Linux(CentOS7)下Hadoop的安装与使用
一、安装文件准备
这里我使用的是hadoop-2.6.0.tar.gz这个版本,可以直接到下面网盘里下载使用
链接: https://pan.baidu.com/s/1tj26EGUBnpTZnbA0qkb77Q 提取码: sepa
二、修改主机名为master
2.1 这里为了后面使用方便,先将主机名改为master:
vim /etc/hostname
2.2 修改hosts文件,下面加一行master的配置
vim /etc/hosts

2.3 使配置生效
hostname mastersu root
2.4 设置免密性
ssh-keygen -s -t rsa然后一路回车,再执行下面这个命令:
ssh-copy-id master根据提示,输入“yes”,再输入用户的密码。最后执行下面这个命令:
ssh master三、安装hadoop
3.1 解压Hadoop
首先使用xftp等类似工具把hadoop-2.6.0.tar.gz文件传到主机,解压文件
tar -axvf hadoop-2.6.0.tar.gz 然后移动到/usr/local下:
mv hadoop-2.6.0 /usr/local/hadoop3.2 配置hadoop-env.sh文件
首先进入进入/usr/local/hadoop/etc/hadoop/ 路径下:
cd /usr/local/hadoop/etc/hadoop/ 这里主要把jdk路径配置上,下图25行(jdk请自行安装),然后注释掉31行
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64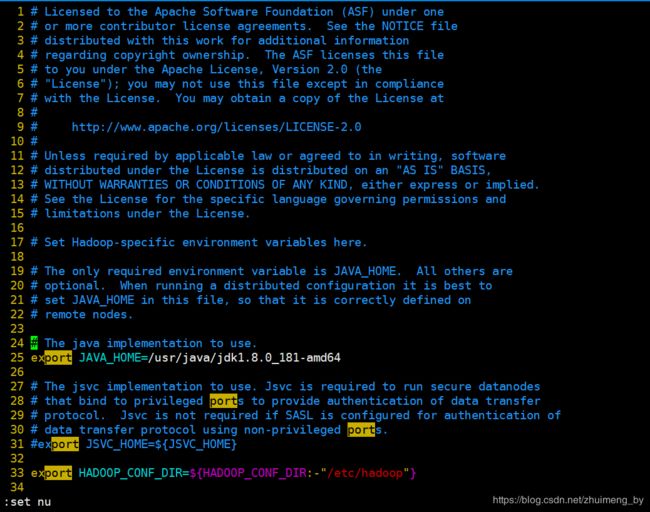
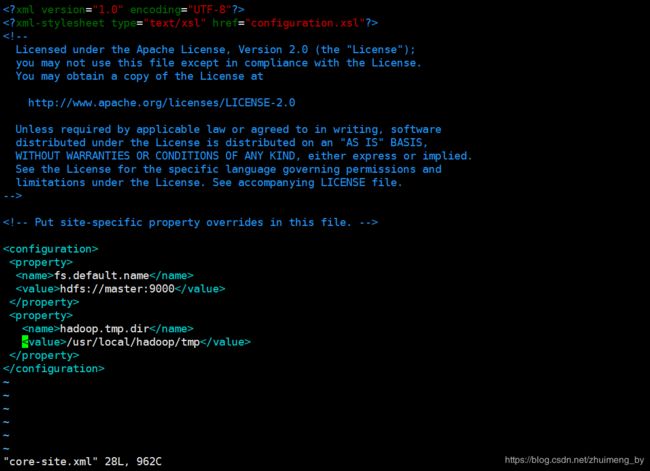
3.3 配置core-site.xml文件
fs.default.name
hdfs://master:9000
hadoop.tmp.dir
/usr/local/hadoop/tmp
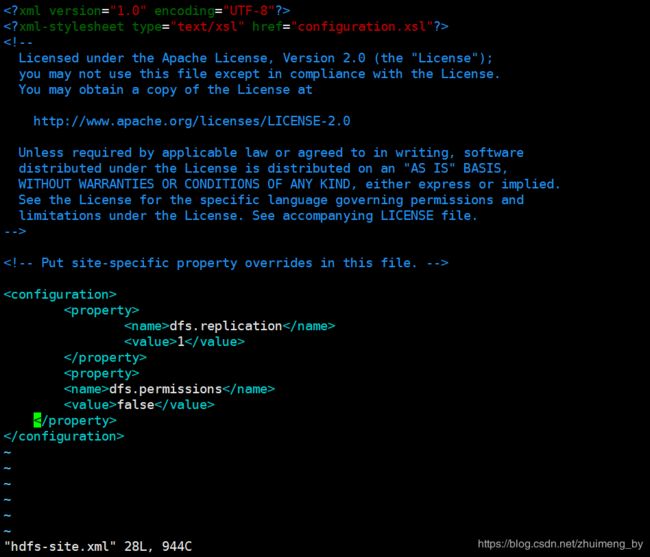
3.4 配置hdfs-site.xml文件
dfs.replication
1
dfs.permissions
false
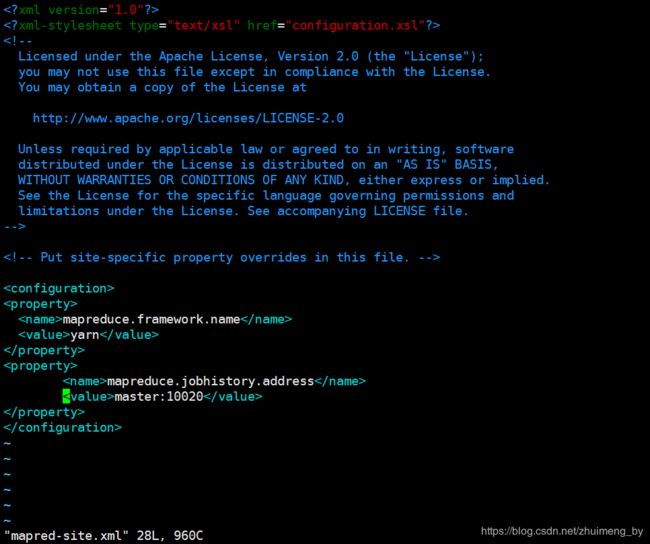
3.5 配置mapred-site.xml文件
首先复制mapred-site.xml.template文件得到mapred-site.xml
cp mapred-site.xml.template mapred-site.xml然后配置mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
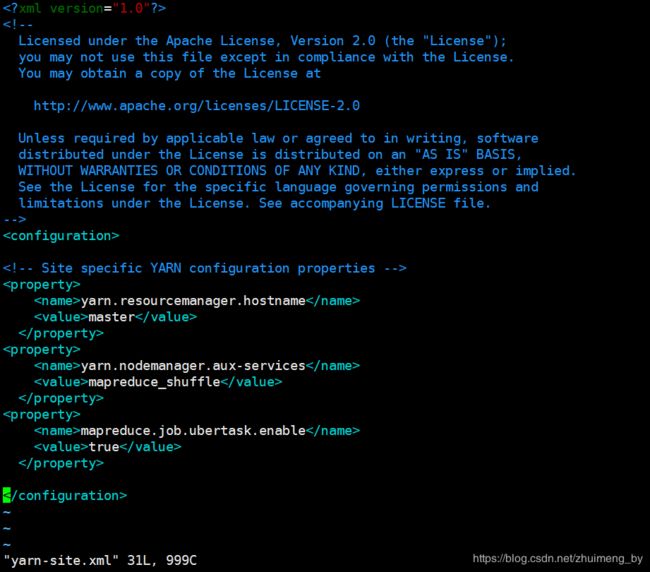
3.6 配置yarn-site.xml文件
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
mapreduce.job.ubertask.enable
true
3.7 配置环境变量
vim /etc/profileexport HADOOP_HOME=/usr/local/hadoop
export PATH=.:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH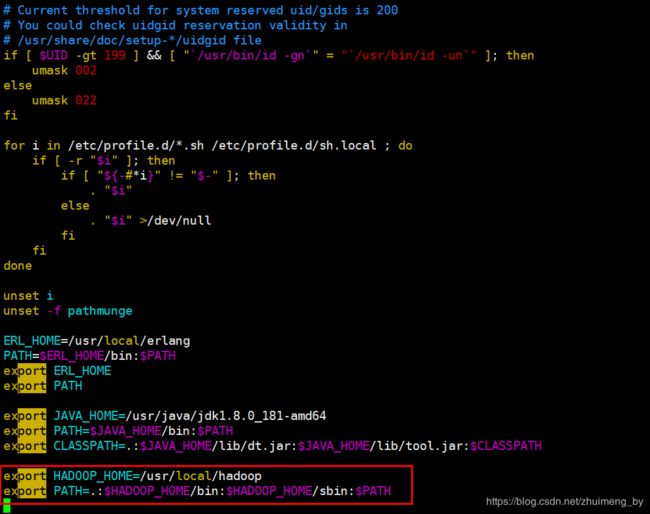
使环境变量生效
source /etc/profile3.8 格式化一下hadoop
hadoop namenode -format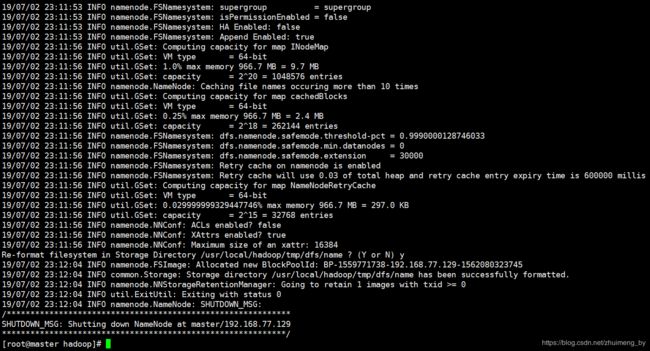
出现上图,表示执行成功,至此hadoop已安装完成。
四、Hadoop的启动与关闭
4.1 启动Hadoop
start-dfs.sh
start-yarn.sh或者直接
./start-all.sh 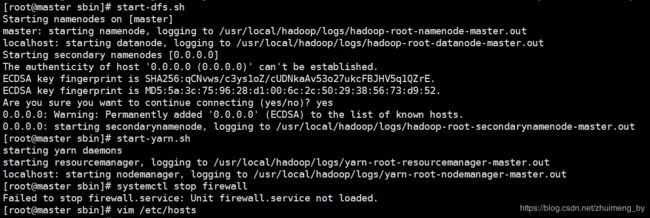
出现上图表示启动成功,可以浏览器验证下:
http://192.168.77.129:50070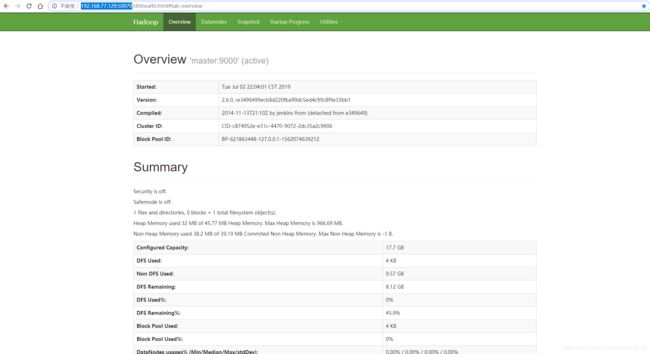
http://192.168.77.129:8088
4.2 关闭Hadoop
./stop-all.sh
注意:
1、如果页面不能正常访问,检查是否开启了防火墙而没有放开50070和8088端口
关于防火墙放开端口操作参考我的一篇博客:Linux(CentOS7) 关闭防火墙、放开端口以及关闭Selinux
2、JDK安装可以参考我的另一篇博客: CentOS7.4 安装 JDK(npm 方式安装)