决胜Spark大数据时代企业级最佳实践:Spark Core&Spark SQL&GraphX&Machine Learning&Best Practice
王家林:Spark、Docker、Android技术中国区布道师。
电话:18610086859
QQ:1740415547
微信号:18610086859
特别说明:
本课程在Spark企业级开发实战的基础之上做了两点增强:
Ø 课程全程有超过100个Spark大数据代码案例;
Ø 课程在第四天特别增加了Spark机器学习深入研究与实战专题,以满足企业级大数据机器学习的高级处理需求,机器学习部分的内容也特别适合于大数据Hadoop&Spark工程师的进阶学习;
课程介绍
如何把云计算大数据处理速度提高100倍以上?Spark给出了答案。
Spark是可以革命Hadoop的目前唯一替代者,能够做Hadoop做的一切事情,同时速度比Hadoop快了100倍以上,下图来自Spark的官方网站:
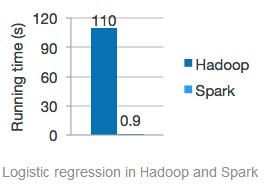
可以看出在Spark特别擅长的领域其速度比Hadoop快120倍以上!
Spark是基于内存,是云计算领域的继Hadoop之后的下一代的最热门的通用的并行计算框架开源项目,尤其出色的支持Interactive Query、流计算、图计算等。
Spark在机器学习方面有着无与伦比的优势,特别适合需要多次迭代计算的算法。同时Spark的拥有非常出色的容错和调度机制,确保系统的稳定运行,Spark目前的发展理念是通过一个计算框架集合SQL、Machine Learning、Graph Computing、Streaming Computing等多种功能于一个项目中,具有非常好的易用性。
目前SPARK已经构建了自己的整个大数据处理生态系统,如流处理、图技术、机器学习、NoSQL查询等方面都有自己的技术,并且是Apache顶级Project,可以预计的是2014年下半年在社区和商业应用上会有爆发式的增长。
国内的淘宝、优酷土豆等已经使用Spark技术用于自己的商业生产系统中,国内外的应用开始越来越广泛,国外一些大型互联网公司已经部署了Spark。甚至连Yahoo是Hadoop的早期主要贡献者,现在也在多个项目中部署使用Spark,国内我们已经在运营商、电商等传统行业部署了Spark。
本课程是世界上第一Spark企业级最佳实践课程,课程包含:
Spark的架构设计;
Spark编程模型;
Spark内核框架源码剖析;
Spark的广播变量与累加器;
Shark的原理和使用;
Spark的机器学习;
Spark的图计算GraphX;
Spark SQL;
Spark实时流处理;
Spark程序的测试;
Spark的优化;
Spark on Yarn;
JobServer;
Spark机器学习深入研究与实战
培训对象
1, 云计算大数据从业者;
2, Hadoop使用者;
3, 系统架构师、系统分析师、高级程序员、资深开发人员;
4, 牵涉到大数据处理的数据中心运行、规划、设计负责人;
5, 政府机关,金融保险、移动和互联网等大数据来源单位的负责人;
6, 高校、科研院所涉及到大数据与分布式数据处理的项目负责人;
7, 数据仓库管理人员、建模人员,分析和开发人员、系统管理人员、数据库管理人员以及对数据仓库感兴趣的其他人员;
学员基础
了解面向对象编程;
了解Linux的基本使用;
王家林老师
Spark亚太研究院院长和首席专家,移动互联网、云计算和大数据技术领域技术集大成者。
当今云计算领域最火爆的技术Docker源码级专家和Docker技术在中国的最早实践者之一。
Android架构师、高级工程师、咨询顾问、培训专家;
Spark、Docker、Android技术中国区布道师。
在Spark、Hadoop、Android、Docker等方面有丰富的源码、实务和性能优化经验。彻底研究了Spark从0.5.0到1.1.0共18个版本的Spark源码,Spark最佳畅销书《大数据spark企业级实战》作者;
Hadoop源码级专家,曾负责某知名公司的类Hadoop框架开发工作,专注于Hadoop一站式解决方案的提供,同时也是云计算分布式大数据处理的最早实践者之一,Hadoop的狂热爱好者,不断的在实践中用Hadoop解决不同领域的大数据的高效处理和存储,现在正负责Hadoop在搜索引擎中的研发等,著有《云计算分布式大数据Hadoop实战高手之路---从零开始》《云计算分布式大数据Hadoop实战高手之路---高手崛起》《云计算分布式大数据Hadoop。实战高手之路---高手之巅》等;
多款浏览器定制者,中国大陆HTML5的技术引领者。
为超过50家公司提供了基于Linux和Android的软硬整合解决方案。
擅长构建系统和打造框架,特别精通于Java与C/C++混合的框架实现。
通晓Android、HTML5、Hadoop,迷恋英语播音和健美;
致力于Android、HTML5、Hadoop的软、硬、云整合的一站式解决方案;
国内最早(2007年)从事于Android系统移植、软硬整合、框架修改、应用程序软件开发以及Android系统测试和应用软件测试的技术专家和技术创业人员之一。
HTML5技术领域的最早实践者(2009年)之一,成功为多个机构实现多款自定义HTML5浏览器,参与某知名的HTML5浏览器研发;
超过10本的IT畅销书作者;
培训内容
| 第一天 |
第1堂课:Spark的架构设计 1.1 Spark生态系统剖析 1.2 Spark的架构设计剖析 1.3 RDD计算流程解析 1.4 Spark的出色容错机制
补充主题:快速掌握Scala 1 Scala变量声明、操作符、函数的使用实战 2 apply方法 3 Scal的控制结构和函数 4 Scala数组的操作、Map的操作 5 Scala中的类 6 Scala中对象的使用; 7 Scala中的继承 8 Scala中的特质 9 Scala中集合操作
第2堂课:Spark编程模型 2.1 RDD 2.2 transformation 2.3 action 2.4 lineage 2.5宽依赖与窄依赖
第3堂课:深入Spark内核 3.1 Spark集群 3.2 任务调度 3.3 DAGScheduler 3.4 TaskScheduler 3.5 Task内部揭秘
第4堂课:Spark的广播变量与累加器 4.1 广播变量的机制 4.2 广播变量使用最佳实践 4.3 累加器的机制 4.4 累加器使用的最佳实践
第5堂课:编写Spark程序 5.1 程序数据的来源:File、HDFS、HBase、S3等 5.2 IDE环境构建 5.3 Maven 5.4 sbt. 5.5 编写并部署Spark程序的实例
第6堂课:SparkContext解析和数据加载以及存储 6.1 源码剖析SparkContext 6.2 Scala、Java、Python使用SparkContext 6.4 加载数据成为RDD 6.5 把数据物化 |
|
| 时间 |
內 容 |
备注 |
|
第二天 |
第7堂课:深入实战RDD 7.1 DAG 7.2 深入实战各种Scala RDD Function 7.3 Spark Java RDD Function 7.4 RDD的优化问题
第8堂课:Shark的原理和使用 8.1 Shark与Hive 8.2 安装和配置Shark 8.3 使用Shark处理数据 8.4 在Spark程序中使用Shark Queries 8.5 SharkServer 8.6 思考Shark架构
第9堂课:Spark的机器学习 9.1 LinearRegression 9.2 K-Means 9.3 Collaborative Filtering
第10堂课:Spark的图计算GraphX 10.1 Table Operators 10.2 Graph Operators 10.3 GraphX
第11堂课:Spark SQL 11.1 Parquet支持 11.2 DSL 11.3 SQL on RDD
|
|
| 时间 |
內 容 |
备注 |
|
第三天 |
第12堂课:Spark实时流处理 12.1 DStream 12.2 transformation 12.3 checkpoint 12.4 性能优化
第13堂课:Spark程序的测试 13.1 编写可测试的Spark程序 13.2 Spark测试框架解析 13.3 Spark测试代码实战
第14堂课:Spark的优化 14.1 Logs 14.2 并发 14.3 内存 14.4 垃圾回收 14.5 序列化 14.6 安全
第15堂课:Spark on Yarn 15.1 Spark on Yarn的架构原理 15.2 Spark on Yarn的最佳实践
第16堂课:JobServer 16.1 JobServer的架构设计 16.2 JobServer提供的接口 16.3 JobServer最佳实践 |
|
| 时间 |
內 容 |
备注 |
|
第四天 |
第17堂课:Generalized Linear Model u Logistic regression u Linear regression u SVM u LASSO u Ridge regression
第18堂课:Recommendation u Recommendation ALS u Singular Value Decomposition u The implementation in both MLlib and Mahout u Applied demo of recommendation with PredictionIO.
第19堂课:Clustering u k-means u LDA u Applied demo of geo-location clustering and topic modeling
第20堂课:Streaming-wised Machine Learning u Lambda Architecture u Parameter Server u Several algorithms from Freeman labs u Applied demo such as the zebrafish experiment
第21堂课:ML Pipeline u Pipeline of Scikit-learn u Pipeline of Spark (DataFrame, ML Pipeline, etc.) u Applied demo (TBD)
第22堂课:Optimization in Parallel u Commonly used optimization algorithms u Sequential gene of optimization algorithms u BSP model to BSP+ model to SSP u Future ways?
|
|