FastDFS之添加机器同步
FastDFS之添加机器同步
基于FastDFS 5.03/5.04
2014-12-19
一、添加机器同步概述
添加机器同步叫做源同步,简单说就是从组内现有的一台机器上推送历史数据到新机器的过程。每次部署集群,源同步是必定要发生的,可能你并没有注意。比如,部署一组三台机器,首次启动第一台机器时是直接添加到组内,而后面的机器都要进行源同步。源同步的目的就是为了保持新添加的机器数据与旧机器一致。
代码在tracker_client_thread.c\ storage_sync.c
在看这篇文章之前建议先看,我另外一篇讲述Binlog同步的文章。
1、几个主要概念
简单起见,这里所说的机器就是Storage。
1)新机器:表示之前不在该组中运行的机器(可能有数据也可能没有数据),现在要添加到该组中。
2)源机器:表示被Tracker选择出来,源机器需要将持有的数据推送给新机器。
3)源同步:就是原机器推送旧数据给新机器的过程。
4)增量同步:也就是Binlog同步,此时是组内的机器进行互相同步。
2、源同步的几个步骤
1)为新机器选择一个源机器
2)源机器推送数据
3)源同步完成设置新机器的状态
3、相关的本地文件
1).data_init_flag 文件,存在于 base/data/目录,与源同步相关的字段有如下三个:
sync_old_done=1 ##是否成功获取到源机器IP
sync_src_server=10.0.0.2 ##源主机的IP地址
sync_until_timestamp=1418285426 ##源主机负责的旧数据截止时间
2)10.0.0.2_23000.mark文件,存在于base/data/sync/目录,相关字段有:
need_sync_old=0 ##是否需要同步旧文件给对方
sync_old_done=0 ##若需要同步旧文件,那么旧文件是否同步完成
until_timestamp=0 ##源主机负责的旧数据截止时间
二、选择源机器
Storage在启动时会为每个Tracker开启一个线程,用于维持与其的通讯。当Storage是首次时,会向Tracker发送一个STORAGE_SYNC_DEST_REQ请求,向Tracker咨询由那台机器作为源。
Tracker收到请求后根据当前组内的机器状态,若组内没有机器,则告诉新机器不需要进行源同步;若组内有机器但是没有状态为Active的机器,那么返回一个错误,新机器将睡眠后重试;若组内有机器并且有状态为Active的机器,那么选择一台作为其源,返回两个值:当前时间作为源同步截止时间与源机器的IP,并且在本地记录该信息,同时将新机器状态设置成WAIT_SYNC。
注:由于可能配置多个Tracker,因此该请求在Storage中是采用互斥量同步的,因此一次只会有一个线程能够发起该请求,若请求成功则会设置标志位,第二个线程就不会再作该请求。
当新机器收到Tracker返回的源机器IP和源同步截止时间后,保存到全局的g_sync_src_id和g_sync_until_timestamp两个变量之中。这两个值随即被写入到 .data_init_flag的sync_src_server和sync_until_timestamp两个字段,并且将sync_old_done字段更新成1,表示已完成获取源主机的操作。
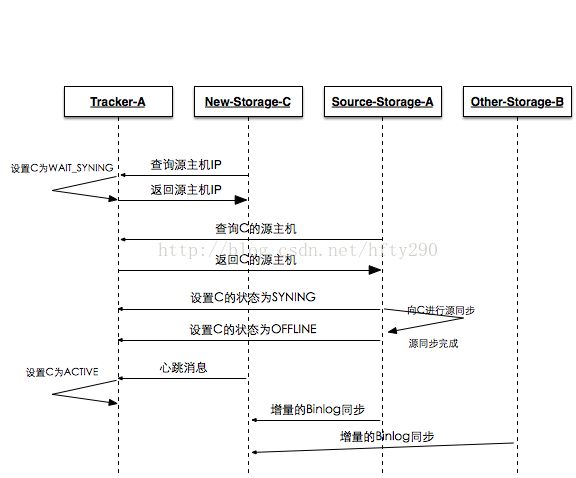
例如,当前FastDFS集群的配置如下,两个Tracker为Tracker-A,Tracker-B;两台已存在的Storage-A、Storage-B,现在添加Storage-C。当添加Storage-C时查询到的源机器为Storage-A。现在我们来一个多方会谈:
1、新机器Storage-C:
在从一台Tracker获取到源机器的IP和截止时间后,马上将该信息通知其他的Tracker。然后进入循环定期向Tracker发送心跳信息。当源同步完成后,源会将Storage-C状态设置成OFFLINE,在下一个心跳中,Tracker会将Storage-C状态设置成ACTIVE。此时新机器加入完毕。
2、源机器Storage-A:
在与Trakcer的心跳中,得到新机器Storage-C的信息,启动一个线程负责对Storage-C的同步。下面的操作都在该同步线程之中:
1)由于本地并没有Storage-C的信息(没有对应的mark文件),因此就会向Tracker查询Storage-C的源机器IP与源同步截止时间,同时判断这个源是否为自己;
2)发现自己就是新机器Storage-C的源,则将信息写入到Storage-C_23000.mark文件之中,其中need_sync_old=1; sync_old_done=0; util_timestamp = 查询到的源同步截止时间。
3)请求Tracker将Storage-C的状态设置成SYNING。
4)从头开始遍历本地的binlog文件,对于每一条记录执行如下判断:
若为源操作、或者(为非源操作并且操作时间小于源同步截止时间),则将该条记录对应操作同步给Storage-C;(同步过程中也会记录最后同步的offset,假如此时宕机了,下次启动也可以读到 Storage-C_23000.mark 文件的 need_sync_old 与 binlog_offset值继续源同步过程)。
5)当在某一个时刻,取不到更多地binlog时,请求Tracker将Storage-C状态设置成OFFLINE。此时源同步完成。
3、非源机器Storage-B:
在与Trakcer的心跳中,得到新机器Storage-C的信息,启动一个线程负责对Storage-C的同步。下面的操作都在该同步线程之中:
1)由于本地并没有Storage-C的信息(没有对应的mark文件),因此就会向Tracker查询Storage-C的源机器IP与源同步截止时间,同时判断这个源是否为自己;
2)新机器Storage-C的源是Storage-A不是自己,将信息写入到Storage-C_23000.mark文件之中,其中need_sync_old=0; sync_old_done=0; util_timestamp = 查询到的源同步截止时间。
3)进入睡眠等待,知道Storage-C的状态变成ACTIVE。
4)打开binlog,跳过操作时间小于源同步截止时间的记录,对之后的每一条为元操作的Binlog,都同步给Storage-C。
4、总结一下新添加机器的状态变化
三、注意事项
1、整个源同步过程中都是源机器使用一个同步线程,将数据推到新机器,因此和机器的磁盘个数没有关系。也就是说最多只能达到一个磁盘的IO,而不能并发。
2、由于源同步的截止条件为取不到binlog的时刻,因此若系统很繁忙,不断有新数据写入,就将会导致一致无法完成源同步这个过程。