边缘计算体验之二:简单高可用 ZStack Mini的巧妙设计
在上篇文章中,我们介绍了ZStack Mini产品具有的“4S”特性中的“3S”,即简单(Simple)、可扩展(Scalable)和智能(Smart),本文的主角是另外一个“S(健壮,Strong)”。
不管是中文的“健壮”,还是英文的“Strong”,通常用于形容人或动物的体格,并隐含拥有更高的生存能力,或者说在受伤失去部分生理机能后,拥有更快恢复正常的能力。
正是因为这一词潜在的含义,也被借用以描述IT系统或应用程序的特点之一,比如应用程序/IT系统的健壮性,在遭遇bug或硬件故障的情况下,不会彻底“失能”,而是可以继续工作并更快恢复常态。
IT系统的健壮性可以用“RAS”来说明,即可靠性(Reliability)、可用性(Availability)和可维护性(Serviceability)。简单来说,可靠性意味着组成IT系统的各组件品质过关,不易故障,即使某一个或多个组件发生故障,也不影响应用程序的正常运行(可用性);并且在组件或系统故障时,其可即时启用替换机制,使得故障组件/系统快速恢复正常(可维护性)。
可以看出,可靠性和可维护性设计在一定程度上是服从可用性设计的,其目的是为了提高可用性,满足业务连续运行(而尽可能不被中断)的需求。
IT系统可用性通常用几个“9”来衡量,如5个9、6个9,指的是系统可用时间的百分比,相对应的是以年为单位计算(允许的)停机时间。
试举两例:1个9即90%的可用性,每年允许的停机时间不超过36.5天;5个9即99.999%的可用性,每年的停机时间不能超过5分半钟。
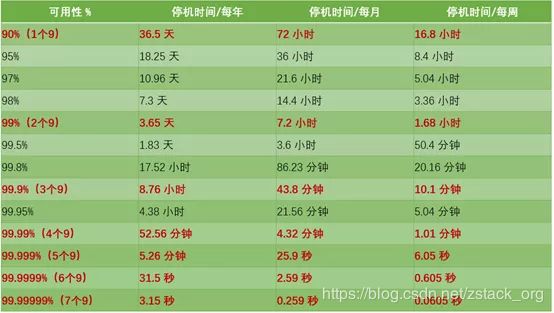
图注:E企研究院整理的可用性与(允许)停机时间对照表,可用性每多一个9,单位时间内允许的停机时间下降到十分之一:譬如,可用性为4个9(99.99%)每年允许的停机时间接近53分钟,而5个9每年允许的停机时间则下降到5分半钟以内
我们知道,由于开机自检等过程耗时较长,服务器重启一次的时间可能超过5分钟,这意味着每年服务器只要宕机一次,哪怕立刻恢复,5个9的可用性就保不住了。然而,硬件的单点失效(Single Point OfFailure,SPOF)是不可能彻底避免的,再加之有时软件系统出的故障最终也要通过服务器重启来解决,所以“2N”系统就成为保障高可用性的常见思路。
譬如,两套一样的系统,运行一样的应用,访问一样的数据,平时一主一备(Active-Passive),主系统出故障之后备份系统接管,由于后者一直在运行着,不需要经历一遍耗时的软硬件启动工作,理论上服务中断的时间只取决于主备之间的切换速度,不要说5个9,就是6个9或者7个9,也是可以实现的。
理论很简单,实现很复杂,包括如何保证两套系统的数据和(应用)状态尽可能一致,以便快速切换?
传统计算与存储分离的架构,最少需要两台服务器连接到一套双控的存储系统上,两台服务器之间同步应用,数据的高可用由双控制器的存储系统负责,后者使用的存储介质通常具备双端口功能(如FC或SAS硬盘),数据访问的控制权在必要时(如其中一个控制器故障)切换。相应的,网络子系统通常也是双冗余设置,整套解决方案的构成很是复杂。双端口硬盘减少了数据同步的工作量,但其本身又经常被划归专用设备的范畴,不符合标准化硬件结合“软件定义”的潮流。
超融合架构(Hyper-Converged Infrastructure,HCI)则通过在工业标准服务器中采用软件定义存储的方式,实现了计算与存储两大角色的统一,提高了扩展的灵活性,降低了部署和运维的复杂性。不过,大多数超融合系统的分布式软件定义存储都采用三副本机制来避免数据丢失,加上可维护性的考虑,这些超融合系统通常从三节点或四节点起步,无形中又提升了用户采购的门槛。
也就是说,在不考虑网络设备的情况下,不管是计算与存储分离,还是计算与存储一体,上述两种小规模部署中常见的高可用架构,设备或者说节点的数量都不少于3台——譬如超融合系统较为常用的2U4节点服务器,我们按照4台服务器计算。
从架构的层面看,ZStack Mini兼具两种架构的部分特性:一方面,它是计算与存储一体的超融合;另一方面,其每个节点内部的存储子系统又基于传统存储系统常用的RAID技术。
有趣的是,通过这一组合,ZStack Mini最少只需要2台服务器,即一台2U2节点服务器——虽然都是2U多节点,2U2的成本可以比2U4低很多,从而显著降低用户的接受难度。
那么,在(最小)只有2个节点的情况下,ZStack Mini是如何保证数据和应用的高可用的呢?其存储空间利用率又如何呢?请看我们下面的解析。
极简架构有助于提升可靠性
可靠性是可用性的组成部分之一。能够长期稳定运行的可靠组件有助于系统的整体可用性,但“可靠”又受成本约束,“高成本的高可用”系统并非没有实际意义,但门槛太高。
鉴于ZStack Mini传承自ZStack云引擎,同时其产品形态(2U2节点)与2U4节点形态的超融合产品有一定的相似,比如2U机箱、双冗余电源、几乎相同的占地空间,而且两者都可以2U为最小部署单元(超融合的3节点或4节点都用2U4),但是只有2个节点的ZStack Mini在架构上无疑更为简单。

图上为ZStack Mini,2U机箱内置两个服务器节点;图下为较为主流的2U4节点设计的超融合一体机。从硬件数量来看,显然2U4节点的超融合比2U2节点的ZStack Mini组件数量多得多,而且空间设计也更紧凑,每个节点面临的扩展性和散热等挑战更大
不管是ZStack Mini还是2U4节点的超融合一体机产品,内部都有多种IT硬件,每种乃至每个硬件都有故障率。以ZStack Mini中大量使用的西部数据Ultrastar DC HC310(4TB)硬盘为例,其年故障率为0.44%,系统内所使用的硬件越多,其故障的风险自然越大。
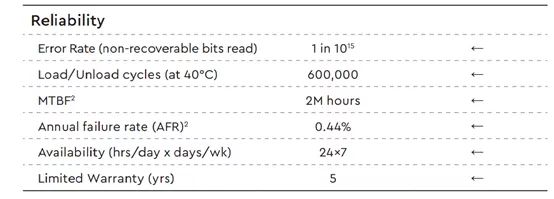
西部数据官网公布的Ultrastar DC HC310系列硬盘的可用性,上图中Annual failurerate(AFR)即为硬盘的年故障率(0.44%);上图中的MTBF则表示平均故障间隔时间,为2百万小时
与硬盘紧密相连的组件是SATA/SAS RAID卡,ZStack Mini使用了Broadcom公司推出的带锂电池备份单元(Battery Backup Unit,BBU)的RAID卡,在遭遇突发停机的情况下,可以将RIAD卡Cache中的数据存储到硬盘。

ZStack Mini内置的2节点内部,毗邻CPU散热片,贴有白底标签纸的组件即为锂电池,其与紧贴机箱壁的RAID卡相连,在突发掉电情况下为RAID卡供电,有助于降低数据丢失风险
从上图也可以看出,ZStack Mini中所采用的半宽2U节点,其内部空间还是比较宽裕的,相比于2U4中的半宽1U节点,散热条件更好,有利于升级到更高规格的CPU,而且工作温度也是影响系统可靠性的一大重要因素,尤其是部署在边缘站点或小微企业内部的产品,其运行环境通常比专业数据中心复杂得多
每一个组件都有故障率,每一个组件的故障都会影响系统的可靠性,进而影响可用性。故障并不可怕,重要的是组件故障后,如何保障用户的数据不丢失,甚至能够让应用持续运行,继续可用,这是在系统或解决方案设计时最重要的目标之一。
除了应用的可用性,还要考虑数据的可用性,并且避免存储子系统的故障导致数据丢失。据ZStack介绍,ZStack Mini通过两副本加两纠删码的双重保险保障数据安全,只有在至少两个节点各两块硬盘同时损坏的场景下才有数据丢失的风险,整体数据可用率高达99.999995%,比通常超融合双副本安全系数高4个9,比三副本安全系数高2个9,这又是怎么做到的呢?
节点内:N+1应对磁盘故障
硬盘是ZStack Mini中的数据存储担当,其前面板上插满了12块3.5英寸硬盘,平均分给2个节点使用。其中4块(每节点各2)用于安装操作系统,其余8块(每节点各4)留给用户存储数据。
当下,大多数超融合一体机中采用了三副本数据保护机制,将同一份数据分别存放在三台不同的服务器内,从而在遭遇单个硬盘或节点故障后,数据仍然可正常读写。
ZStack Mini则颇为“非主流”的采用了基于硬件(RAID卡)的RAID技术,其中操作系统盘用RAID 1(镜像)保护,每节点的4个数据盘用RAID 5(奇偶校验)保护。
RAID技术与RISC技术诞生于同一时代,而且还师出同人,然而,RISC-V目下正是计算领域的当红炸子鸡,RAID却已不大有人提起。其中一个很重要的原因在于,传统基于硬件的RAID技术不适合大规模部署环境,在使用大容量硬盘的时候恢复时间也面临很大的挑战。
不过,RAID的核心理论和算法并没有过时,譬如在大规模部署环境中为解决副本技术存储容量利用率偏低而采用的纠删码(Erasure Code)技术,其核心算法原理与RAID 5/6是相通的,我们可以将RAID 5视为N+1的纠删码。
而在小规模部署环境中,譬如ZStack Mini这种每个节点只有个位数硬盘的情况下,RAID技术仍然能够发挥很好的作用,RAID卡还可以把CPU从底层存储任务处理中解放出来,贡献更多的虚拟机。
理论基础有了,接下来我们就通过在实际应用运行场景下直接拔盘的手段来验证ZStack Mini节点是否还能正常工作,以下视频为验证过程:
视频解读:在初始化好的ZStack Mini中,E企研究院创建了一个Windows 10(试用版)操作系统的虚机,然后安装Adobe PremierePro CS6(试用版)软件,这是Windows平台下主流的视频剪辑软件。
我们将几个视频片段导入到Premiere中,剪辑拼合成一个视频,利用Premiere对这个剪辑后的视频进行渲染。在渲染过程中(大约渲染了三分之一进度之后),我们直接拔掉了此虚机所在物理节点上的一块用于数据存储的硬盘(4TB)。但Premiere的渲染任务并没有停顿,正常完成。但在ZStack Mini的管理后台,监控中显示Windows 10虚机所在物理节点出现硬盘故障,性能和可用性“降级”。这意味着数据没有丢失,应用仍可正常运行,但存在潜在风险:如果此时节点内再有一块硬盘发生故障,将导致数据丢失——当然,在下一节我们会看到,另一个节点不会允许这种事情发生。
当我们将被拔出的硬盘重新插入硬盘仓(相当于用新盘替换故障盘),ZStack Mini识别到健康盘已插入,并开始自动重建。

图注:拔出后的硬盘重新插入,ZStack Mini自动进行数据重建,在管理后台对应的监控界面中,可以看到“重建中”状态标志,性能监视界面也显示目前有持续的IO读写活动;直到数据“重建”完成前,RAID健康状态都将处于“降级”状态
通过上述模拟场景的测试验证,ZStack Mini任意节点确实能够有效地抵御单块数据存储盘故障,不会导致数据丢失或应用停顿,应用虚机仍旧无感知地继续当前任务,直至完成或人工干预。
节点间:2N保障应用高可用
节点内的RAID技术保证了任一磁盘故障都不会对应用造成影响,但是传统基于硬件的RAID技术(更换硬盘后)重建数据的时间比较长——根据硬盘容量的不同,几个小时不等——在此期间,如果再有一个硬盘坏掉,数据就会丢失,应用也会中断。此外,CPU、内存、网卡等部件没有冗余,出现故障也可能导致停机……凡此种种,都是ZStack Mini的另一个节点发挥作用的时候,我们不妨称之为节点级副本。

图上为ZStack Mini正面,布满了3.5英寸硬盘,支持热插拔。图下为背部,几乎所有组件都位于节点内部,这意味着更换除硬盘外的任一组件都需要停机
正所谓“养兵千日,用兵一时”,当一个节点不能正常工作的时候,另一个节点就要揣着一直在同步的数据和状态“挺身而出”了,这就是我们通常所说的(节点级)高可用。为了验证这一特性,我们将应用虚机设置为“高可用”之后,通过将其所在节点突然断电的手段,验证应用是否能够继续运行。
视频解读:ZStack Mini中的节点1因为上一个测试中拔掉其中一块硬盘,正处于“重建”状态,在这测试中,E企研究院模拟这一“故障”节点突发断电,以验证ZStack Mini的高可用功能。
在节点1上有4个虚机,其中“渲染服务器”、“转码服务器”和“网管平台”设置为高可用,作为对比,另一个名为“CentOS7.2”的虚机则不使用高可用功能。在转码服务器中,E企研究院将上一测试渲染好的视频导出,并使用XCoder软件进行转码。
在转码过程中(大约已完成三分之一的转码进度时),不经过任何操作,直接关闭节点1电源,以模拟突发掉电。在节点1断电后,ZStack Mini提示节点1失联,并报告“网管平台”失联。随后,ZStack Mini启动“高可用”进程,开始迁移开启了“高可用”功能的应用虚机,大约1分钟后,原来位于节点1上,并开启了“高可用”功能的虚机在节点2上重启。
“转码服务器”重启之后,XCoder之前的任务进度清零,并自动重新开始任务。我们经过测试证明,当ZStack Mini上任一节点掉电后,其上开启了“高可用”功能的虚机将自动迁移到另一正常运行节点。
通过上述的两阶段验证,可以看出,不管是在硬盘组件故障,还是节点级故障,ZStack Mini都具有良好的可用性,应用能够无间断或经历短暂停顿后继续运行,不会造成数据丢失。
计算存储:效率和数据持久性
在使用这套ZStack Mini的过程中,我们与一些对此产品有兴趣的潜在用户进行了沟通,发现有一个很有代表性的问题:两个节点一主一备,可用性是保证了,但是硬件的利用率岂不是只有一半?会不会很浪费?
这个问题可以从计算和存储资源两个层面来看。
从应用的层面来说,如前面的测试环节中所提到的,应用所在的虚机,“高可用”功能是可选的,也就是说只有开启这一功能,虚机才会同时占用两个节点的计算资源,这也是为了保证应用持续运行所必须付出的代价。
如果某个应用对可用性的要求没有那么高,就可不开启“高可用”,也就省去了不必要的浪费。
从存储的层面来说,ZStack Mini所有的用户数据都在两个节点上镜像存储,这样即使一个节点完全损坏,数据也不至于丢失。从数据盘的存储利用率来看,节点间是1+1(镜像),节点内是3+1(4个盘的RAID 5),所以总体效率是0.5×0.75=0.375,即不到一半的水平。
看起来不高是么?作为对比,三副本的超融合系统,存储利用率为三分之一,即0.333——如此看来,ZStack Mini还略占优势呢。
ZStack方面也对Mini在数据持久性上的优势进行了解释:
双副本数据持久性失效的概率等于分布在不同计算节点的任意两个盘同时损坏的概率,按照 Google的磁盘年损坏率数据1.7%(高于硬盘厂商公布的指标)算的话,那就是1.7%×1.7%×(1/2)=0.01445%,数据持久性为98.56%,接近2个9;
双副本+RAID5数据持久性失效的概率等于分布在不同计算节点上任意四个盘同时损坏的概率,并且必须是一边2个,而不能是一边4个或者一边3个,那就是1- 1.7%×1.7%×1.7%×1.7%×(18/31) =99.999995%,即高于7个9(18/31是8块硬盘同时坏4块而且在两个节点各2个的概率);
而三副本只要任意3块盘损坏就丢数据,3副本的可用性概率是1-1.7%×1.7%×1.7% =99.99951%,即高于5个9。
展望3.0:提升可维护性,助力整体可用性
可维护性是一个笼统的说法,但其又体现在产品设计的每一个细节。
比如说,现代x86服务器大多具有(驱动器)热插拔、免工具拆装的特点,这实际上是在硬件层面体现了可维护性。不借助工具,徒手即可对故障组件进行更换,缩短维护时间,自然有助于可用性(毕竟可用性也是可以用停机时间来衡量的)。
同时在软件方面,具体到ZStack Mini来说,在初始化环节就节省了大量的时间,同时很多功能都是通过鼠标点击,然后多个关联流程在后台静默完成,这也是可维护性的体现:尽量减少人工操作,避免人为误操作。
当然这些还远远不够。在谈到ZStack Mini的未来发展时,ZStack介绍了即将推出的ZStack Mini 3.0产品,其将新增多个重大功能:
1 备份功能
目前的2.0版本经过设置也可实现备份,但3.0版本将正式推出外接磁盘备份功能,可对系统进行定期备份,并可使用这些备份在新机器上恢复。未来,其还将支持备份到云端功能,让数据彻底高枕无忧。
2 改进则与应用高可用相关。
在我们验证“节点故障”的时候,尽管应用虚机设置了高可用,但当节点故障后,应用虚机仍需经过短暂停顿才恢复服务。而在新的3.0版本中,在遭遇节点故障的情况下,将实现无间断切换,用户感觉不到应用虚机的停顿。
3 在ZStack Mini中集成应用中心
目前ZStack Mini 2.0平台部署好以后,用户需要手动创建虚机,并安装应用程序。这对于大多数小型企业或边缘站点而言,一是比较复杂,二是耗时。但在3.0中,ZStack将与各个ISV合作,根据不同行业的应用特点,直接将应用模板集成到应用中心,用户只需下载即可进行部署,省却了应用安装过程中的复杂配置,同时在升级、维护方面也更有保障,极大地提高了可维护性。