Python 学习归纳
Python 知识归纳
- 一. Anaconda 方面
- Windows 系统
- 1. 虚拟环境的相关操作
- 二、基本知识
- 三、拓展库
- 1. threading 库 (多进程、多线程)
- 基础学习
- 相关知识
- 线程和进程的优缺点
- 2. numpy 库 (矩阵)
- 基础用法
- 进阶用法
- 3. re 库 (正则表达式)
- 3.1入门
- 3.1.1 正则匹配函数
- 3.1.2 基础正则表达式--字符组
- 3.1.3 快捷方式与快捷方式取反
- 3.1.4 基础正则表达式--区间与区间取反
- 3.1.5 字符串的开始与结束
- 3.1.6 任意字符
- 3.1.7 可选字符
- 3.1.8 重复区间
- 3.1.9 开闭区间与速写
- 3.2 替换
- 3.3 分组
- 3.3 标记
- 3.4 编译
- 3.5 断言
- 3.6 特殊字符
- 3.7 实际应用
- 3.7.1 组合密码匹配
- 四、应用方面
- 网络爬虫
- 1. 利用URL获取超文本文件并保存至本地
- 2. 实现子链接的提取
- 3. 网页内容解析
一. Anaconda 方面
Windows 系统
1. 虚拟环境的相关操作
-
安装conda:在Windows系统下,只需要安装Anaconda,就可以直接实现conda功能。(note:Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。因为其包含了大量的科学包,所以可以带来许多的便利,其中的Conda也堪称包管理神器。)
-
更换conda下载源:
# 以下为清华源channels
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
# note:还可以在 C:\Users\24096\目录下,新建文件pip\pip.ini,
# 并且里面存放内容: [global]
# index-url = https://pypi.tuna.tsinghua.edu.cn/simple
conda config --set show_channel_urls yes
# 设置搜索时显示通道地址
- 查看虚拟环境信息:
conda info -e
conda env list
conda info --envs #使用详细参数查看
- 创建新的环境变量:
conda create -n (name_virenv) (pillow numpy) python=(2.7.14)
python -m venv (name_virenv)
# name参数指定此虚拟环境名字,同时可添加需要安装的库
- 更换所需虚拟环境:
# 激活对应虚拟环境
activate (name_virenv) eg: 切换为基础环境可直接:activate root
# 退出当前虚拟环境
deactivate
- 删除已有环境:
conda remove -n (name_virenv)--all
- 通过conda命令安装库:
conda install (name_library)
- 查看当前环境下所安装的库:
pip list
- 通过pip命令安装库:
pip install (name_library)
- 通过pip命令卸载库:
pip uninstall (name_library)
- 更新pip命令:
python -m pip install --upgrade pip
二、基本知识
- 字符串
- 字符串拼接可以使用“+”实现;也可以直接用"""来实现多行的拼接。
- 内置方法
- type(object)
三、拓展库
1. threading 库 (多进程、多线程)
基础学习
-
Python多线程学习视频:https://www.bilibili.com/video/av16944429(莫烦教程)
-
Python多进程学习视频:https://www.bilibili.com/video/av16944405(莫烦教程)
建议学习的时候跟着敲一下代码,记忆会更深刻
相关知识
线程和进程的优缺点
多进程:
- 多进程优点:
-
每个进程互相独立,不影响主程序的稳定性,子进程崩溃没关系;
-
通过增加 CPU,就很容易扩充性能;
-
可以尽量减少线程加锁/解锁的影响,极大提高性能,就算是线程运行的模块算法效率低也没关系;
-
每个子进程都有 2GB 地址空间和相关资源,总体能够达到的性能上限非常大。
- 多进程缺点:
-
逻辑控制复杂,需要和主程序交互;
-
需要跨进程边界,如果有大量数据需要传送,就不太好,适合少量数据传送、密集运算,多进程调度开销比较大;
-
最好是多进程和多线程结合,即根据实际的需要,每个 CPU 开启一个子进程,这个子进程开启多线程,可以为若干同类型的数据进行处理。当然你也可以利用多线程 + 多 CPU + 轮询方式来解决问题……;
-
方法和手段是多样的,关键是自己看起来,实现方便又能够满足要求,代价也合适。
多线程:
- 多线程的优点:
-
无需跨进程边界;
-
程序逻辑和控制方式简单;
-
所有线程可以直接共享内存和变量等;
-
线程方式消耗的总资源比进程方式好。
- 多线程缺点:
-
每个线程与主程序共用地址空间,受限于 2GB 地址空间;
-
线程之间的同步和加锁控制比较麻烦;
-
一个线程的崩溃可能影响到整个程序的稳定性;
-
到达一定的线程数程度后,即使再增加 CPU 也无法提高性能,例如 Windows Server 2003,大约是 1500 个左右的线程数就快到极限了(线程堆栈设定为 1M ),如果设定线程堆栈为 2M ,还达不到 1500 个线程总数;
-
线程能够提高的总性能有限,而且线程多了之后,线程本身的调度也是一个麻烦事儿,需要消耗较多的 CPU。
2. numpy 库 (矩阵)
基础用法
- Numpy 创建数组
import numpy as np
# arange方法 创建一维数组
a = np.arange(n) # 指将数值0 1 2 3 ~ n赋值给 a 这个变量
# array方法 创建二维数组
b = np.array([np.arange(m),np.arange(n)]) # 将两个一维数组组合成一个1*m和1*n的二维数组
# array方法 创建二维数组
x = [y for y in range(n)]
b = np.array([x]*m) # 会创建一个m*n的数组
c = np.array([np.arange(n)] * m) # 会创建一个m*n的数组
# tip: m为行,n为列
# 多维矩阵的创建方法类似
#TODO(以上均为规律矩阵的创建)
Notice: numpy创建的数组可以直接复制。
- Numpy数组 的基本运算
Relevant Knowledge:Numpy库可以直接进行一些基本的四则运算,从而快速的处理两个Numpy数组,such as:
- 向量与向量之间
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[4,5,6],[1,2,3]])
# 1. 加法
>>> np.add(a, b) # 或者 a+b
''' Out:array([[5, 7, 9],
[5, 7, 9]]) '''
# 2. 减法
>>> np.subt(a, b)
>>> np.fract(a, b) # 或者 a-b
''' Out:array([[-3, -3, -3],
[3, 3, 3]]) '''
# 3. 乘法(叉乘)
>>> np.multiply(a, b) # 或者 a*b
''' Out:array([[ 4, 10, 18],
[ 4, 10, 18]]) '''
# 4. 乘法(点乘)
a = np.array([[1,2,3],[4,5,6]])
b = np.array([4,5,6])
>>> np.dot(a,b)
# Out:array([32, 77])
# 5. 除法
a = np.array([[1,2,3],[4,5,6]])
b = np.array([[4,5,6],[1,2,3]])
>>> np.divide(a,b) # 或者 a/b
''' Out:array([[ 0.25, 0.4 , 0.5 ],
[ 4. , 2.5 , 2. ]]) '''
- 向量与标量之间
a = np.array([[1,2,3],[4,5,6]])
# 1. 加法
>>> a + 1
''' Out:array([[2, 3, 4],
[5, 6, 7]]) '''
# 2. 减法
>>> a - 1
''' Out:array([[0, 1, 2],
[3, 4, 5]]) '''
# 3. 乘法
>>> a * 2
''' Out:array([[ 2, 4, 6],
[ 8, 10, 12]]) '''
# 4. 除法
>>> a / 2
''' Out:array([[ 0.5, 1. , 1.5],
[ 2. , 2.5, 3. ]]) '''
# 5. 求余
>>> a % 2
''' Out:array([[1, 0, 1],
[0, 1, 0]]) '''
# 6. 矩阵转置(横纵变化)
>>> a.T
''' Out:array([[1, 4],
[2, 5],
[3, 6]]) '''
# 7.矩阵的逆
# 矩阵可逆的充要条件是矩阵满秩。
import numpy as np
import numpy.linalg as lg # lin alg 为线性代数库(linear algebra)
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
>>> lg.inv(a)
''' Out:array(
[[ 3.15251974e+15, -6.30503948e+15, 3.15251974e+15],
[ -6.30503948e+15, 1.26100790e+16, -6.30503948e+15],
[ 3.15251974e+15, -6.30503948e+15, 3.15251974e+15]]) '''
- Numpy数组的切片与索引
Presentation:一维Numpy数组的切片操作与Python列表的切片一样。下面首先来定义数字0 1 2直到8的数组,然后通过指定下标3到7来选择数组的部分元素,这实际上就是提取数组中值为3到6的元素。
import numpy as np
a = np.arange(9)
>>> a[3: 7]
# Out: array([3, 4, 5, 6])
同时用下标选择元素,下标范围从0到7,并且下标每次递增2
如下代码所示:
>>> a[: 7: 2]
# Out:array([0,2,4,6])
也可以像Python数组一样,用负值下标来反转数组:
>>> a[: : -1]
# Out: array([8,7,6,5,4,3,2,1,0])
对于二维数组的索引,类似与Python数组的列表:
a=np.array([[1,2,3],[4,3,2]])
>>> a[1][0]
# Out:array([4])
>>> a[1,:2] # 前面参数确定第几维数组的索引,后面参数为此维数组的前几个索引
# Out:array([4, 3])
- 改变数组形状
Presentation:使用Numpy,我们可以方便的更改数组的形状,比如使用reshape()、ravel()、flatten()、transpose()函数等。
- 改变数组形状:reshape() 方法
import numpy as np
b = np.arange(24).reshape(2,3,4)
>>> b
''' Out: array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]]) '''
- ravel() 方法:拆解,将多维数组变成一维数组。
>>> b.ravel()
''' Out: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]) '''
- flatten() 方法:拉直,其功能与ravel()相同,但是flatten()返回的是真实的数组,需要分配新的内存空间,而ravel()仅仅是改变视图。
>>> b.flatten()
''' Out: array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]) '''
- shape() 方法:相当于一个数组的属性。使用元组改变数组形状。
b.shape = (6, 4)
>>> b
''' out: array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]) '''
- transpose() 方法:对数组进行转置(以主对角线为对称轴)。
>>> b.transpose()
''' Out: array([[ 0, 4, 8, 12, 16, 20],
[ 1, 5, 9, 13, 17, 21],
[ 2, 6, 10, 14, 18, 22],
[ 3, 7, 11, 15, 19, 23]]) '''
- Numpy数组的堆叠
Presentation:从深度看,数组既可以横向叠放,也可以竖向叠放。因此,我们我们对数组进行堆叠,Numpy数组对堆叠包含以下几个函数:
首先,创建两个数组。
a = np.arange(9).reshape(3, 3)
>>> a
''' Out: array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]) '''
b = a * 2
>>> b
''' Out: array([[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]]) '''
- hstack() 方法:水平叠加。
np.hstack((a, b)) # 注意 这里是两层括号
''' Out: array([[ 0, 1, 2, 0, 2, 4],
[ 3, 4, 5, 6, 8, 10],
[ 6, 7, 8, 12, 14, 16]]) '''
- vstack() 方法:垂直叠加。
np.vstack((a,b))
''' Out:array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 0, 2, 4],
[ 6, 8, 10],
[12, 14, 16]]) '''
- dstack() 方法:深度叠加。
>>> np.dstack((a,b))
''' Out: array([[[ 0, 0],
[ 1, 2],
[ 2, 4]],
[[ 3, 6],
[ 4, 8],
[ 5, 10]],
[[ 6, 12],
[ 7, 14],
[ 8, 16]]]) '''
- Numpy的拆分
Presentation:使用Numpy,我们可以方便的对数组进行拆分,比如使用hsplit()、vsplit()、dsplit()、split()函数等。
import numpy as np
a = np.arange(9).reshape(3, 3)
>>> a
''' Out: array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]]) '''
- hsplit() 方法:横向拆分(在水平层次进行的拆分)。
np.hsplit(a, 3) # 竖着切,第二个参数为切的刀数
''' Out:[array([[0], [3], [6]]),
array([[1], [4], [7]]),
array([[2], [5], [8]])] '''
- vsplit() 方法:纵向拆分(在垂直层次进行的拆分)。
np.vsplit(a, 3) # 横着切
''' Out: [array([[0, 1, 2]]), array([[3, 4, 5]]), array([[6, 7, 8]])] '''
- dsplit() 方法:深度拆分。
Notice:深度拆分要求数组的秩大于等于3。
c= np.arange(27).reshape(3, 3, 3)
>>> np.dsplit(c, 3) # 竖着一路切下去(上列尾接下列头)
''' Out:[array([[[ 0], [ 3], [ 6]],
[[ 9], [12], [15]],
[[18], [21], [24]]]),
array([[[ 1], [ 4], [ 7]],
[[10], [13], [16]],
[[19], [22], [25]]]),
array([[[ 2], [ 5], [ 8]],
[[11], [14], [17]],
[[20], [23], [26]]])] '''
进阶用法
- Numpy广播(Broadcast)
Introduction:广播(Broadcast)是 numpy 对不同形状(shape)的数组,进行数值计算的方式。 对数组的算术运算通常在相应的元素上进行,当运算中的 2 个数组的形状不同时,numpy 将自动触发广播机制。如图:
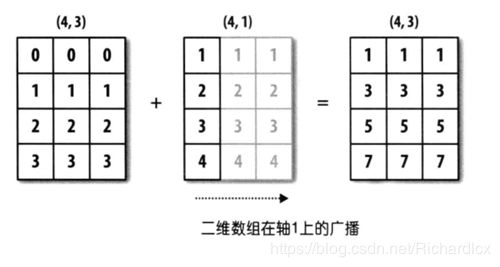
广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐;
- 输出数组的形状是输入数组形状的各个维度上的最大值;
- 如果输入数组的某个维度和输出数组的对应维度的长度相同,或者其长度为 1 时,这个数组能够用来计算,否则出错;
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算,都用此维度上的第一组值。
- Numpy高级索引
Introduction:NumPy 比一般的 Python 序列提供更多的索引方式。除了基本的用整数和切片的索引外,数组还有整数数组索引、布尔索引及花式索引。
- 整数数组索引
以下实例获取数组中(0,0),(1,1)和(2,0)位置处的元素(相当于坐标)。
In : x = np.arange(12).reshape((4,3))
In : y = x[[0, 1, 2],[0, 1, 0]]
In : y
Out: array([0, 4, 6])
- 布尔索引
以下实例获取数组中大于7的元素。
In : x = np.arange(12).reshape((4,3))
In : y = x[x > 7]
In : y
Out: array([8, 9, 10, 11])
- 花式索引
Introduction:花式索引指的是利用整数数组进行索引。
Detail:花式索引根据索引数组的值,作为目标数组的某个轴的下标来取值。对于使用一维整型数组作为索引,如果目标是一维数组,那么索引的结果就是对应位置的元素;如果目标是二维数组,那么就是对应下标的行。
Notice:花式索引跟切片不一样,它总是将数据复制到新数组中。
- 传入单个索引数组
以下实例获取数组的第5、1、2、3行。
In : x = np.arange(15).reshape((5,3))
In : y = x[[4, 0, 1, 2]]
In : y
Out: array([12, 13, 14]
[0, 1, 2]
[3, 4, 5]
[6, 7, 8])
- 传入多个索引数组
Notice:传入多个索引数组,则需要和numpy.ix_同时使用。
Extension:numpy.ix_:传入两个参数,第一个参数为数组索引,第二个参数为排列顺序。
In : x = np.arange(12).reshape((4,3))
In : y = x[np.ix_([1, 2],[2, 1, 0])]
In : y
Out: array([5, 4, 3]
[8, 7, 6])
- Numpy迭代数组
Introduction:NumPy迭代器对象numpy.nditer提供了一种灵活访问一个或者多个数组元素的方式。利用nditer对象可以实现完成访问数组中的每一个元素,这项最基本的功能,使用标准的Python迭代器接口,可以逐个访问每一个元素。
In : x = np.arange(6).reshape(2, 3)
In : for y in np.nditer(x):
print(y, end=" ")
Out:
0 1 2 3 4 5
- 控制迭代顺序
Detail:nditer对象提供了一个命令参数,来控制迭代输出顺序,默认值是’K’,即order=‘k’。该默认值表示,按在存储器中的顺序输出。同时nditer中,还提供了两个参数,控制迭代器输出顺序:
for x in np.nditer(a, order='F') # Fortran order,即是列序优先;
for x in np.nditer(a, order='C') # C order,即是行序优先;
Notice:col为列,row为行
- 修改数组元素值
Detail:默认情况下,nditer 将视待迭代遍历的数组为只读对象(read-only),为了在遍历数组的同时,实现对数组元素值的修改,必须将可选参数op_flags指定为 read-write 或者 write-only 的模式。
In : x = np.arange(6).reshape(2, 3)
In : for y in np.nditer(x, op_flags=["readwrite"]):
y[...] = 2 * y # [...]-这样的操作会对y映射的数据x产生影响
In : print(x)
Out:
array([[ 0, 2, 4]
[ 6, 8, 10]])
- 使用外部循环
Explanation:将一维的最内层的循环转移到外部循环迭代器,使得numpy的矢量化操作,在处理更大规模数据时,变得更有效率。
In : x = np.arange(6).reshape(2, 3)
In : for y in np.nditer(x, flags=['external_loop'], order='F'):
print(y)
Out:
[0, 3]
[1, 4]
[2, 5]
- 广播迭代
Introduction:如果两个数组是可广播的,nditer 组合对象能够同时迭代它们。 假设数组a的维度为34,数组b的维度为14,则使用以下迭代器(数组b被广播到a的大小),过程中对应配对。
In : a = np.arange(12).reshape(3, 4)
In : b = np.arange(4)
In : for x, y in np.nditer([a, b]):
print("{}:{}".format(x,y), end=", ")
Out:
0:1, 1:2, 2:3, 3:4, 4:1, 5:2, 6:3, 7:4, 8:1, 9:2, 10:3, 11:4,
3. re 库 (正则表达式)
Description:正则表达式是一个以简单直观的方式通过寻找模式匹配文本的工具。
3.1入门
3.1.1 正则匹配函数
Expansion:python中的正则表达式(re模块)
- search()函数,它的目的是接收一个正则表达式和一个字符串,并返回发现的第一个匹配的字符串。
import re
a = re.search(r'fox','the quick brown fox jumpred') #第一个参数为正则表达式,第二个参数为要处理的字符串
print(a.span()) # span方法获取的是正则表达式匹配到的位置范围
b = re.search(r'www','the quick brown fox jumpred')
print(b) #如果匹配不到则会返回None
输出如下:
(16, 19)
None
3.1.2 基础正则表达式–字符组
- 获得多个匹配信息
Description:在很多常见的场景中需要进行多个匹配,比如在学生名单中过滤出所有的张姓学生的个数。如果有这种需求咱们可以使用re模块中的findall或者 finditer方法。两个方法的区别在于findall 返回的是一个列表,finditer返回的是一个生成器。
l = re.findall(r'张','张三 张三丰 张无忌 张小凡')
print(l)
# ['张', '张', '张', '张']
Explanation:在这个例子中,我们会发现findall返回了4个“张”,这是因为“张”字在后面的字符串中出现了4次。即findall返回了所有的匹配信息。
- 字符组
Introduction:字符组允许匹配一组可能出现的字符,在正则表达式中用[]表示字符组标志。举个例子:
'I like Python3 and I like python2.7 ’
在这句话中,既有大写的Python,又有全部是小写的python。如果我要求都匹配出来,这时候该怎么操作了?这就是正则匹配中字符组的威力了。下面看下示例。
a = re.findall(r'[Pp]ython','I like Python3 and I like python2.7 ')
print(a)
# ['Python', 'python']
Notice:可以发现[Pp]既可以匹配大写的P也可以匹配小写的p,这里值的我们注意的是[Pp]仅匹配一个字符,他表示匹配在这个[]内的某一个。
3.1.3 快捷方式与快捷方式取反
- 快捷方式
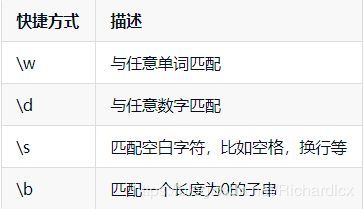
Introduction:正则表达式引擎提供了一些快捷方式:
- \w,与 “任意单词字符”匹配,在Python3中,基本上可以匹配任何语言的任意单词。
- 而当我们想要匹配任意数字的时候也可以使用快捷方式 \d,d即digit,在Python3中它除了可以和[0-9]匹配,还可以和其他语言的数字匹配。
- \s快捷方式匹配空白字符,比如空格,tab、换行 等。
- \b 快捷方式匹配一个长度为0的字符串,但是,他仅仅在一个单词开始或结尾处匹配,这被称为词边界快捷方式。
a = re.findall(r'\w','学好Python 大展拳脚')
b = re.search(r'\w','python3')
c = re.search(r'\d','编号89757')
print(a)
print(b)
print(c)
# ['学', '好', 'P', 'y', 't', 'h', 'o', 'n', '大', '展', '拳', '脚']
# Notice:这里findall会返回所有能匹配的值,而search只会返回第一个匹配到的值。
a = re.findall(r'\bmaster\b','masterxiao-master-xxx master abc') #单词字符后面或前面不与另一个单词字符直接相邻
b = re.search('r\bmaster\b','master')
print(a)
print(b)
# ['master', 'master']
# None
a = re.search(r'\smaster\s','masterxiao master xxx')
print(a)
# - 快捷方式取反
Description:之前提到了取反,快捷方式也可以取反, 例如对于\w的取反为\W,可以发现将小写改写成大写即可。
Notice:注意这里\B有所不同,\b 匹配的是在单词开始或结束位置长度为0的子字符串,而\B匹配不在单词开始和结束位置的长度为0的子字符串。
a = re.findall(r'\Bmaster\B','masterxiao master xxx master abc') # 单词字符后面或前面不与另一个单词字符直接相邻
b = re.search(r'master\B','masterxiao')
print(a)
print(b)
# []
# 3.1.4 基础正则表达式–区间与区间取反
- 区间
Description:有一些常见的字符组非常大,比如,我们要匹配的是任意数字,如果依照上述代码,每次我们都需要使用[0123456789] 这种方式明显很不明智,而如果要匹配从a-z的字母,我们也这样编写代码的话,肯定会让我们崩溃。
So:为了适应这一点,正则表达式引擎在字符组中使用连字符(-)代表区间,所以我们匹配任意数字可以使用[0-9],所以如果我们想要匹配所有小写字母,可以写成[a-z],想要匹配所有大写字母可以写成[A-Z]
Maybe:我们还有个需求:匹配连字符。因为-在会被正则表达式引擎理解为代表连接区间,所以这个时候我们需要对-进行转义。
Such as:
a = re.findall(r'[0-9]','xxx007abc')
b = re.findall(r'[a-z]','abc001ABC')
c = re.findall(r'[A-Za-z0-9]','abc007ABC')
d = re.findall(r'[0-9\-]','0edu 007-edu')
print(a)
print(b)
print(c)
print(d)
# ['0', '0', '7']
# ['a', 'b', 'c']
# ['a', 'b', 'c', '0', '0', '7', 'A', 'B', 'C']
# ['0', '0', '0', '7', '-']
- 2.区间取反
Description:到目前我们定义的字符组都是由可能出现的字符定义,不过有时候我们可能希望根据不会出现的字符定义字符组,例如:匹配不包含数字的字符组。
a = re.findall(r'[^0-9]','xxx007abc')
b = re.search(r'[^0-9]','xxx007abc')
print(a)
print(b)
# ['x', 'x', 'x', 'a', 'b', 'c']
# So:可以通过在字符数组开头使用 ^ 字符实现取反操作,从而可以反转一个字符组(意味着会匹配任何指定字符之外的所有字符)。接下来在看一个表达式:n[^e] 这意味着字符n接下来的字符是除了e之外所有的字符。
a = re.findall(r'n[^e]','final')
b = re.search(r'n[^e]','final')
c = re.findall('r[n[^e]]','Python')
print(a)
print(b)
print(c)
# ['na']
# Notice:还有一些以“+字母”的形式取特定的反
- \ W:匹配任意不是字母、数字、下划线、汉字的字符(Word)
- \ S:匹配任意不是空白符的字符(Str)
- \ D:匹配任意非数字的字符(Digit)
- \ B:匹配不是单词开头或结尾的位置(Besides)
Summary:这里我们可以发现a和b匹配的是na,字符a因为不是e所以可以被匹配,而变量c的值为空,在这里正则表达式引擎只匹配到了字符串n的位置,而n之后没有任何可以匹配[^e]的字符了,所以这里也匹配失败。
3.1.5 字符串的开始与结束
- 字符串的开始和结束
Introduction:在正则表达式中 用^ 可以表示开始,用 $表示结束。
a = re.search(r'^python', 'python is easy')
b = re.search(r'python$', 'python is easy')
c = re.search(r'^python', 'i love python')
d = re.search(r'python$', 'i love python')
print(a.span())
print(b)
print(c)
print(d.span())
# (0, 6)
# None
# None
# (7, 13)
In conclusion:可以发现,在上述例子中,python is easy和i love python都存在python字符串,但是在一个在开头一个在结尾,因此变量a和变量d都匹配到了信息。其他则无法匹配到信息。
3.1.6 任意字符
- 通配符
Introduction:在生活中我们经常会有这么一种场景,我们记得某个人名为孙x者,就是不记得他叫孙行者,在正则表达式中针对此类场景,产生了通配符的概念,用符号.表示。它代表匹配任何单个字符,不过值得注意的是,它只能出现在方括号字符组以外。
Notice:值得注意的是:.字符只有一个不能匹配的字符,也就是换行(\n),,不过让.字符与换行符匹配也是可能的,以后会讨论。示范如下:
a = re.findall(r'p.th.n','hello python re')
b = re.findall(r'p.....','学好 python 人见人爱')
print(a)
print(b)
# 输出:
# ['python']
# ['python']
3.1.7 可选字符
Introduction:使用 ? 符号指定一个字符、字符组或其他基本单元可选,这意味着正则表达式引擎将会期望该字符出现零次或一次。
a = re.search(r'honou?r','He Served with honor and distinction')
b = re.search(r'honou?r','He Served with honour and distinction')
c = re.search(r'honou?r','He Served with honou and distinction')
print(a)
print(b)
print(c)
# In conclusion:可以发现,在上述三个例子中,正则表达式为honou?r,这里可以匹配的是 honor 和 honour 不能匹配 honou,可以知道的是 ? 确定了前一个u是可选的,在第一个示例中,没有u,是没有问题可以匹配的,在第二个示例中,u存在这也没有问题。在第三个例子中,u存在但是r不存在,这样就不能匹配了。
3.1.8 重复区间
Introduction:在正则表达式在一个字符组后加上{N} 就可以表示{N} 之前的字符组出现N次。举个例子:
a = re.findall(r'[\d]{4}-[\d]{7}','张三:0731-8825951,李四:0733-8794561')
print(a)
# 输出为:['0731-8825951', '0733-8794561']
- 重复区间语法:{M,N},M是下界而N是上界。
For example:
a = re.search(r'[\d]{3,4}','0731')
b = re.search(r'[\d]{3,4}','073')
print(a)
print(b)
# In conclusion:通过上述代码,我们发现[\d]{3,4} 既可以匹配3个数字也可以匹配4个数字,不过当有4个数字的时候,优先匹配的是4个数字,这是因为正则表达式默认是贪婪模式,即尽可能的匹配更多字符,而要使用非贪婪模式,我们要在表达式后面加上 ?号。
a = re.search(r'[\d]{3,4}?','0731')
b = re.search(r'[\d]{3,4}?','073')
print(a)
print(b)
<re.Match object; span=(0, 3), match='073'>
<re.Match object; span=(0, 3), match='073'>
Notice:值得注意的是,上述代码这样子使用就只能匹配3个数字而无法匹配4个了,除非最少4个。
3.1.9 开闭区间与速写
- 开闭区间
Description:在实际生活中,我们经常会遇到一种场景,我们知道此处会填写什么格式,但是我们不确定填写的内容。比如说每月支出,我们知道此处一定是数字,但是不确定这个月支出了多少钱,是3位数,还是4位数,说不定这个月就花了10个亿。这时候我们可以用开区间来表示此范围,如下所示:
a = re.search(r'[\d]{1,}','我这个月花了:5元')
print(a)
# 输出为:- 速写
Description:在正则表达式中,我们可以通过开闭区间来应对此种重复次数没有边界的场景。但是如此常见的需求,为什么不简单一点用一个符号表示出来了,每次都这样写不累么?是的,不仅累而且影响阅读,因此在正则表达式中,推出了2个符号:
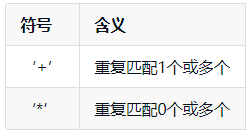
- 重复符号 +
Introduction:符号’+’用来表示重复一次到无数次,如下示范:
a = re.findall(r'[\d]+','0731-8859456')
print(a)
# ['0731', '8859456']
- 重复符号 *
Introduction:符号’*'用来表示重复0次到无数次,如下示范:
a = re.findall(r'[\d]*','0731-8859456')
print(a)
['0731', '', '8859456', '']
Why?这一次的输出多了两个’’?
Because of:在匹配-与末尾的字符时,没有匹配到一个数字,但是我们匹配到了0个数字,因此输出了空的字符串’’.
3.2 替换
- 示例1:
Content:使用re.sub()函数将 str 中的 , all rights reserved 替换为 空格(str中的空格不替换)。
import re
str ='2010-2019 , all rights reserved 信息科技有限公司'
after_Replacement1 =re.sub("[,a-z\s]+"," ",str)
print(after_Replacement1)
# 输出:2010-2019 信息科技有限公司
- 示例2:
Content:使用re.sub+ lambda 将 str字符串中的2016-2019字符串替换为2016年-2019年成立。
import re
str ='2016-2019 信息科技有限公司'
after_Replacement2 = re.sub('(\\d+)\\W(\\d+).*(\W+)', lambda x:x.group(1)+'年-'+x.group(2)+'年成立'+x.group(3),str)
print(after_Replacement2)
# 输出:2016年-2019年成立 信息科技有限公司
3.3 分组
- 分组
Description:要实现分组很简单,使用()即可。从正则表达式的左边开始看,看到的第一个左括号(表示表示第一个分组,第二个表示第二个分组,依次类推(要符合分组的内容)。
a='python正则表达式之分组dfsl
'
print(re.search(r'(.*)' ,a).group(1))
# 输出:
# python正则表达式之分组
Notice:需要注意的是,有一个隐含的全局分组(就是索引号为0的分组),就是整个正则表达式匹配的结果。
- 命名分组
Description:命名分组就是给具体有默认分组编号的组另外再起一个别名,方便以后的引用。
Grammer:命令分组的语法格式如下:
(?P<name>正则表达式)
Notice:语法格式中的字符P必须是大写的P(grouping),name是一个合法的标识符,表示分组的别名。如下例子:
a = "ip='127.0.0.1',version='1.0.0'"
res = re.search(r"ip='(?P\d+\.\d+\.\d+\.\d+).*" , a)
print(res.group('ip')) #通过命名分组引用分组
# 输出:
# 127.0.0.1
3.3 标记
- 不区分大小写
Introduction:re.IGNORECASE也可以简写为re.I,使用该标记,可以使正则表达式变为不区分大小写。
For example:
a = re.search(r'apple',"THIS IS AN APPLE",re.IGNORECASE)
b = re.search(r'apple','THIS IS AN APPLE',re.I)
print(a)
print(b)
# 输出:
# <_sre.SRE_Match object; span=(11, 16), match='APPLE'>
# <_sre.SRE_Match object; span=(11, 16), match='APPLE'>
- 点匹配换行符
Introduction:re.DOTALL标记(别名为re.S)可以让.字符除了匹配其他字符之外,还匹配换行符。
For example:
a = re.search(r'.+','hello\npython')
b = re.search(r'.+','hello\npython',re.S)
c = re.search(r'.+','hello\npython',re.DOTALL)
print(a)
print(b)
print(c)
#输出:
# <_sre.SRE_Match object; span=(0, 5),match='hello'>
# <_sre.SRE_Match object; span=(0, 12),match='hello\npython'>
# <_sre.SRE_Match object; span=(0, 12),match='hello\npython'>
- 多行模式
Introduction:re.MULTILINE标记(别名为re.M)可以匹配多行,使用该标记可以使得仅能够匹配字符串开始与结束的^与$字符可以匹配字符串内任意行的开始与结束。
a = re.search(r'^like','foo\nlike')
b = re.search(r'^like','foo\nlike',re.M)
print(a)
print(b)
# 输出:
# None
# <_sre.SRE_Match object; span=(4, 8), match='like'>
- 详细模式
Introduction:re.VERBOSE标记(别名为re.X)允许复杂的正则表达式以更容易的方式表示。
Description:该标记做两件事,首先,它会使所有的空白(除了字符组中)被忽略,包括换行符。其次,它将#字符(同样,除非在字符组内)当做注释字符。
For example:
a = re.search(r'(?P[\d]{3})-(?P[\d]{4})' ,'867-5556')
b = re.search(r"""(?P[\d]{3})
- #匹配一个 - 连接符
(?P[\d]{4}) # 匹配四个数字
""" ,
'010-1234',re.X)
print(a)
print(b)
# 输出:
# <_sre.SRE_Match object; span=(0, 8), match='010-1234'>
# <_sre.SRE_Match object; span=(0, 8), match='010-1234'>
- 调试模式
Introduction:re.DEBUG标记(没有别名)在编译正则表达式时将一些调试信息输出到 sys.stderr
For example:
a = re.search(r'(?P[\d]{3})-(?P[\d]{4})' ,'010-1234',re.DEBUG)
print(a)
# 输出:
# SUBPATTERN 1
# MAX_REPEAT 3 3
# IN
# CATEGORY CATEGORY_DIGIT
# LITERAL 45
# SUBPATTERN 2
# MAX_REPEAT 4 4
# IN
# CATEGORY CATEGORY_DIGIT
# <_sre.SRE_Match object; span=(0, 8), match='010-1234'>
- 使用多个标记
Description:有时候我们可能需要同时使用多个标记,为了完成这点,可以使用|操作符。
示例: re.DOTALL|re.MULTILINE 或 re.S | re.M 。
3.4 编译
Introduction:compile函数用于编译正则表达式,返回一个正则表达式对象,供match()、search()、findall()等函数使用。
示例如下:
str ='1Ab2Cdef3ds5ds548s4ds848we8rt6g46d46df48t6ds6x48g6s'
pattern = re.compile('\D') # 编译正则表达式
pattern_Math = pattern.match(str) # 决定RE是否在字符串刚开始的位置匹配。如果满足,则返回一个match对象;如果不满足,返回空。
print(pattern_Math) # 返回被RE匹配的字符串
# 输出:None
Description:使用re的一般步骤是先将正则表达式的字符串形式编译为pattern实例(RegexObject),然后使用pattern实例处理文本并获取匹配结果(一个Match实例(值为True)),最后使用Match实例获取信息,进行其他的操作。可以把那些经常使用的正则表达式编译成正则表达式对象,可以提高程序的执行速度。
math_Group = pattern.match(str,1,10) # 查找从索引 1 开始 10 结束
print(math_Group.group()) # 返回被RE匹配的字符串
# 输出:A
pattern_Find1 = pattern.findall(str) # 找到RE匹配的所有子串,并把它们作为一个列表返回
print(pattern_Find1) # 返回一个列表
# 输出 ['A', 'b', 'C', 'd', 'e', 'f', 'd', 's', 'd', 's', 's', 'd', 's', 'w', 'e', 'r', 't', 'g', 'd', 'd', 'f', 't', 'd', 's', 'x', 'g', 's']
pattern_Find2 = pattern.findall(str,5,10) # 查找从索引 5 开始到 10 结束的所有子串,并把它们作为一个列表返回
print(pattern_Find2)
# 输出:['d', 'e', 'f', 'd']
3.5 断言
- 先行断言
Description:先行断言分为正向先行断言和反向先行断言,完成本关任务需要了解这两个知识点。
- 正向先行断言
Introduction:(?=pattern)表示正向先行断言,整个括号里的内容(包括括号本身)代表字符串中的一个位置,紧接该位置之后的字符序列能够匹配pattern。举个例子:
# `(?!e)`代表字符串中的一个位置,紧接该位置之后的字符序列只能够匹配`e`。
a = re.findall(r'n(?=al)','final')
b = re.findall(r'n(?=e)','python')
c = re.findall(r'n(?=e)','jasmine')
print(a)
print(b)
print(c)
# 输出:
# ['n']
# []
# ['n']
- 反向先行断言
Introduction:(?!pattern)表示反向先行断言,与正向先行断言相反,紧接该位置之后的字符序列不能够匹配pattern。同样举个例子:
a = re.findall(r'n(?!e)','final')
b = re.findall(r'n(?!e)','python')
c = re.findall(r'n(?!e)','next')
print(a)
print(b)
print(c)
# 输出:
# ['n']
# ['n']
# []
注意:反向断言不支持匹配不定长的表达式,也就是说+、*字符不适用于反向断言的前后。
- 后发断言
Introduction:后行断言分为正向后发断言和反向后发断言,完成本关需要掌握这两个知识点。
- 正向后发断言
Introduction:(?<=pattern)正向后发断言代表字符串中的一个位置,紧接该位置之前的字符序列只能够匹配pattern。
a = re.findall('(?<=a)n','final')
b = re.findall('(?<=a)n','command')
c = re.findall('(?<=i)n','negative')
print(a)
print(b)
print(c)
# 输出:
# []
# ['n']
# []
- 反向后发断言
Introduction:(?
a = re.findall('(?,'final')
b = re.findall('(?,'command')
c = re.findall('(?,'negative')
print(a)
print(b)
print(c)
# 输出:
# []
# []
# ['n']
In conclusion:从上面的描述可以看出,先行和后发的区别就是是否有<,正向与反向的区别是=和!。
3.6 特殊字符
For example:!@#$%.?^&*
3.7 实际应用
3.7.1 组合密码匹配
Demand:
-
正确密码包括数字,字母,特殊字符;
-
包含空格,换行,制表符等空字符的密码无效;
-
密码不能为纯数字,纯字母,纯特殊字符。
pattern = re.compile(r"^(?!\d+$)(?![\b]+$)(?![!@#$%^&*.?]+$)(?!\s+$)[a-zA-Z\d!@#$%^&.*?]+$", re.M)
四、应用方面
网络爬虫
1. 利用URL获取超文本文件并保存至本地
Description:当我们想要在浏览器中打开一个网页时,需要在浏览器的地址栏中输入该网页的url,例如在地址栏中输入百度搜索网站的首页url:https://www.baidu.com/ ,点击确认后,浏览器将向服务器发出一个对该网的请求;服务器端收到请求后,会返回该网页的超文本文件,浏览器收到服务器端发来的网页超文本文件后,对其进行解析,然后在窗口中显示该超文本文件对应的网页。如下图所示。

此网页对应的超文本文件如下图所示。
Target:我们将使用Python程序,实现通过网页的url,获得服务器返回的超文本文件,并打印出来的功能。
- 访问url的urlopen()方法
Introduction:Python提供了urllib.request模块用来处理网页的url。
Grammar:urllib.request.urlopen(url[, data[, proxies]]):创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据。
参数说明:一般我们只用到第一个参数。
- url表示远程数据的路径,一般是网页的网址;
- data表示以post方式提交到url的数据;
- proxies用于设置代理。
- 返回值说明:urlopen()返回一个类文件对象,返回结果可使用read() , readline(), readlines(),fileno(),close()等方法直接使用。下面给出了具体的使用示例:
# coding=utf-8
import urllib.request as req
f = req.urlopen('http://www.baidu.com')
firstLine = f.readline() #读取html页面的第一行
print(firstLine)
print(firstLine.decode('utf-8'))
其中:
- ‘http://www.baidu.com’: 要访问的url,百度搜索首页的网址;
- req.urlopen(): 调用了urllib.request.urlopen()方法,引用时用req替代了urllib.request;
- f.readline(): f是类文件对象,进行行读取操作。
输出结果:
b'\n'
<!DOCTYPE html>
- 将远程数据下载到本地的urlretrieve()方法
Grammar:urllib.request.urlretrieve(url[, filename[, reporthook[, data]]]):将url定位的服务器端的html文件下载到你本地的硬盘中。如果不指定filename,则会存为临时文件。
参数说明:一般我们只用到前两个参数。
-
url外部或者本地url地址;
-
filename指定了保存到本地的路径(如果未指定该参数,urllib会生成一个临时文件来保存数据);
-
reporthook是一个回调函数,当连接上服务器、以及相应的数据块传输完毕的时候会触发该回调,我们可以利用这个回调函数来显示当前的下载进度;
-
data指post到服务器的数据。该方法返回一个包含两个元素的元组(filename, headers),filename表示保存到本地的路径,header表示服务器的响应头。
-
返回值说明:urlretrieve()返回一个二元组(filename, mine_hdrs),下面给出了具体的使用示例:
# coding=utf-8
import urllib.request as req
url = 'http://www.baidu.com'
path = 'D:\\baidu.html'
req.urlretrieve(url, path)
# 输出结果:在D盘目录下会创建一个baidu.html文件。
2. 实现子链接的提取
Knowledge:完整的URL = 协议 + 域名 + 资源在服务器上的路径,即子网页网址 = “http://”+ “www.gotonudt.cn” + “/site/gfkdbkzsxxw/lqfs/info/2017/717.html”。
- 字符串查找find()方法
Detail:Python字符串中find()方法检测字符串中是否包含子字符串str,如果指定 beg(开始) 和 end(结束)范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
Grammar:下面具体看下这个函数:find(str, beg=(0), end=len(string))
- str:指定检索的字符串;
- beg:开始索引,默认为0;
- end:结束索引,默认为字符串的长度;
- 返回值:如果包含子字符串则返回子字符串开始的索引值,否则返回-1。
string = r'国防科技大学2016年录取分数统计 '
index = string.find("国防科技大学2016年录取分数统计")
print(index)
print(string[index])
输出结果:
105
国
For example:从网页中找到2012到2016年国防科技大学录取分数线统计网页的子链接url数据并提取出来
- Python代码
urls = []
# year = 2016
years = [2016, 2015, 2014, 2013, 2012]
# 从data中提取2016到2012每一年分数线子网站地址添加到urls列表中
# while (year != 2011):
for year in years:
index = data.find("国防科技大学" + str(year) + "年录取分数统计")
path = data[index-79: index-39] # 根据单个特征串提取url子串
complete_url = protocol + domain + path
urls.append(complete_url)
# 输出结果:
# 提取子链接如下:
# ['http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2017/717.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2016/663.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2015/610.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2014/253.html', 'http://www.gotonudt.cn/site/gfkdbkzsxxw/lqfs/info/2014/234.html']
3. 网页内容解析
-
参数html为网页源代码
-
根据网页源代码提取电影信息,格式如下:
Format:获取内容由board-index ***(排名)、date-src(图片地址)、title(影片名)、 star(主演)、releasetime(上映时间)、integer、f\fraction (评分 如:9.5 integer:9. f\fraction:5)标签组合。
参考html文本:
<dd>
<i class="board-index board-index-2">2i>
<a href="/films/1297" title="肖申克的救赎" class="image-link" data-act="boarditem-click" data-val="{movieId:1297}">
<img src="//s3plus.meituan.net/v1/mss_e2821d7f0cfe4ac1bf9202ecf9590e67/cdn-prod/file:5788b470/image/loading_2.e3d934bf.png" alt="" class="poster-default" />
<img data-src="https://p0.meituan.net/movie/283292171619cdfd5b240c8fd093f1eb255670.jpg@160w_220h_1e_1c" alt="肖申克的救赎" class="board-img" />
a>
<div class="board-item-main">
<div class="board-item-content">
<div class="movie-item-info">
<p class="name"><a href="/films/1297" title="肖申克的救赎" data-act="boarditem-click" data-val="{movieId:1297}">肖申克的救赎a>p>
<p class="star">
主演:蒂姆·罗宾斯,摩根·弗里曼,鲍勃·冈顿
p>
<p class="releasetime">上映时间:1994-09-10(加拿大)p> div>
<div class="movie-item-number score-num">
<p class="score"><i class="integer">9.i><i class="fraction">5i>p>
div>
div>
div>
dd>
解析提取代码:
- Method one
# 根据标签前后做解析
import re
def analysis():
lists = list()
joint = ".+"
ranking = ""
url = "![</span>
title <span class=]() = "= "
= "= ".+(主演:.+)\n\s+
"
releasetime = "(上映时间:.+)
" # 尽可能考虑全面一些,数据量丰富一些
integer = "([\d.]{2})"
fraction = "(\d)"
# pattern = re.compile("\"board-index-([\d]+)\">.+![.+title=\"(\w+)\".+<p]() (.+).+
(.+).+.+(.+).+(\d))
pattern1 = re.compile(ranking + joint + url + joint + title + joint + star \
+ joint + releasetime + joint + integer + fraction, re.S)
joint = ".*?"
ranking = ".*?board-index.*?>(.*?)"
url = "data-src=\"(.*?)\""
title = "name.*?a.*?>(.*?)"
star = "star.*?>\s+(.*?)\s+"
releasetime = "releasetime.*?>(.*?)" # 尽可能考虑全面一些,数据量丰富一些
integer = "integer.*?>(.*?)"
fraction = "fraction.*?>(.*?).*?"
pattern2 = re.compile(ranking + joint + url + joint + title + joint + star \
+ joint + releasetime + joint + integer + joint + fraction, re.S) # 单双引号交替开更加高效
# 掌握真正意义上的关键字 以标签为关键 要的是尖括号里面的内容 有时候对页面负责一点就应该全部匹配(有始有终)
# info = (pattern2.search(html).groups())
# lists.append(info)
lists = pattern1.findall(html) # 先拿出分组的元组,在套以列表形式返回
print(lists)
- Method two
# 在表格数据中做解析(根据一个绝对位置,找另一个相对位置)
tds = re.findall(r'(.*?)' , row, re.S)
for td in tds:
rightindex = td.find('')
leftindex = td[:rightindex].rfind('>')
items.append(td[leftindex+1:rightindex])
scorelist.append(items)