数据分析入门之好莱坞百万级评论数据分析
文章目录
- 1、数据的加载与集成
- 1.1、导入相关的包
- 1.2、导入数据
- 1.2.1、读取用户数据
- 1.2.2、读取电影数据
- 1.2.3、读取评分数据
- 1.3、数据合并
- 1.4、查看数据
- 1.4.1、查看数据形状
- 1.4.2、查看前5行
- 1.4.3、查看去重后大小
- 2、平均分较高的电影
- 2.1、调用透视表
- 2.2、查看前五行
- 2.3、排序
- 2.4、查看前10名
- 2.5、查看后10名
- 3、不同性别对电影平均评分
- 4、不同性别争议最大的电影
- 4.1、评分差距
- 4.2、排序
- 4.3、查看差距情况
- 4.4、男女数据集联
- 4.5、分析结果
- 5、评分次数最多热门的电影
- 5.1、pandas 分组运算
- 5.2、排序
- 6、查看不同年龄段争议最大的电影
- 6.1、查看用户的年龄分布情况
- 6.2、用pandas.cut()函数将用户年龄分组
- 6.3、每个年龄段用户评分人数和打分偏好
- 6.3.1、年龄范围评分的平均分
- 6.3.2、年龄范围评分的人数
- 6.3.3、同时求每个年龄段评分人数及平均分
- 7、优化数据,真实可靠
- 7.1加入评分次数限制来分析不同性别对电影的平均评分
- 7.1.1、建立索引
- 7.1.2、找出这50行数据
- 7.1.3、数据可视化分析
- 7.2、加入评分次数限制来分析平均分高的电影
- 7.2.1、建立索引
- 7.2.2、索引出符合条件的数据
操作环境: window10,Python3.7,Jupyter notebook
数据资料: https://www.lanzous.com/i96rt3e
数据分析要求:
- 数据的加载与集成
- 平均分较高的电影
- 不同性别对电影平均评分
- 不同性别争议最大电影
- 评分次数最多热门的电影
- 不同年龄段争议最大的电影
1、数据的加载与集成
1.1、导入相关的包
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
import matplotlib.pyplot as plt
%matplotlib inline
1.2、导入数据
- 这里一共有三个
.dat数据,还有一个是数据的说明文档(README),我们可以直接把它们分别拖进浏览器打开查看,如我打开README文件,查看其他三个文件的表头

1.2.1、读取用户数据
# UserID::Gender::Age::Occupation::Zip-code
labels = ['UserID', 'Gender', 'Age', 'Occupation', 'Zip-code']
users = pd.read_csv('users.dat', sep='::', header=None, names=labels, engine ='python')
users.shape
(6040, 5)
查看前五行:
users.head()
| UserID | Gender | Age | Occupation | Zip-code | |
|---|---|---|---|---|---|
| 0 | 1 | F | 1 | 10 | 48067 |
| 1 | 2 | M | 56 | 16 | 70072 |
| 2 | 3 | M | 25 | 15 | 55117 |
| 3 | 4 | M | 45 | 7 | 02460 |
| 4 | 5 | M | 25 | 20 | 55455 |
1.2.2、读取电影数据
# MovieID::Title::Genres
labels = ['MovieID', 'Title', 'Genres']
movies = pd.read_csv('movies.dat', sep='::', header=None, names=labels, engine ='python')
movies.shape
(3883, 3)
查看前五行:
| MovieID | Title | Genres | |
|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation|Children's|Comedy |
| 1 | 2 | Jumanji (1995) | Adventure|Children's|Fantasy |
| 2 | 3 | Grumpier Old Men (1995) | Comedy|Romance |
| 3 | 4 | Waiting to Exhale (1995) | Comedy|Drama |
| 4 | 5 | Father of the Bride Part II (1995) | Comedy |
1.2.3、读取评分数据
# UserID::MovieID::Rating::Timestamp
labels = ['UserID', 'MovieID', 'Rating', 'Timestamp']
ratings = pd.read_csv('ratings.dat', sep='::', header=None, names=labels, engine ='python')
ratings.shape
(1000209, 4)
查看前五行:
| UserID | MovieID | Rating | Timestamp | |
|---|---|---|---|---|
| 0 | 1 | 1193 | 5 | 978300760 |
| 1 | 1 | 661 | 3 | 978302109 |
| 2 | 1 | 914 | 3 | 978301968 |
| 3 | 1 | 3408 | 4 | 978300275 |
| 4 | 1 | 2355 | 5 | 978824291 |
1.3、数据合并
- 数据分布于三个表,可以将数据合并到一个表;数据合并专业词汇,数据集成
展示这三个数据:
display(users.head(), movies.head(), users.head())
movies和ratings有共同的head(MovieID),先进行合并
df1 = pd.merge(left=movies, right=ratings)
df1.head()
| MovieID | Title | Genres | UserID | Rating | Timestamp | |
|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 1 | 5 | 978824268 |
| 1 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 6 | 4 | 978237008 |
| 2 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 8 | 4 | 978233496 |
| 3 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 9 | 5 | 978225952 |
| 4 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 10 | 5 | 978226474 |
df1 和 users 合并:
movie_data = pd.merge(df1, users)
1.4、查看数据
1.4.1、查看数据形状
movie_data.shape
(1000209, 10)
1.4.2、查看前5行
movie_data.head()
| MovieID | Title | Genres | UserID | Rating | Timestamp | Gender | Age | Occupation | Zip-code | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 1 | 5 | 978824268 | F | 1 | 10 | 48067 |
| 1 | 48 | Pocahontas (1995) | Animation|Children's|Musical|Romance | 1 | 5 | 978824351 | F | 1 | 10 | 48067 |
| 2 | 150 | Apollo 13 (1995) | Drama | 1 | 5 | 978301777 | F | 1 | 10 | 48067 |
| 3 | 260 | Star Wars: Episode IV - A New Hope (1977) | Action|Adventure|Fantasy|Sci-Fi | 1 | 4 | 978300760 | F | 1 | 10 | 48067 |
| 4 | 527 | Schindler's List (1993) | Drama|War | 1 | 5 | 978824195 | F | 1 | 10 | 48067 |
1.4.3、查看去重后大小
movie_data['Title'].unique().size
3706
2、平均分较高的电影
2.1、调用透视表
movie_rate_mean = pd.pivot_table(movie_data, values=['Rating'], index=['Title'], aggfunc='mean')
movie_rate_mean.shape
(3706, 1)
2.2、查看前五行
| Rating | |
|---|---|
| Title | |
| $1,000,000 Duck (1971) | 3.027027 |
| 'Night Mother (1986) | 3.371429 |
| 'Til There Was You (1997) | 2.692308 |
| 'burbs, The (1989) | 2.910891 |
| ...And Justice for All (1979) | 3.713568 |
2.3、排序
movie_rate_mean.sort_values(by='Rating', ascending=False, inplace=True)
2.4、查看前10名
- 直接截取出前面10条数据
movie_rate_mean[0: 10]
| Rating | |
|---|---|
| Title | |
| Ulysses (Ulisse) (1954) | 5.0 |
| Lured (1947) | 5.0 |
| Follow the Bitch (1998) | 5.0 |
| Bittersweet Motel (2000) | 5.0 |
| Song of Freedom (1936) | 5.0 |
| One Little Indian (1973) | 5.0 |
| Smashing Time (1967) | 5.0 |
| Schlafes Bruder (Brother of Sleep) (1995) | 5.0 |
| Gate of Heavenly Peace, The (1995) | 5.0 |
| Baby, The (1973) | 5.0 |
2.5、查看后10名
movie_rate_mean[-10: ]
3、不同性别对电影平均评分
- 透视表透视数据的结构
方法一:
movie_gender_rating_mean = pd.pivot_table(movie_data, values=['Rating'], index=['Title', 'Gender'], aggfunc='mean')
movie_gender_rating_mean.shape #(7152, 1)
movie_gender_rating_mean.head()
| Rating | ||
|---|---|---|
| Title | Gender | |
| $1,000,000 Duck (1971) | F | 3.375000 |
| M | 2.761905 | |
| 'Night Mother (1986) | F | 3.388889 |
| M | 3.352941 | |
| 'Til There Was You (1997) | F | 2.675676 |
方法二:
movie_gender_rating_mean = pd.pivot_table(movie_data, values='Rating', index=['Title'], columns=['Gender'], aggfunc='mean')
movie_gender_rating_mean.shape #(3706, 2)
movie_gender_rating_mean.head()
| Gender | F | M |
|---|---|---|
| Title | ||
| $1,000,000 Duck (1971) | 3.375000 | 2.761905 |
| 'Night Mother (1986) | 3.388889 | 3.352941 |
| 'Til There Was You (1997) | 2.675676 | 2.733333 |
| 'burbs, The (1989) | 2.793478 | 2.962085 |
| ...And Justice for All (1979) | 3.828571 | 3.689024 |
4、不同性别争议最大的电影
原理: 用女性的评分减去男性的评分得出它们评分得差距
4.1、评分差距
# 新增一列,男女用户对电影评分的差异
movie_gender_rating_mean['diff'] = movie_gender_rating_mean['F'] - movie_gender_rating_mean['M']
movie_gender_rating_mean.head()
| Gender | F | M | diff |
|---|---|---|---|
| Title | |||
| $1,000,000 Duck (1971) | 3.375000 | 2.761905 | 0.613095 |
| 'Night Mother (1986) | 3.388889 | 3.352941 | 0.035948 |
| 'Til There Was You (1997) | 2.675676 | 2.733333 | -0.057658 |
| 'burbs, The (1989) | 2.793478 | 2.962085 | -0.168607 |
| ...And Justice for All (1979) | 3.828571 | 3.689024 | 0.139547 |
4.2、排序
movie_gender_rating_mean.sort_values(by='diff', ascending=False, inplace=True)
4.3、查看差距情况
● 女性用户和男性用户差异最大,前面为正,女性用户最喜欢的前10个
movie_gender_rating_mean[:10]
| Gender | F | M | diff |
|---|---|---|---|
| Title | |||
| James Dean Story, The (1957) | 4.000000 | 1.000000 | 3.000000 |
| Spiders, The (Die Spinnen, 1. Teil: Der Goldene See) (1919) | 4.000000 | 1.000000 | 3.000000 |
| Country Life (1994) | 5.000000 | 2.000000 | 3.000000 |
| Babyfever (1994) | 3.666667 | 1.000000 | 2.666667 |
| Woman of Paris, A (1923) | 5.000000 | 2.428571 | 2.571429 |
| Cobra (1925) | 4.000000 | 1.500000 | 2.500000 |
| Other Side of Sunday, The (S鴑dagsengler) (1996) | 5.000000 | 2.928571 | 2.071429 |
| Theodore Rex (1995) | 3.000000 | 1.000000 | 2.000000 |
| For the Moment (1994) | 5.000000 | 3.000000 | 2.000000 |
| Separation, The (La S閜aration) (1994) | 4.000000 | 2.000000 | 2.000000 |
● 女性用户和男性用户差异最大,后面为负,男性用户最喜欢的前10个,也就是倒数10个
movie_gender_rating_mean[-10: ]
| Gender | F | M | diff |
|---|---|---|---|
| Title | |||
| White Boys (1999) | NaN | 1.000000 | NaN |
| Wild Bill (1995) | NaN | 3.146341 | NaN |
| Windows (1980) | NaN | 1.000000 | NaN |
| Wings of Courage (1995) | NaN | 3.000000 | NaN |
| With Byrd at the South Pole (1930) | NaN | 2.000000 | NaN |
| With Friends Like These... (1998) | NaN | 4.000000 | NaN |
| Wooden Man's Bride, The (Wu Kui) (1994) | NaN | 3.000000 | NaN |
| Year of the Horse (1997) | NaN | 3.250000 | NaN |
| Zachariah (1971) | NaN | 3.500000 | NaN |
| Zero Kelvin (Kj鎟lighetens kj鴗ere) (1995) | NaN | 3.500000 | NaN |
出现空值的原因: 由于有写电影女性不观看和不评论,所以出现空值,需要去掉空值再查看数据。
movie_gender_rating_mean.dropna()[-10: ]
| Gender | F | M | diff |
|---|---|---|---|
| Title | |||
| Jamaica Inn (1939) | 1.0 | 3.142857 | -2.142857 |
| Flying Saucer, The (1950) | 1.0 | 3.300000 | -2.300000 |
| Rosie (1998) | 1.0 | 3.333333 | -2.333333 |
| In God's Hands (1998) | 1.0 | 3.333333 | -2.333333 |
| Dangerous Ground (1997) | 1.0 | 3.333333 | -2.333333 |
| Killer: A Journal of Murder (1995) | 1.0 | 3.428571 | -2.428571 |
| Stalingrad (1993) | 1.0 | 3.593750 | -2.593750 |
| Enfer, L' (1994) | 1.0 | 3.750000 | -2.750000 |
| Neon Bible, The (1995) | 1.0 | 4.000000 | -3.000000 |
| Tigrero: A Film That Was Never Made (1994) | 1.0 | 4.333333 | -3.333333 |
4.4、男女数据集联
diff = pd.concat([f, m])
4.5、分析结果
# 分析结果,数据可视化
diff.plot(kind='barh', figsize=(12, 9)) #barh水平方向
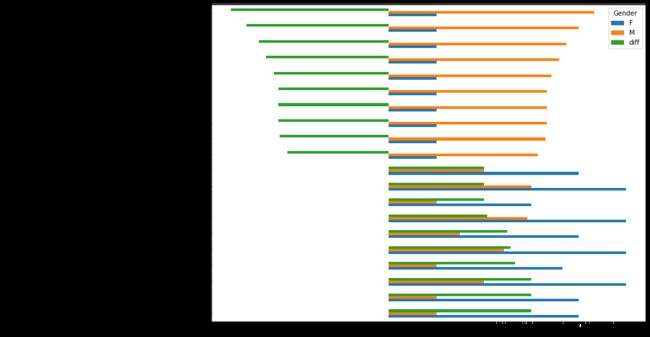
5、评分次数最多热门的电影
5.1、pandas 分组运算
rating_count = movie_data.groupby(['Title']).size()#统计电影名称出现的次数
rating_count
Title
$1,000,000 Duck (1971) 37
'Night Mother (1986) 70
'Til There Was You (1997) 52
'burbs, The (1989) 303
...And Justice for All (1979) 199
...
Zed & Two Noughts, A (1985) 29
Zero Effect (1998) 301
Zero Kelvin (Kj鎟lighetens kj鴗ere) (1995) 2
Zeus and Roxanne (1997) 23
eXistenZ (1999) 410
Length: 3706, dtype: int64
5.2、排序
rating_count.sort_values(ascending=False) #ascending=False不进行升序
Title
American Beauty (1999) 3428
Star Wars: Episode IV - A New Hope (1977) 2991
Star Wars: Episode V - The Empire Strikes Back (1980) 2990
Star Wars: Episode VI - Return of the Jedi (1983) 2883
Jurassic Park (1993) 2672
...
Anna (1996) 1
McCullochs, The (1975) 1
Shadows (Cienie) (1988) 1
Night Tide (1961) 1
Another Man's Poison (1952) 1
Length: 3706, dtype: int64
6、查看不同年龄段争议最大的电影
6.1、查看用户的年龄分布情况
直方图展示:
movie_data['Age'].plot(kind='hist', bins=20)

求最大值:
movie_data.Age.max()
56
6.2、用pandas.cut()函数将用户年龄分组
labels = ['0-9', '10-19', '20-29', '30-39', '40-49', '50-59']
movie_data['Age_range'] = pd.cut(movie_data['Age'], bins=range(0, 61, 10), labels=labels)
movie_data.head()
| MovieID | Title | Genres | UserID | Rating | Timestamp | Gender | Age | Occupation | Zip-code | Age_range | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Toy Story (1995) | Animation|Children's|Comedy | 1 | 5 | 978824268 | F | 1 | 10 | 48067 | 0-9 |
| 1 | 48 | Pocahontas (1995) | Animation|Children's|Musical|Romance | 1 | 5 | 978824351 | F | 1 | 10 | 48067 | 0-9 |
| 2 | 150 | Apollo 13 (1995) | Drama | 1 | 5 | 978301777 | F | 1 | 10 | 48067 | 0-9 |
| 3 | 260 | Star Wars: Episode IV - A New Hope (1977) | Action|Adventure|Fantasy|Sci-Fi | 1 | 4 | 978300760 | F | 1 | 10 | 48067 | 0-9 |
| 4 | 527 | Schindler's List (1993) | Drama|War | 1 | 5 | 978824195 | F | 1 | 10 | 48067 | 0-9 |
6.3、每个年龄段用户评分人数和打分偏好
6.3.1、年龄范围评分的平均分
movie_data.groupby('Age_range')['Rating'].mean()
Age_range
0-9 3.549520
10-19 3.507573
20-29 3.545235
30-39 3.618162
40-49 3.673559
50-59 3.766632
Name: Rating, dtype: float64
6.3.2、年龄范围评分的人数
movie_data.groupby('Age_range')['Rating'].size()
Age_range
0-9 27211
10-19 183536
20-29 395556
30-39 199003
40-49 156123
50-59 38780
Name: Rating, dtype: int64
6.3.3、同时求每个年龄段评分人数及平均分
movie_data.groupby('Age_range').agg({'Rating':[np.size, np.mean]})
| Rating | ||
|---|---|---|
| size | mean | |
| Age_range | ||
| 0-9 | 27211 | 3.549520 |
| 10-19 | 183536 | 3.507573 |
| 20-29 | 395556 | 3.545235 |
| 30-39 | 199003 | 3.618162 |
| 40-49 | 156123 | 3.673559 |
| 50-59 | 38780 | 3.766632 |
7、优化数据,真实可靠
问题: 为什么那些平均分高的电影,我们重来没有看过?甚至有些听都没有听说过?这个问题是不是不符合常理,毕竟国内外好的电影大家案例说都应该耳熟能详的,所有这其中一定存在错误
movie_rate_mean[:10]
| Rating | |
|---|---|
| Title | |
| Ulysses (Ulisse) (1954) | 5.0 |
| Smashing Time (1967) | 5.0 |
| Baby, The (1973) | 5.0 |
| Gate of Heavenly Peace, The (1995) | 5.0 |
| Schlafes Bruder (Brother of Sleep) (1995) | 5.0 |
| Lured (1947) | 5.0 |
| One Little Indian (1973) | 5.0 |
| Song of Freedom (1936) | 5.0 |
| Bittersweet Motel (2000) | 5.0 |
| Follow the Bitch (1998) | 5.0 |
这是为什么? 因为评分次数相差悬殊,看的人少,少数人评分反而很高
解决方案:
- 加入评分次数限制来分析不同性别对电影的平均评分
- 加入评分次数限制来分析平均分高的电影
7.1加入评分次数限制来分析不同性别对电影的平均评分
7.1.1、建立索引
#以Title进行分组,统计次数大小,排序,数据反转,前50列,索引
top_movie_title = movie_data.groupby('Title').size().sort_values()[::-1][:50].index
top_movie_title.size
50
7.1.2、找出这50行数据
flag = movie_gender_rating_mean.index.isin(top_movie_title)
df1 = movie_gender_rating_mean[flag].sort_values(by='diff')
df1.head()
| Gender | F | M | diff |
|---|---|---|---|
| Title | |||
| Airplane! (1980) | 3.656566 | 4.064419 | -0.407854 |
| Godfather: Part II, The (1974) | 4.040936 | 4.437778 | -0.396842 |
| Aliens (1986) | 3.802083 | 4.186684 | -0.384601 |
| Terminator 2: Judgment Day (1991) | 3.785088 | 4.115367 | -0.330279 |
| Alien (1979) | 3.888252 | 4.216119 | -0.327867 |
7.1.3、数据可视化分析
- 查看被评价过最多次的50部电影在不同年龄段之间的打分差异
df1.plot(kind='barh', figsize=(12, 9))

7.2、加入评分次数限制来分析平均分高的电影
7.2.1、建立索引
index = movie_data.groupby('Title').size().sort_values()[::-1][:50].index
index.shape
(50,)
7.2.2、索引出符合条件的数据
flag = movie_rating_mean.index.isin(index)
# 热门电影平均分
movie_rating_top_mean = movie_rating_mean[flag]
movie_rating_top_mean.sort_values(by='Rating', ascending=False)
| Rating | |
|---|---|
| Title | |
| Shawshank Redemption, The (1994) | 4.554558 |
| Godfather, The (1972) | 4.524966 |
| Usual Suspects, The (1995) | 4.517106 |
| Schindler's List (1993) | 4.510417 |
| Raiders of the Lost Ark (1981) | 4.477725 |
| Star Wars: Episode IV - A New Hope (1977) | 4.453694 |
| Sixth Sense, The (1999) | 4.406263 |
| One Flew Over the Cuckoo's Nest (1975) | 4.390725 |
| Godfather: Part II, The (1974) | 4.357565 |
| Silence of the Lambs, The (1991) | 4.351823 |
| Saving Private Ryan (1998) | 4.337354 |
| American Beauty (1999) | 4.317386 |
| Matrix, The (1999) | 4.315830 |
| Princess Bride, The (1987) | 4.303710 |
| Star Wars: Episode V - The Empire Strikes Back (1980) | 4.292977 |
| Pulp Fiction (1994) | 4.278213 |
| Blade Runner (1982) | 4.273333 |
| Fargo (1996) | 4.254676 |
| Wizard of Oz, The (1939) | 4.247963 |
| Braveheart (1995) | 4.234957 |
| L.A. Confidential (1997) | 4.219406 |
| Alien (1979) | 4.159585 |
| Terminator, The (1984) | 4.152050 |
| Toy Story (1995) | 4.146846 |