MySQL——三大范式与数据库设计
前言
本文内容主要参考自《MySQL DBA 修炼之道》书中的第四章,算是原书的实践与补充。 上次主要讲了MySQL的索引与 EXPLAIN 的用法,是MySQL中非常重要的一部分,这次将进入下一部分,有关数据库的设计。
I. 三大范式
α. 范式含义
范式是数据库规范化的手段,那么啥又是数据库规范化 ?
数据库规范化通俗的来讲就是经过合理的设计,将大表分成很多有关联关系的小表,这样来去除数据的冗余;好处是写方便,数据一致性高,毕竟维护数据的部分工作都交给数据库处理了;缺点也显而易见,因为数据分散了,所以读数据麻烦,需要关联查询多个表才能获得最终完整的数据。
β. 第一范式(1NF)
属性不可分割,即列不可分割。
1NF主要保证每一个字段都是原子的,不可再分。举一个例子,商品表中每个商品对应都有商品参数,这其实是一个一对多的关系,比如手机参数包括品牌、型号、网络制式等。那么笼统的将商品参数直接作为一个字段,其实非原子的。

那么对应这种非原子的设计,其实如果仅仅进行存储读取,而不具体对某一项进行修改的话,是可以的。就像图中所示,直接将参数存成Json数据保存,这也是一种反范式的设计方式。
γ. 第二范式(2NF)
所有字段均与(联合)主键相关,即非主键列均依赖主键。
2NF的含义是指表中的字段都要和主键相关,这里主要指的是和联合主键的每一个主键字段都相关,不能有列只和部分主键相关。
这里摘录熊青峰的这篇文章中的一个示例,把问题具象一些。下面这个表中学号和课程号构成一个联合主键,确定表中唯一一条记录。我们发现,姓名、专业仅和学号有关,课程名仅和课程号有关,只有成绩和两者都有关系。
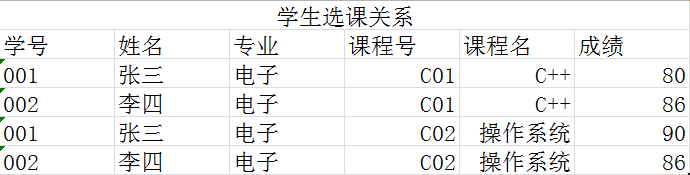
当我们要新登记学生一门课的成绩时,我们的数据会显得十分冗余,学生的基本信息登记了多次,课程名称也录入多次。所以,很容易我们会想到优化成一张学生表、一张课程表以及一张学生课程成绩表。
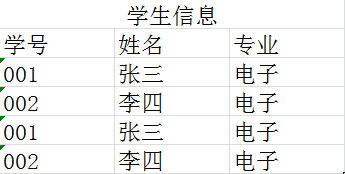
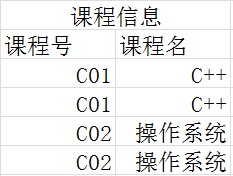

这样分成三个表,数据的冗余程度将会大大降低。
δ. 第三范式(3NF)
所有字段均与(联合)主键直接相关,即非主键列均直接依赖主键。
注意和2NF的差别,多了直接二字,那么什么是直接依赖?满足2NF的已经表明非主键列和主键列是相关的,但不代表它们是直接相关的。比如存在部分列依赖其他列,其他列依赖于主键,导致部分列间接依赖主键列。
例如下面这张学生信息表,学号可以认为是主键。那么姓名、系名确实和学号挂钩的,那么系主任是谁和学生的学号没有直接的联系关系,系主任和哪一个系才是直接挂钩的,所以系主任并不是直接依赖学号。

修改时,我们可以将系名和系主任单独抽成一张表,使得符合第三范式的要求。
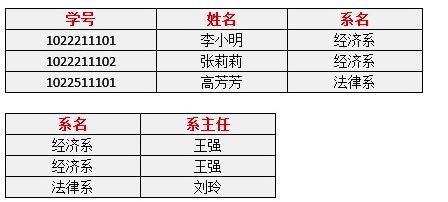
这样做,其实还是可以去冗余,方便数据的修改新增,读取的话则需要进行关联查询。
II. 反范式
范式的设计是去除冗余,写方便读不方便;那么反范式的目的自然是为了更好的读来故意添加一些冗余的数据。反范式是解决数据库性能和可伸缩性的极佳策略。
反范式可以减少读取数据时的关联查询,冗余数据间的一致性往往依靠数据库的约束或者应用程序来保证。传统的商业数据库通过数据库的约束(五大约束:主键、外键、唯一、非空、默认值)来保证数据一致性,互联网应用则更多依靠应用程序来实现数据的一致性。
常见的反范式方式:
- 增加冗余列:多个表中具有相同的列,这样可以单表查询而不需要连接;
- 增加派生列:增加的列由其他表中的数据计算生成,这样可以减少连接查询,避免使用聚集函数;
- 增加重复列:同一列因为有多值,则直接创建多个列。比如email1,email2,email3三个重复类型字段;
- 重新组表:将常常需要查看两个表连接出来的结果数据,则直接把这两个表组成一个表。
一个比较典型的场景,出于扩展性考虑,可能会使用 BLOB 和 TEXT 类型的列存储 JSON 结构的数据,这样的好处在于可以在任何时候,将新的属性添加到这个字段中,而不需要更改表结构。但是,这个设计的缺点也比较明显,就是需要获取整个字段内容进行解码来获取指定的属性,并且无法进行索引、排序、聚合等操作。因此,如果需要考虑更加复杂的使用场景,更加建议使用 MongoDB 这样的文档型数据库。
III. 数据库设计
数据库设计分为两个阶段:逻辑设计和物理设计。
α. 逻辑设计
主要是构建出ER模型,绘制ER图等,将ER模型映射为具体的表的相关描述。
β. 物理设计
物理设计包含:将逻辑设计转换为物理表、分析事务(业务)、选择存储引擎以及为表创建合适的索引。此外,还可以根据需要进行反范式的设计,列出最终表的详细说明。
分析事务主要是要设计的数据库表要满足用户的需求,分析预期所有的事务是较为麻烦的,遵循二八原则,我们要着重分析出最重要的20%的事务来覆盖80%的用户需求。着重关注业务频率、业务高峰时间、访问较多的业务,了解清楚业务涉及到哪些表,哪些字段,是否需要分组去重排序分页等数据处理等。
存储引擎的选择影响了数据的组织形式,聚簇索引还是非聚簇索引;也影响到一些功能的有无,比如数据库事务的支持、外键、锁粒度等。
创建索引则要根据具体的业务来分析可能会进行的高频查询操作来具体决定。小表无需创建索引,查询数据中大量使用的列或组合创建二级索引,考虑为高频率部分信息查询创建覆盖索引,查询或连接条件、分组排序等可以创建二级索引。当然,如果查询的结果超过25%的记录可以考虑不用索引,长字符串也不适合创建索引。
反范式设计主要是预想的一些性能优化考虑,带来的数据一致性挑战也需要注意。
最终表说明可以说明表的记录数大致多少,增长趋势,表中字段的差异度情况(主要用于分析索引的选择性决定是否创建),表的访问并发情况等等。