
172.17.124.161 hadoop002
172.17.124.160 hadoop003
2.关闭防火墙,三台都要做(针对Centos7的操作)
云主机: 关闭 + web防火墙
[root@hadoop001 ~]# systemctl stop firewalld
[root@hadoop001 ~]# systemctl disable firewalld
[root@hadoop001 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
[root@hadoop001 ~]# iptables -F
3.关闭selinux ,不然部署会有问题,三台都要做,然后重启机器生效
[root@hadoop001 ~]# vi /etc/selinux/config
# This file controls the state of SELinux on the system.
# SELINUX= can take one of these three values:
# enforcing - SELinux security policy is enforced.
# permissive - SELinux prints warnings instead of enforcing.
# disabled - No SELinux policy is loaded.
# hwz update SELINUX=disabled
SELINUX=disabled
# SELINUXTYPE= can take one of three two values:
# targeted - Targeted processes are protected,
# minimum - Modification of targeted policy. Only selected processes are protected.
# mls - Multi Level Security protection.
SELINUXTYPE=targeted
3.设置时区和时钟同步(云主机不用做这一步)
[root@hadoop001 ~]# timedatectl set-timezone Asia/Shanghai
[root@hadoop002 ~]# timedatectl set-timezone Asia/Shanghai
[root@hadoop003 ~]# timedatectl set-timezone Asia/Shanghai
4.使用ntp服务设置时间同步
分别在三台机器上安装安装ntp:yum install -y ntp
[root@hadoop001 ~]# yum install -y ntp
[root@hadoop002 ~]# yum install -y ntp
[root@hadoop003 ~]# yum install -y ntp
设置hadoop001机器为时间同步主节点:
[root@hadoop001 ~]# vi /etc/ntp.conf
#添加网络时间同步:https://www.pool.ntp.org/zone/asia
server 0.asia.pool.ntp.org
server 1.asia.pool.ntp.org
server 2.asia.pool.ntp.org
server 3.asia.pool.ntp.org
#这句话的意思是当上边的网络同步不可用的时候使用本地的时间
server 127.127.1.0 iburst local clock
#这句话的意思是允许哪个网段的机器同步我们的时间,172.17.124是我们机器的内网网段
restrict 172.17.124.0 mask 255.255.255.0 nomodify notrap
启动ntp服务:
[root@hadoop001 ~]# systemctl start ntpd
[root@hadoop001 ~]# systemctl status ntpd
验证:
[root@hadoop001 ~]# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
LOCAL(0) .LOCL. 10 l 1066 64 0 0.000 0.000 0.000
+120.25.115.20 10.137.53.7 2 u 10 64 377 36.814 1177.87 11.012
10.143.33.49 .INIT. 16 u - 1024 0 0.000 0.000 0.000
+100.100.3.1 10.137.55.181 2 u 40 64 377 23.912 1171.74 10.987
+100.100.3.2 10.137.55.181 2 u 39 64 377 25.706 1185.94 15.803
x100.100.3.3 10.137.55.181 2 u 39 64 365 26.497 1189.70 28.429
+203.107.6.88 100.107.25.114 2 u 33 64 377 13.084 1168.27 12.916
10.143.33.50 .INIT. 16 u - 1024 0 0.000 0.000 0.000
10.143.33.51 .INIT. 16 u - 1024 0 0.000 0.000 0.000
10.143.0.44 .INIT. 16 u - 1024 0 0.000 0.000 0.000
10.143.0.45 .INIT. 16 u - 1024 0 0.000 0.000 0.000
10.143.0.46 .INIT. 16 u - 1024 0 0.000 0.000 0.000
+100.100.5.1 10.137.55.181 2 u 32 64 377 31.296 1157.39 19.792
+100.100.5.2 10.137.55.181 2 u 34 64 377 28.368 1170.50 10.922
-100.100.5.3 10.137.55.181 2 u 29 64 377 26.694 1159.61 19.694
*100.100.61.88 .BD. 1 u 5 64 377 0.152 1179.28 10.850
以上都只需要在hadoop001时间同步主节点上操作
设置hadoop002,hadoop003时间同步从节点去同步hadoop001的时间:
首先关闭hadoop002,hadoop003机器上的ntpd,不然等于说都是使用的网络同步,而我们是需要将hadoop002,hadoop003去参照hadoop001的时间去同步的
[root@hadoop002 ~]# systemctl status ntpd
[root@hadoop002 ~]# systemctl stop ntpd
[root@hadoop002 ~]# systemctl disable ntpd
[root@hadoop003 ~]# systemctl status ntpd
[root@hadoop003 ~]# systemctl stop ntpd
[root@hadoop003 ~]# systemctl disable ntpd
##设置去同步hadoop001的时间
[root@hadoop002 ~]# /usr/sbin/ntpdate hadoop001
19 Oct 10:38:40 ntpdate[2310]: step time server 172.17.124.159 offset -0.813099 sec
##设置去同步hadoop001的时间
[root@hadoop003 ~]# /usr/sbin/ntpdate hadoop001
19 Oct 10:38:40 ntpdate[2310]: step time server 172.17.124.159 offset -0.813099 sec
但是为了避免时间会慢慢不同步,所以需要设置每隔多久去同步一次时间
分别在hadoop002,hadoop003上去设置
[root@hadoop002 ~]# crontab -e
#每天的凌晨去同步一次时间
00 00 * * * /usr/sbin/ntpdate hadoop001
[root@hadoop003 ~]# crontab -e
#每天的凌晨去同步一次时间
00 00 * * * /usr/sbin/ntpdate hadoop001
5.安装jdk,三台都需要安装 [参考链接](https://blog.csdn.net/yoohhwz/article/details/93316844)
6.mysql部署在hadoop001上
[root@hadoop001 ~]# tar -zxvf mysql-5.7.11-linux-glibc2.5-x86_64.tar.gz -C /usr/local/
#重命名
[root@hadoop001 local]# mv mysql-5.7.11-linux-glibc2.5-x86_64/ mysql
##创建所需要的目录
[root@hadoop001 local]# mkdir mysql/arch mysql/data mysql/tmp
#创建配置文件
[root@hadoop001 local]# vi /etc/my.cnf
[client]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
default-character-set=utf8mb4
[mysqld]
port = 3306
socket = /usr/local/mysql/data/mysql.sock
skip-slave-start
skip-external-locking
key_buffer_size = 256M
sort_buffer_size = 2M
read_buffer_size = 2M
read_rnd_buffer_size = 4M
query_cache_size= 32M
max_allowed_packet = 16M
myisam_sort_buffer_size=128M
tmp_table_size=32M
table_open_cache = 512
thread_cache_size = 8
wait_timeout = 86400
interactive_timeout = 86400
max_connections = 600
# Try number of CPU's*2 for thread_concurrency
#thread_concurrency = 32
#isolation level and default engine
default-storage-engine = INNODB
transaction-isolation = READ-COMMITTED
server-id = 1739
basedir = /usr/local/mysql
datadir = /usr/local/mysql/data
pid-file = /usr/local/mysql/data/hostname.pid
#open performance schema
log-warnings
sysdate-is-now
binlog_format = ROW
log_bin_trust_function_creators=1
log-error = /usr/local/mysql/data/hostname.err
log-bin = /usr/local/mysql/arch/mysql-bin
expire_logs_days = 7
innodb_write_io_threads=16
relay-log = /usr/local/mysql/relay_log/relay-log
relay-log-index = /usr/local/mysql/relay_log/relay-log.index
relay_log_info_file= /usr/local/mysql/relay_log/relay-log.info
log_slave_updates=1
gtid_mode=OFF
enforce_gtid_consistency=OFF
# slave
slave-parallel-type=LOGICAL_CLOCK
slave-parallel-workers=4
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay_log_recovery=ON
#other logs
#general_log =1
#general_log_file = /usr/local/mysql/data/general_log.err
#slow_query_log=1
#slow_query_log_file=/usr/local/mysql/data/slow_log.err
#for replication slave
sync_binlog = 500
#for innodb options
innodb_data_home_dir = /usr/local/mysql/data/
innodb_data_file_path = ibdata1:1G;ibdata2:1G:autoextend
innodb_log_group_home_dir = /usr/local/mysql/arch
innodb_log_files_in_group = 4
innodb_log_file_size = 1G
innodb_log_buffer_size = 200M
#根据生产需要,调整pool size,我们生产是12G,这里学习用2G足够
innodb_buffer_pool_size = 2G
#innodb_additional_mem_pool_size = 50M #deprecated in 5.6
tmpdir = /usr/local/mysql/tmp
innodb_lock_wait_timeout = 1000
#innodb_thread_concurrency = 0
innodb_flush_log_at_trx_commit = 2
innodb_locks_unsafe_for_binlog=1
#innodb io features: add for mysql5.5.8
performance_schema
innodb_read_io_threads=4
innodb-write-io-threads=4
innodb-io-capacity=200
#purge threads change default(0) to 1 for purge
innodb_purge_threads=1
innodb_use_native_aio=on
#case-sensitive file names and separate tablespace
innodb_file_per_table = 1
lower_case_table_names=1
[mysqldump]
quick
max_allowed_packet = 128M
[mysql]
no-auto-rehash
default-character-set=utf8mb4
[mysqlhotcopy]
interactive-timeout
[myisamchk]
key_buffer_size = 256M
sort_buffer_size = 256M
read_buffer = 2M
write_buffer = 2M
#创建mysql用户mysqladmin
[root@hadoop001 local]# groupadd -g 101 dba
[root@hadoop001 local]# useradd -u 514 -g dba -G root -d /usr/local/mysql mysqladmin
[root@hadoop001 local]# cp /etc/skel/.* /usr/local/mysql/
#配置环境变量已经配置mysqladmin用户界面格式
[root@hadoop001 local]# vi /usr/local/mysql/.bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export MYSQL_BASE=/usr/local/mysql
export PATH=${MYSQL_BASE}/bin:$PATH
unset USERNAME
#stty erase ^H
set umask to 022
umask 022
PS1=`uname -n`":"'$USER'":"'$PWD'":>"; export PS1
##赋权限和用户组
[root@hadoop001 local]# chown mysqladmin:dba /etc/my.cnf
[root@hadoop001 local]# chmod 640 /etc/my.cnf
[root@hadoop001 local]# chown -R mysqladmin:dba /usr/local/mysql
[root@hadoop001 local]# chmod -R 755 /usr/local/mysql
##配置服务及开机自启动
[root@hadoop001 local]# cd /usr/local/mysql
#将服务文件拷贝到init.d下,并重命名为mysql
[root@hadoop001 mysql]# cp support-files/mysql.server /etc/rc.d/init.d/mysql
#赋予可执行权限
[root@hadoop001 mysql]# chmod +x /etc/rc.d/init.d/mysql
#删除服务
[root@hadoop001 mysql]# chkconfig --del mysql
#添加服务,开机自启
[root@hadoop001 mysql]# chkconfig --add mysql
[root@hadoop001 mysql]# chkconfig --level 345 mysql on
##检查一下,发现mysql的345权限已开,表示开机自启
[root@hadoop001 mysql]# chkconfig --list
Note: This output shows SysV services only and does not include native
systemd services. SysV configuration data might be overridden by native
systemd configuration.
If you want to list systemd services use 'systemctl list-unit-files'.
To see services enabled on particular target use
'systemctl list-dependencies [target]'.
aegis 0:off 1:off 2:on 3:on 4:on 5:on 6:off
mysql 0:off 1:off 2:on 3:on 4:on 5:on 6:off
netconsole 0:off 1:off 2:off 3:off 4:off 5:off 6:off
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
##安装libaio及安装mysql的初始db
[root@hadoop39 mysql]# yum -y install libaio
[root@hadoop001 mysql]# su - mysqladmin
hadoop001:mysqladmin:/usr/local/mysql:>bin/mysqld \
> --defaults-file=/etc/my.cnf \
> --user=mysqladmin \
> --basedir=/usr/local/mysql/ \
> --datadir=/usr/local/mysql/data/ \
> --initialize
在初始化时如果加上 –initial-insecure,则会创建空密码的 root@localhost 账号,否则会创建带密码的 root@localhost 账号,密码直接写在 log-error 日志文件中
(在5.6版本中是放在 ~/.mysql_secret 文件里)
##查看初始密码
hadoop001:mysqladmin:/usr/local/mysql:>cat data/hostname.err |grep password
2019-10-19T04:01:50.083005Z 1 [Note] A temporary password is generated for root@localhost: *hVf(ngi5sUR
##启动,按两下回车键
hadoop001:mysqladmin:/usr/local/mysql:>/usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf &
[1] 11910
hadoop001:mysqladmin:/usr/local/mysql:>2019-10-19T04:06:55.618806Z mysqld_safe Logging to '/usr/local/mysql/data/hostname.err'.
2019-10-19T04:06:55.639441Z mysqld_safe Starting mysqld daemon with databases from /usr/local/mysql/data
##查看进程
hadoop001:mysqladmin:/usr/local/mysql:>ps -ef|grep mysql
root 11831 2039 0 11:59 pts/0 00:00:00 su - mysqladmin
mysqlad+ 11832 11831 0 11:59 pts/0 00:00:00 -bash
mysqlad+ 11910 11832 0 12:06 pts/0 00:00:00 /bin/sh /usr/local/mysql/bin/mysqld_safe --defaults-file=/etc/my.cnf
mysqlad+ 12727 11910 0 12:06 pts/0 00:00:00 /usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data --plugin-dir=/usr/local/mysql/lib/plugin --log-error=/usr/local/mysql/data/hostname.err --pid-file=/usr/local/mysql/data/hostname.pid --socket=/usr/local/mysql/data/mysql.sock --port=3306
mysqlad+ 12755 11832 0 12:07 pts/0 00:00:00 ps -ef
mysqlad+ 12756 11832 0 12:07 pts/0 00:00:00 grep --color=auto mysql
##使用root用户查看端口号
[root@hadoop001 local]# netstat -nltp | grep 12727
tcp6 0 0 :::3306 :::* LISTEN 12727/mysqld
在这里也可以使用CentOS6的mysql相关命令:
hadoop001:mysqladmin:/usr/local/mysql:>service mysql status
MySQL running (12727)[ OK ]
以及service mysql start|stop|restart
##登录及修改用户密码
##使用刚才生成的密码登陆,如果密码中有 '(',可以在-p 后加 ' ',将密码括起来
hadoop001:mysqladmin:/usr/local/mysql:>mysql -uroot -p'*hVf(ngi5sUR'
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.11-log
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> alter user root@localhost identified by '123456';
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' ;
mysql> flush privileges;
mysql> exit;
使用新密码即可重新登陆
7.因为部署cdh的时候会有元数据,所以在mysql中创建cmf,amon数据库
##创建数据库
mysql> create database cmf DEFAULT CHARACTER SET utf8;
mysql> create database amon DEFAULT CHARACTER SET utf8;
##权限
mysql> GRANT ALL PRIVILEGES ON cmf.* TO 'cmf'@'%' IDENTIFIED BY '123456' ;
mysql> GRANT ALL PRIVILEGES ON amon.* TO 'amon'@'%' IDENTIFIED BY '123456' ;
8.部署mysql connector jar包
##固定位置
[root@hadoop001 local]# mkdir -p /usr/share/java
##copy jar包的时候记得要去掉版本号,不然会有问题
[root@hadoop001 local]# cp /root/mysql-connector-java-5.1.47.jar /usr/share/java/mysql-connector-java.jar
9.部署cm
将hadoop001上的cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz scp到其它两台节点
[root@hadoop001 ~]# scp cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz hadoop002:/root
[root@hadoop001 ~]# scp cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz hadoop003:/root
##创建固定目录,不要乱改,三台都要创建
[root@hadoop001 ~]# mkdir /opt/cloudera-manage
[root@hadoop002 ~]# mkdir /opt/cloudera-manage
[root@hadoop003 ~]# mkdir /opt/cloudera-manage
##解压cm包到 /opt/cloudera-manage路径
[root@hadoop001 ~]# tar -zxvf /root/cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz -C /opt/cloudera-manage/
[root@hadoop002 ~]# tar -zxvf /root/cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz -C /opt/cloudera-manage/
[root@hadoop003 ~]# tar -zxvf /root/cloudera-manager-centos7-cm5.16.1_x86_64.tar.gz -C /opt/cloudera-manage/
##修改agent端 server_host为hadoop001,三台都要做
[root@hadoop001 ~]# cd /opt/cloudera-manage/cm-5.16.1/etc/cloudera-scm-agent
[root@hadoop001 cloudera-scm-agent]# vi config.ini
#hwz update server_host=hadoop001
server_host=hadoop001
[root@hadoop002 ~]# cd /opt/cloudera-manage/cm-5.16.1/etc/cloudera-scm-agent
[root@hadoop002 cloudera-scm-agent]# vi config.ini
#hwz update server_host=hadoop001
server_host=hadoop001
[root@hadoop003 ~]# cd /opt/cloudera-manage/cm-5.16.1/etc/cloudera-scm-agent
[root@hadoop003 cloudera-scm-agent]# vi config.ini
#hwz update server_host=hadoop001
server_host=hadoop001
##修改server端,只需要修改hadoop001机器即可
[root@hadoop001 ~]# cd /opt/cloudera-manage/cm-5.16.1/etc/cloudera-scm-server
[root@hadoop001 cloudera-scm-server]# vi db.properties
去掉以下属性的注释并修改值:
com.cloudera.cmf.db.host=hadoop001
com.cloudera.cmf.db.name=cmf
com.cloudera.cmf.db.user=cmf
##123456对应cmf数据的密码
com.cloudera.cmf.db.password=123456
##如果没有这个属性的话不用担心,如果有的话记得将值改为 EXTERNAL
com.cloudera.cmf.db.setupType=EXTERNAL
增加cloudera-scm用户,三台都要做:
[root@hadoop001 ~]# useradd --system --home=/opt/cloudera-manage/cm-5.16.1/run/cloudera-scm-server/ --no-create-home --shell=/bin/false cloudera-scm
[root@hadoop002 ~]# useradd --system --home=/opt/cloudera-manage/cm-5.16.1/run/cloudera-scm-server/ --no-create-home --shell=/bin/false cloudera-scm
[root@hadoop003 ~]# useradd --system --home=/opt/cloudera-manage/cm-5.16.1/run/cloudera-scm-server/ --no-create-home --shell=/bin/false cloudera-scm
修改cm所属用户,所属用户组为cloudera-scm用户:三台都要做
[root@hadoop001 ~]# chown -R cloudera-scm:cloudera-scm /opt/cloudera-manage
[root@hadoop002 ~]# chown -R cloudera-scm:cloudera-scm /opt/cloudera-manage
[root@hadoop003 ~]# chown -R cloudera-scm:cloudera-scm /opt/cloudera-manage
参数说明:
home指定用户家目录,no-create-home表示不用系统创建,shell=/bin/false表示不登录
10.parcel文件离线源
在hadoop001上创建固定目录,别乱改
[root@hadoop001 ~]# mkdir -p /opt/cloudera/parcel-repo
将
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1
manifest.json
移动到 /opt/cloudera/parcel-repo 目录下,要注意将CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1中的尾巴1通过mv的时候去掉
[root@hadoop001 ~]# mv CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel /opt/cloudera/parcel-repo/
[root@hadoop001 ~]# mv CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1 /opt/cloudera/parcel-repo/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha
[root@hadoop001 ~]# mv manifest.json /opt/cloudera/parcel-repo/
##修改所属用户以及所属用户组为 cloudera-scm用户
[root@hadoop001 parcel-repo]# chown -R cloudera-scm:cloudera-scm /opt/cloudera
11.创建大数据软件的安装目录,修改用户和用户组权限,三台都要做
[root@hadoop001 ~]# mkdir -p /opt/cloudera/parcels
[root@hadoop002 ~]# mkdir -p /opt/cloudera/parcels
[root@hadoop003 ~]# mkdir -p /opt/cloudera/parcels
[root@hadoop001 ~]# chown -R cloudera-scm:cloudera-scm /opt/cloudera
[root@hadoop001 ~]# chown -R cloudera-scm:cloudera-scm /opt/cloudera
[root@hadoop001 ~]# chown -R cloudera-scm:cloudera-scm /opt/cloudera
12.尝试启动server,agent
[root@hadoop001 ~]# cd /opt/cloudera-manage/cm-5.16.1/etc/init.d
##启动hadoop001上的server
[root@hadoop001 init.d]# ./cloudera-scm-server start
Starting cloudera-scm-server: [ OK ]
server启动之后必须要等待大概1分钟再去启动agent,这时候可以去hadoop001下的 /opt/cloudera-manage/cm-5.16.1/log/cloudera-scm-server/cloudera-scm-server.log 查看启动日志,发现7180端口已经启动:
Started [email protected]:7180
##启动agent ,三台都要启动
[root@hadoop001 init.d]# ./cloudera-scm-agent start
Starting cloudera-scm-agent: [ OK ]
[root@hadoop002 init.d]# ./cloudera-scm-agent start
Starting cloudera-scm-agent: [ OK ]
[root@hadoop003 init.d]# ./cloudera-scm-agent start
Starting cloudera-scm-agent: [ OK ]
一定要去开启web 7180的防火墙
然后使用hadoop001的公网ip加上7180端口号就可以访问web了,接下来就是点点点的操作了
在设置数据库的时候使用我们上边创建的 amon数据库,amon用户
-----------------------
部署kafka
在add service页面看到
![]()
意思就是说在添加kafka服务之前,你需要先去激活kafka的parcel文件或者安装包
去[该网址](http://archive.cloudera.com/kafka/parcels/)下载所需要版本的parcel文件:
http://archive.cloudera.com/kafka/parcels/
创建文件夹,存放下载的kafka文件
[root@hadoop001 ~]# mkdir kafka_parcel
上传:
[root@hadoop001 kafka_parcel]# ll
total 85708
-rw-r--r-- 1 root root 87751486 Nov 17 10:12 KAFKA-4.1.0-1.4.1.0.p0.4-el7.parcel
-rw-r--r-- 1 root root 41 Jul 11 22:04 KAFKA-4.1.0-1.4.1.0.p0.4-el7.parcel.sha1
-rw-r--r-- 1 root root 5212 Jul 11 22:04 manifest.json
记得要把xxx.sha1的改名把1去掉
[root@hadoop001 kafka_parcel]# mv KAFKA-4.1.0-1.4.1.0.p0.4-el7.parcel.sha1 KAFKA-4.1.0-1.4.1.0.p0.4-el7.parcel.sha
然后安装http服务:只需要在hadoop001上安装即可
[root@hadoop001 kafka_parcel]# yum install -y httpd
启动http:
[root@hadoop001 kafka_parcel]# service httpd start
Redirecting to /bin/systemctl start httpd.service
然后以hadoop001的外网ip+80端口可以看下http是否启动成功,打开则成功。
然后将kafka_parcel 移动到/var/www/html 路径下
[root@hadoop001 ~]# cd /var/www/html/
[root@hadoop001 html]# ll
total 4
drwxr-xr-x 2 root root 4096 Oct 19 20:41 cdh5
[root@hadoop001 html]# mv ~/kafka_parcel/ /var/www/html/
[root@hadoop001 html]# ll
total 8
drwxr-xr-x 2 root root 4096 Oct 19 20:41 cdh5
drwxr-xr-x 2 root root 4096 Nov 17 10:14 kafka_parcel
这时候你使用web页面以hadoop001的外网拼接上/kafka_parcel进行访问,你就使用http访问到我们kafka_parcel里面的文件了:
http://47.94.238.53/kafka_parcel/

但是我们知道集群内部都是使用的内网进行交互的,所以我们测试一下内网是否能够访问的到这些文件:hosts文件配置就是使用的内网,所以我们可以直接使用主机名
[root@hadoop001 html]# curl http://hadoop001/kafka_parcel/
Index of /kafka_parcel
Index of /kafka_parcel
![[ICO]](/icons/blank.gif)
Name Last modified Size Description
![[PARENTDIR]](/icons/back.gif)
Parent Directory - ![[ ]](/icons/unknown.gif)
KAFKA-4.1.0-1.4.1.0...> 2019-11-17 10:12 84M KAFKA-4.1.0-1.4.1.0...> 2019-07-11 22:04 41 manifest.json 2019-07-11 22:04 5.1K
发现没有问题,测试另外两台也同样访问的到
然后去cdh的web页面点击Hosts->parcel->configuration 添加我们的hadoop001的内网ip拼接上/kafka_parcel/这个地址作为我们kafka parcel源的地址
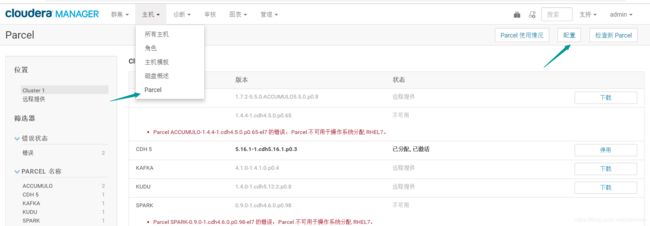
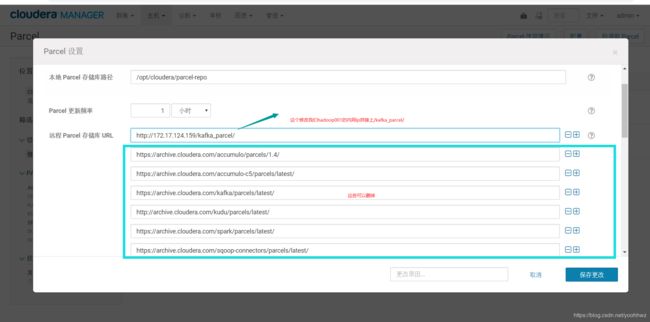
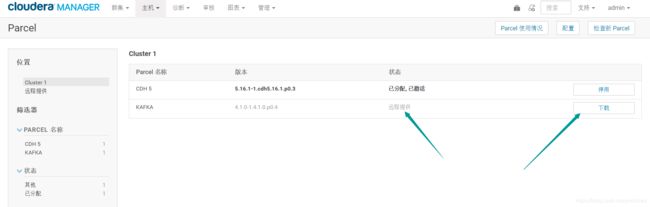
点击下载-->点击分发-->点击激活

都是成功的
然后去我们parcels目录下发现有了kafka的目录并且也为我们创建了kafka的软连接
[root@hadoop001 parcels]# cd /opt/cloudera/parcels/
[root@hadoop001 parcels]# ll
total 8
lrwxrwxrwx 1 root root 27 Nov 17 09:49 CDH -> CDH-5.16.1-1.cdh5.16.1.p0.3
drwxr-xr-x 11 root root 4096 Nov 22 2018 CDH-5.16.1-1.cdh5.16.1.p0.3
lrwxrwxrwx 1 root root 24 Nov 17 11:09 KAFKA -> KAFKA-4.1.0-1.4.1.0.p0.4
drwxr-xr-x 6 root root 4096 Jul 3 17:27 KAFKA-4.1.0-1.4.1.0.p0.4
接下来就可以add kafka Service了
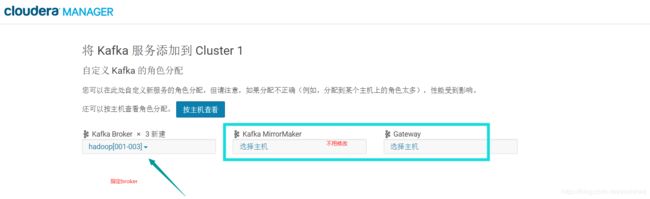
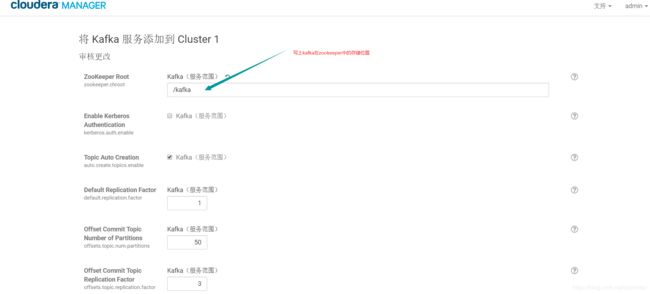
然后到kafka配置文件中修改kafka Broker的heap memory
broker_max_heap_size=50M(默认50M,修改为1G),不然启动kafka的时候会报错
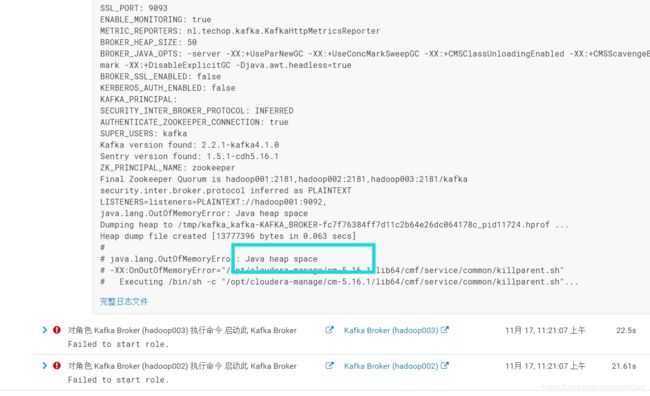
安装之后选择启动kafka
然后kafka安装之后的目录在:
[root@hadoop001 ~]# cd /opt/cloudera/parcels/KAFKA/lib/kafka
[root@hadoop001 kafka]# ll
total 60
drwxr-xr-x 2 root root 4096 Jul 3 17:27 bin
drwxr-xr-x 2 root root 4096 Jul 3 17:27 cloudera
lrwxrwxrwx 1 root root 15 Jul 3 17:27 config -> /etc/kafka/conf
drwxr-xr-x 2 root root 12288 Jul 3 17:27 libs
-rwxr-xr-x 1 root root 32216 Jul 3 17:27 LICENSE
-rwxr-xr-x 1 root root 336 Jul 3 17:27 NOTICE
drwxr-xr-x 2 root root 4096 Jul 3 17:27 site-docs
到此kafka部署完成。
部署Spark:参考官网https://docs.cloudera.com/documentation/spark2/latest/topics/spark2_installing.html
默认add Service的spark是apache的1.6版本的spark,而我们需要部署的是spark2.x的

创建目录:
[root@hadoop001 ~]# mkdir spark_parcel
下载所需要的文件:1个json文件,2个parcel文件,1个jar包
下载地址:http://archive.cloudera.com/spark2/parcels/2.4.0.cloudera2/
上传:
[root@hadoop001 spark_parcel]# ll
total 194296
-rw-r--r-- 1 root root 5181 Apr 29 2019 manifest.json
-rw-r--r-- 1 root root 198924405 Nov 17 14:08 SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel
-rw-r--r-- 1 root root 41 Nov 17 14:06 SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha1
-rw-r--r-- 1 root root 19066 Nov 17 14:05 SPARK2_ON_YARN-2.4.0.cloudera2.jar
重命名去掉xxx.sha1中的1:
[root@hadoop001 spark_parcel]# mv SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha1 SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha
[root@hadoop001 spark_parcel]# ll
total 194296
-rw-r--r-- 1 root root 5181 Apr 29 2019 manifest.json
-rw-r--r-- 1 root root 198924405 Nov 17 14:08 SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel
-rw-r--r-- 1 root root 41 Nov 17 14:06 SPARK2-2.4.0.cloudera2-1.cdh5.13.3.p0.1041012-el7.parcel.sha
-rw-r--r-- 1 root root 19066 Nov 17 14:05 SPARK2_ON_YARN-2.4.0.cloudera2.jar
默认CDS描述服务jar包的路径在:/opt/cloudera/csd 如果需要修改这个路径,
点击cdh web的-->settings-->Custom Service Descriptors修改然后重启生效,
我们这里就用默认路径,没有的话就自己创建
[root@hadoop001 spark_parcel]# cd /opt/cloudera/csd
-bash: cd: /opt/cloudera/csd: No such file or directory
[root@hadoop001 spark_parcel]# mkdir /opt/cloudera/csd
然后将SPARK2_ON_YARN-2.4.0.cloudera2.jar 这个描述服务jar包mv到我们创建的目录下
[root@hadoop001 spark_parcel]# mv SPARK2_ON_YARN-2.4.0.cloudera2.jar /opt/cloudera/csd/
然后修改这个描述文件的所属用户,所属组为cloudera-scm:cloudera-scm,并修改其权限为644
[root@hadoop001 csd]# chown cloudera-scm:cloudera-scm SPARK2_ON_YARN-2.4.0.cloudera2.jar
[root@hadoop001 csd]# ll
total 20
-rw-r--r-- 1 cloudera-scm cloudera-scm 19066 Nov 17 14:05 SPARK2_ON_YARN-2.4.0.cloudera2.jar
[root@hadoop001 csd]# chmod 644 SPARK2_ON_YARN-2.4.0.cloudera2.jar
然后重启我们的server端:
[root@hadoop001 csd]# /opt/cloudera-manage/cm-5.16.1/etc/init.d/cloudera-scm-server restart
Stopping cloudera-scm-server: [ OK ]
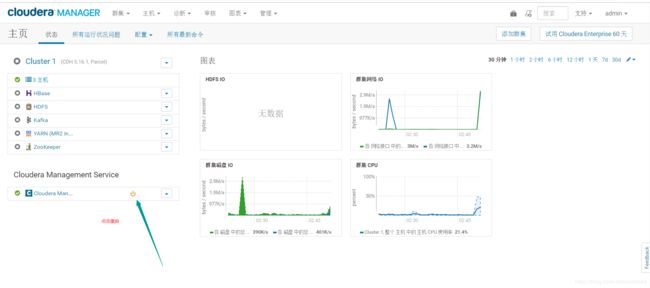
Starting cloudera-scm-server: [ OK ]
然后去cdh web页面重启Cloudera Management Service服务
然后配置spark2的http离线源:
将spark_parcel目录移动到/var/www/html 目录下
[root@hadoop001 ~]# mv spark_parcel/ /var/www/html/
启动http服务:
[root@hadoop001 html]# service httpd start
Redirecting to /bin/systemctl start httpd.service
然后就跟kafka一样可以在web以hadoop001的外网ip拼接上/spark_parcel/
访问到我们的目录了,当然配置离线源目录还是要配置内网。
然后-->点击下载-->点击分配-->点击激活 OK
去cdh的add service页面发现已经多了一个spark2

然后添加spark2:选择History Server机器
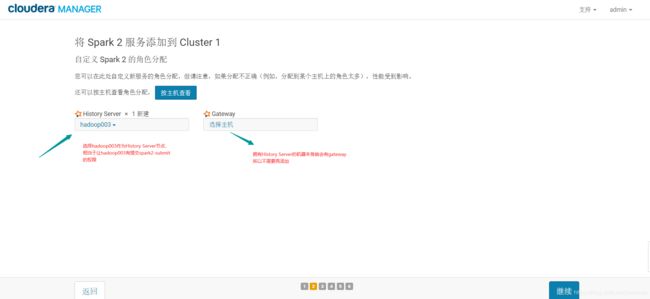
其它不做修改,点击下一步,等待启动成功
然后使用配置安全组,把18089端口打开,使用hadoop003的外网ip加上18089
即可访问history server web ui
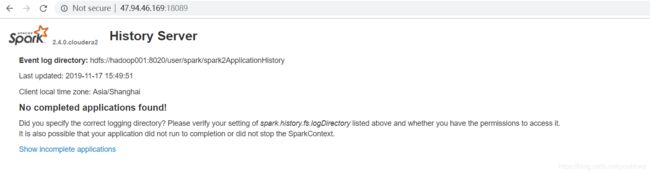
spark2安装之后的目录为:/opt/cloudera/parcels/SPARK2/lib/spark2
[root@hadoop001 spark2]# cd /opt/cloudera/parcels/SPARK2/lib/spark2
[root@hadoop001 spark2]# ll
total 128
drwxr-xr-x 2 root root 4096 Apr 24 2019 bin
drwxr-xr-x 2 root root 4096 Apr 24 2019 cloudera
lrwxrwxrwx 1 root root 16 Apr 24 2019 conf -> /etc/spark2/conf
drwxr-xr-x 5 root root 4096 Apr 24 2019 data
drwxr-xr-x 4 root root 4096 Apr 24 2019 examples
drwxr-xr-x 2 root root 12288 Apr 24 2019 jars
drwxr-xr-x 2 root root 4096 Apr 24 2019 kafka-0.10
drwxr-xr-x 2 root root 4096 Apr 24 2019 kafka-0.9
-rw-r--r-- 1 root root 21357 Apr 24 2019 LICENSE
drwxr-xr-x 2 root root 4096 Apr 24 2019 licenses
-rw-r--r-- 1 root root 42919 Apr 24 2019 NOTICE
drwxr-xr-x 7 root root 4096 Apr 24 2019 python
-rw-r--r-- 1 root root 3952 Apr 24 2019 README.md
-rw-r--r-- 1 root root 313 Apr 24 2019 RELEASE
drwxr-xr-x 2 root root 4096 Apr 24 2019 sbin
lrwxrwxrwx 1 root root 20 Apr 24 2019 work -> /var/run/spark2/work
drwxr-xr-x 2 root root 4096 Apr 24 2019 yarn
然后我们在hadoop003机器上切换到hdfs 用户,运行一下spark2自带的运行PI的测试:
[root@hadoop001 spark2]# su - hdfs
Last login: Sun Nov 17 16:02:36 CST 2019 on pts/1
这是cdh 自带的spark1.6的
[hdfs@hadoop003 ~]$ which spark-submit
/bin/spark-submit
这才是我们自己部署的spark2.x的
[hdfs@hadoop003 ~]$ which spark2-submit
/bin/spark2-submit
[hdfs@hadoop003 ~]$ spark2-submit \
> --master yarn \
> --num-executors 1 \
> --executor-cores 1 \
> --executor-memory 1G \
> --class org.apache.spark.examples.SparkPi \
19/11/17 16:15:37 ERROR spark.SparkContext: Error initializing SparkContext.
java.lang.IllegalArgumentException: Required executor memory (1024),
overhead (384 MB), and PySpark memory (0 MB) is above the max
threshold (1024 MB) of this cluster! Please check the values
of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'.
at org.apache.spark.deploy.yarn.Client.verifyClusterResources(Client.scala:365)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:177)
at org.apache.spark.scheduler.cluster.YarnClientSchedulerBackend.start(YarnClientSchedulerBackend.scala:57)
at org.apache.spark.scheduler.TaskSchedulerImpl.start(TaskSchedulerImpl.scala:185)
at org.apache.spark.SparkContext.(SparkContext.scala:501)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2520)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:935)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:926)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:926)
at org.apache.spark.examples.SparkPi$.main(SparkPi.scala:31)
at org.apache.spark.examples.SparkPi.main(SparkPi.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:497)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:849)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:167)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:195)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:924)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:933)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
然后根据错误修改yarn的配置:
默认以下配置都是1G,修改为以下值,然后重启yarn/spark2
yarn.app.mapreduce.am.resource.mb =4G
yarn.nodemanager.resource.memory-mb=8G
yarn.scheduler.maximum-allocation-mb=4G
然后再重新提交发现提交成功,控制台也已经输出了结果。
spark部署完成。