Redis常用5种数据类型的常用方法
1 NoSQL简介
1.1NoSQL数据库的四大分类如下:
1. 键值(Key-Value)存储数据库
相关产品:Redis、Tyrant
典型应用:内容缓存,主要用于处理大量数据的高访问负载
数据模型:一系列键值对
优势:快速查询
劣势:存储的数据缺少结构化
2. 列存储数据库
相关产品:HBase、Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
3. 文档行数据库
相关产品:MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型:一系列键值对
优势:数据结构要求不严格
劣势:查询性能不高,而且缺乏统一的查询语法
4. 图形(Graph)数据库
相关数据库:Neo4J
典型应用:社交网络
数据模型:图模型
优势:利用图结构相关算法
劣势:需要对整个图做计算才能得处结果,不容易做分布式的集群方案。
1.2NoSQL特点
在大数据存取上具备关系型数据库无法比拟的性能优势,例如:
1.易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。数据之间无关系,这样就非常容易扩展。也在无形之间,在架构的层面上带来了可扩展的能力。
2.大数据量,高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。这得益于它的 无关系性,数据库的结构简单。
3.灵活的数据类型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据 库里,增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个 噩梦。这点在Web2.0时代尤为明显。
4.高可用
NoSQL在不太影响性能的情况下,就可以方便地实现高可用的架构。比如HBase模型,通过 复制模型也能实现高可用。
综上所述,NoSQL的非关系特性使其成为了后Web2.0时代的宠儿,助力大型Web2.0网站的再次起飞,是一项全新的数据库革命性运动。
2. Redis
2.1Redis数据类型:
1.字符串 String
2.散列 Hash
3.列表 List
4.集合 Set
5.有续集合类型 Sorted Set
2.2后端模式启动
修改redis.conf配置文件,daemonize yes 以后端模式启动。
vim /usr/local/redis/redis.conf
启动时,指定配置文件
cd /usr/local/redis/
./bin/redis-server ./redis.conf
2.3 Redis 停止
1.强制结束程序。强行终止Redis进程可能会导致redis持久化数据丢失。
通过 ps aux|grep -I redis 查询pid 然后 kill -9 pid
2.正确停止Redis的方式应该是向Redis发送SHUTDOWN命令,方法为:
cd /usr/local/redis
./bin/redis-cli shutdown
2.4 连接客户端
在redis的安装目录中有redis的客户端,即redis-cli,他是redis自带的基于命令的redis客户端。
Redis-cli -h ip地址 -p 端口
./bin/redis-cli -h 127.0.0.1 -p 6379
默认ip和端口
./bin/redis-cli
2.5存储string
概述:字符串类型是redis中最为基础的数据存储类型,它在redis中是二进制安全的,这便意味着该类型存入和获取的数据相同。在redis中字符串类型的value最多可以容纳的数据长度是521M。
1.赋值 set key value:设定key持有指定的字符串value,如果该key存在则进行覆盖操作。总是返回”OK”
2.取值get key: 获取key的value。如果与该key关联的value不是String类型,redis将返回错误信息,因为get命令只能获取String value;如果该key不存在,返回(nil)。
3.getset key newvalue : 先获取该key的值,然后再赋值
4.删除 del key : 删除指定key
5.数值增减
-
incr key:将指定key的value原子性的递增1.如果该key不存在,其初始值为0,在incr之后其值为1.如果value的值不能转成整形,如hello,该操作将执行失败并返回相应的错误信息。
-
decr key: 将指定key的value原子性的递减1,如果该key不存在,其初始值为0,在decr之后为-1.如果value的值不能转成整形,如helo,该操作将执行失败并返回相应的错误信息。
-
6.扩展命令
-
Incrby key increment : 将指定的key 的value原子性增加increment,如果该key不存在,其初始值为0,在incrby之后,该值为increment。如果该值不能转成整形,如hello,则失败并返回错误信息
-
decrby key decrement :与 incrby key increment 相反。
-
append key value : 拼接字符串。如果该key存在,则在原有的value后追加该值;如果该key不存在,则重新创建一个key/value
2.6 存储hash
概述:redis中hash类型可以看成具有string key 和 string value的map容器。所以该类型非常适合于存储对象的信息。如username、password、age等。如果hash中包含很少的字段,那么该类型的数据也将占用很少的磁盘空间。每一个hash可以存储4294967295个键值对。
1.赋值 hset key value :为指定的key设定 field/value (键值对).
Hset myhash username jack
Hmset myhash username jack age 21 password 123
2.取值。hget key field :返回指定的key中的field的值
hget myhash username
hmget myhash username age password 获取key中多个field的值
hgetall key:获取所有键值对
3.删除。hdel key field[field…] 可以删除一个或多个字段,返回值是被删除的字段个数,返回值为0表示该字段不存在
hdel myhash username
hdel myhash username age password
del key 删除整个list
4.增加数字。hincrby key field increment : 设置key中field的值增加increment,如;age增加20
Hincrby myhash age 20
5.扩展命令
-
hexists key field :判断指定的key中的field是否存在
-
hlen key : 获取key所包含的field的数量
-
hkeys key : 获取所有的key
-
hvals key :获取所有的value
2.7存储list
概述:在redis中,list类型是按照插入顺序排序的字符串链表。和数据结构中的普通链表一样,我们可以在其头部和尾部添加新的元素。在插入时,如果该键并不存在,redis将为该键创建一个新的链表。与此相反,如果链表中所有的元素均被移除,那么该键也将会被从数据库中删除。list中可以包含的最大元素数量是4294967295。
从元素插入和删除的效率角度来看,如果我们是在链表的两头插入或删除元素,这将会是非常高效的操作,即使链表中已经存储了百万条记录,该操作也可以在常量时间内完成。然而需要说明的是,如果插入或删除操作是用于链表中间,那将会是非常低效的。
1.两端添加: lpush key values[value1 value2…] 在指定的key所关联的list的头部插入所有的values,如果该key不存在,该命令在插入之前创建一个与该key关联的空链表,之后再向链表的头部插入数据。插入成功,返回元素的个数。 Lpush mylist a b c 插入 a、b、c。顺序为 c,b,a
rpush mylist 1 2 3
此时mylist中元素顺序为:c b a 1 2 3
2.查看列表 lrange key start end :获取链表中从start 到 end 的元素的值,start、end从0开始计数;也可以为负数,-1表示链表的尾部,-2表示倒数第二个,以此类推
3.两端弹出。lpop key:返回并弹出指定的key关联的链表中的第一个元素,即头部元素。如果该key不存在,返回nil;若key存在,则返回链表的头部元素。
lpop mylist 弹出头部的第一个元素,c
rpop mylist 弹出尾部的第一个元素,3
4.获取列表中元素的个数 llen key: 返回指定的key关联的链表中的元素的数量
5.扩展命令
-
lpushx key value 当且仅当参数中指定的key存在时,向关联的list的头部插入value。如果不存在,将不进行插入。
-
rpushx key value 向尾部添加元素
-
lrem key count value : 删除count 个 值为value 的元素,如果count 大于0,从头向尾遍历并删除count个值为value的元素,如果count小于0,则从尾向头遍历并删除。如果count等于0,则删除链表中所有值等于value的元素。
-
lset key index value : 设置链表中的index 的脚标的元素值,0代表链表的头元素,-1代表链表的尾元素 。脚标不存在则抛异常。
-
linsert key before | after pivot value : 在pivot元素前或者后插入value这个元素。 linsert mylist before b 11。 在b前插入11
-
rpoplpush resource destination : 将链表中的尾部元素弹出并添加到头部。【循环操作】
2.7存储set
概述:在redis中,我们可以将set类型看作为没有排序的字符集合,和list类型一样,我们也可以在该类型的数据值上执行添加、删除或判断某一元素是否存在等操作。需要说明的是,这些操作的时间复杂度为O(1),即常量时间内完成次操作。set可包含的最大元素数量是4294967295。
和list类型不同的是,set集合中不允许出现重复的元素,这一点和
C++标准库中的set容器是完全相同的。换句话说,如果多次添加相同元素,Set中将仅保留该元素的一份拷贝。和list类型相比,set类型在功能上还存在着一个非常重要的特性,即在服务器端完成多个set之间的聚合计算操作,如union、intersections 和 differences。由于这些操作均在服务器端完成,因此效率极高,而且也节省了大量的网络IO开销。
1.添加/删除元素
sadd key values[value1,value2…] : 向set中添加数据,如果该key的值已有则不会重复添加
srem key members[member1,members…] : 删除set中指定的成员
2.获得集合中的元素
smembers key : 获取set中所有的成员
sismember key member : 判断参数中指定的成员是否在该set中,1表示存在,0表示不存在或者该key本身就不存在。(无论集合中有多少元素都可以极速的返回结果)
3.集合的差集运算 A-B
sdiff key1 key2 … : 返回key1与key2中相差的成员,而且与key的顺序有关。即返回差集。
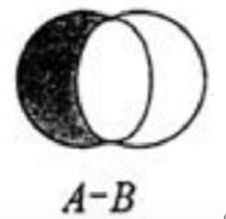 属于key1并且不属于key2的元素构成的集合
属于key1并且不属于key2的元素构成的集合
4.集合的交集运算 A![]() B
B
sinter key1 key2 key3….:返回交集

5.集合的并集运算AUB
sunion key1 key2 … :返回并集。

6.扩展命令
scard key : 获取key中成员的数量
srandmember key :随机返回set中一个成员
sdiffstore destination key1 key2…:将key1、key2相差的成员存储在destination上
sinterstore destination key1 key2…: 将key1、key2的交集存储在destination上
sunionstore destination key1 key2…: 将key1、key2的并集存储在destination上
2.8存储sortedset
概述:sorted-set 和 set类型极为相似,它们都是字符串的集合,都不允许重复的成员出现在一个set中。它们之间的主要差别是sorted-set中每一个成员都会有一个分数(score)与之关联,redis正是通过分数来为集合中的成员进行从小到大的排序。然而需要额外指出的是,尽管sorted-set 中的成员必须是唯一的,但是分数(score)却是可以重复的。
在sorted-set中添加、删除或更新一个成员都是非常快速的操作,其时间复杂度为集合中成员数量的对数。由于sorted-set中的成员在集合中的位置是有序的,因此,即便是访问位于集合中部的成员也仍然是非常高效的。事实上,redis所具有的这一特征在很多其它类型的数据库中是很难实现的,换句话说,在该点上想要达到和redis同样的高效,在其它数据库中进行建模是非常困难的。
1.添加元素 zadd key score member score2 memeber2…:将所有成员以及该成员的分数存放到sorted-set中。如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素。
2.获得元素 zscore key member :返回指定成员的分数
3.zcard key :获取集合中的成员数量
4.删除元素 zrem key member1 member2 … 移除集合中指定的成员,可以指定多个成员。
5.范围查询 zrange key start end [withscores] :获取集合中脚标为start-end的成员,[withscores]参数表明返回的成员包含其分数,不加也可以
6.zrevrange key start stop [withscores] :按照元素分数从大到小的顺序返回索引 从 start 到 stop之间的所有元素(包含两端)
7.zremrangebyrank key start stop :按照分数排名范围删除元素
8.zremrangebyscore key min max :按照分数范围删除元素
9.扩展命令
-
zrangebyscore key min max [withscores] [limit offset count] : 返回分数在[min,max]的成员并按照分数从低到高排序。 [withscores] :显示分数; [limit offset count] : offset,表明从脚标为offset的元素开始并返回count个成员。
-
zincrby key increment member : 设置指定成员的增加的分数。返回值是更改后的分数。
-
zcount key min max : 获取分数在[min,max]之间的成员的个数
-
zrank key member : 返回成员在集合中的排名。(从小到大)
-
zrevrank key member :返回成员在集合中的排名。(从大到小)
3. Keys 的通用操作
-
keys pattern : 获取所有与pattern匹配的key,* 表示任意一个或多个字符,?表示任意一个字符
-
del key1 key2… : 删除指定的key
-
exists key : 判断该key是否存在,1代表存在,0代表不存在
-
rename key newkey : 为当前的key重命名
-
expire key :设置过期时间,单位:秒
-
ttl key : 获取该key所剩的超时时间,如果没有设置超时,返回-1.如果返回-2表示超时不存在。
-
type key : 获取指定key的类型。 该命令将以字符串的格式返回。 返回的字符串为String、list、set、hash和zset,如果key不存在返回null。