ElasticSearch (ES)学习之路(五)ES 复杂搜索( 匹配 过滤 精准 排序 高亮)
ElasticSearch (ES)学习之路(五)ES 复杂搜索( 匹配 过滤 精准 排序 高亮)
在上文中,我们查询小红 其kinbana 语法是这样写的
GET /lei/one/_search?q=name:小丽
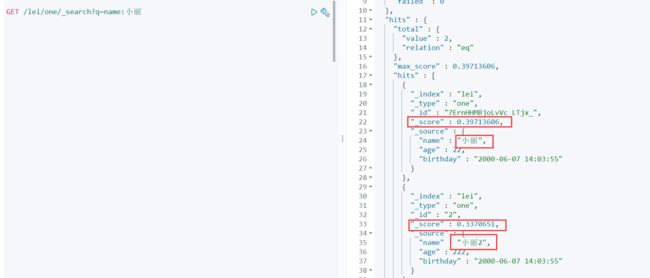
前文中,也是做了分析,由于有多个包含‘小丽’的数据,所以我们在搜索’小丽’ 时将与之相匹配的数据全部搜索了出来,并且 ,搜索出的每条数据都包含了一个_score 分值字段
其实质意义:_score=分值=匹配度 结果匹配度越高 分值则越高,则排名越是考前
在实际查询语法时候,我们大多不会写q=xxxxx ,而是写查询参数体 类似于 添加数据时的请求体,其查询语法如下
GET /索引名/类型名/_search
{
"query":{
"查询参数体 查询条件"
}
}
例如,我们还是接着 查询小丽的例子进行编写
单条件查询
使用kinbanna的好处,语法可以提示 如下 field 列名 match 匹配
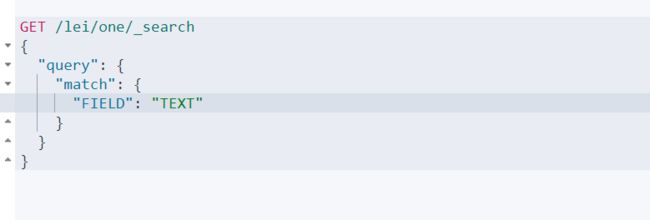
GET /lei/one/_search
{
"query": {
"match": {
"name": "小丽"
}
}
}
此操作就对应着我们开始编写的一行 语句 GET /lei/one/_search?q=name:小丽 ,只是更具有层次性,可读性更好,看,查询结果也是一模一样的。 这里匹配是什么意思呢 就是只要包含小丽的就算匹配 小丽 小丽2 都会命中
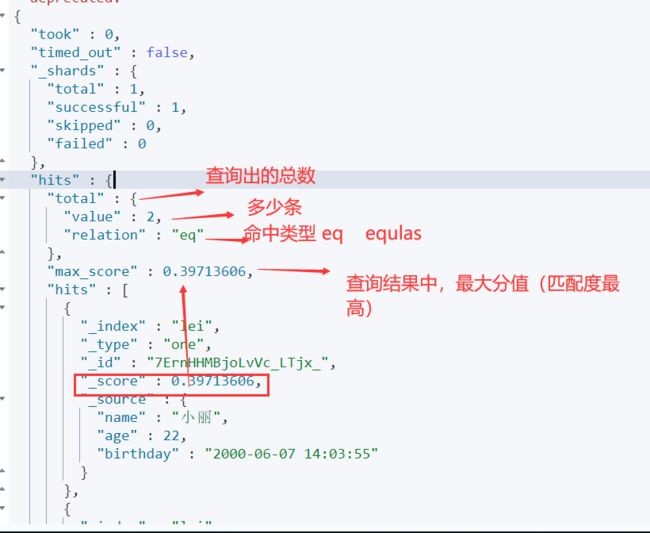
这个hits 就是查询出的结果集对象,其中即包含了文档数以及索引信息概括,以及包含了每个具体的文档数据

查询结果字段过滤
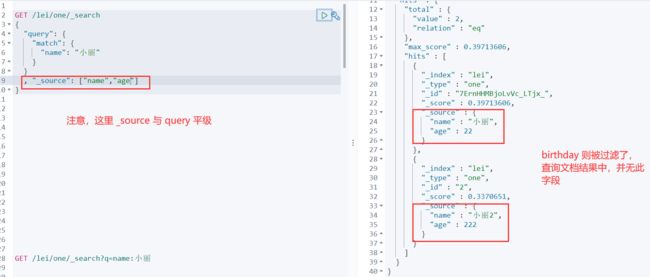
何为结果字段过滤呢?我们在写sql语句的时候,可以select * ,也可以select 列1,列2 , 根据我们select 的不同,返回不同的字段信息
那么在es 中也是有这个功能的
例如,在上方查询结果的,我们发现文档中的 三个字段 name age birthday 都被查询出来了
本文当前呢,为了演示,字段则返回 name age
GET /lei/one/_search
{
"query": {
"match": {
"name": "小丽"
}
}
, "_source": ["name","age"]
}
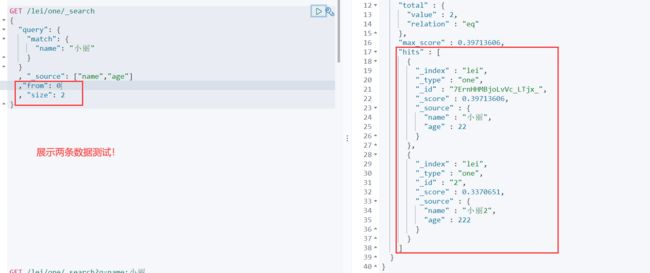
分页
为什么要分页,,,我这里就不用细说了吧(都学到es了,还不懂为啥要分页,那切雀雀吧)
由于我这里只有两条数据哈,所以分页呢,暂时一页一条即可
GET /lei/one/_search
{
"query": {
"match": {
"name": "小丽"
}
}
, "_source": ["name","age"]
,"from": 0
, "size": 1
}
from =(当前页-1)*每页长度
size= 每页长度(即每页要展示的长度)
注意的是.from size 都是与query为同级

排序
由于我之前添加文档一个采用了put指定_id,一个采用post 随机生成_ _ id ,我这里故采用年龄进行排序吧
排序,只需要在与 query同级别下 输入"sort" 其Kinbanba 就会自动帮我们补全 排序语法
GET /lei/one/_search
{
"query": {
"match": {
"name": "小丽"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}

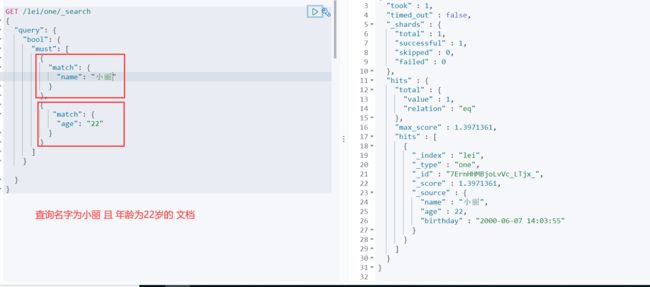
多条件匹配查询
等价于 sql 中 where xxx =?? and xxx=?? 查询名字为小丽 并且年龄为22岁
and
must 必须的意思 等价于 and 条件
GET /lei/one/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "小丽"
}
},
{
"match": {
"age": "22"
}
}
]
}
}
}
or
等价于 sql 中 where xxx =?? or xxx=?? 查询名字为小丽 或者年龄为222岁
or 条件 很简单 将上方的 must 改为 should (应该 )
should 应该的意思 等价于or 条件 拼接
GET /lei/one/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "小丽"
}
},
{
"match": {
"age": "222"
}
}
]
}
}
}

新增字段
查询某列中的值 包含xxx的数据 可以是数组中某一元素值等等 (我先前准备的数据没有哈,所以这里添加一个列,并添加一些数据)
POST /lei/one
{
"properties": {
"hobby": {
"type": "array"
}
}
}
POST /lei/one/2/_update
{
"doc":{
"hobby":["篮球","击剑"]
}
}
POST /lei/one/7ErnHHMBjoLvVc_LTjx_/_update
{
"doc":{
"hobby":["足球","爬山"]
}
}
查询某列中 包含XXX 的文档信息
查询某列中 包含某些值得文档 查询时 “列名”:" 包含的值 多个用空格隔开"
等价于 mysql 中 where xxx like “xxx”
我们可以看到 匹配度越高 其分值越高 排名也是靠前

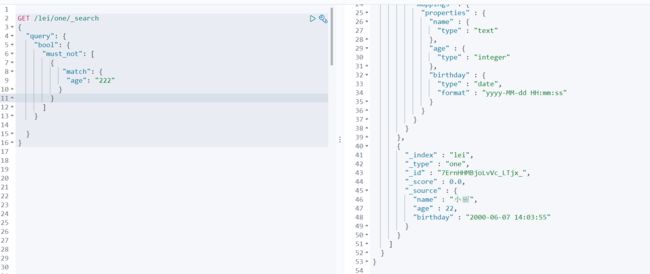
!= 条件查询
不等于 等价于msql中的 where xxx!= ??
我这里查询年龄不为222岁
GET /lei/one/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"age": "222"
}
}
]
}
}
}
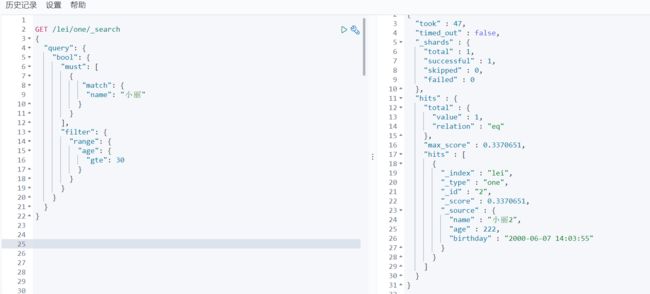
条件过滤
此方法与 where and 语法类似 但是 不同的是 其可以做大小于等一些逻辑判断 must 的话,仅仅只表示=匹配
语法解释 : 查询匹配名为小丽 并且 年龄大于等于30 where name=‘小丽’ and age >=30
GET /lei/one/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "小丽"
}
}
],
"filter": {
"range": {
"age": {
"gte": 30
}
}
}
}
}
}
还可以区间过滤 ,例如 查询名字为小丽 且年龄在22-30之间

精确查询
trem 精确查询 与match匹配不同 只会查询其精确到具体的条件
新建索引库 并插入数据
PUT /tremdb
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
},
"desc":{
"type": "text"
}
}
}
}
PUT /tremdb/_doc/1
{
"name":"曹操魏武帝",
"desc":"魏武帝,爱人妻,三国"
}
PUT /tremdb/_doc/2
{
"name":"刘备汉昭烈帝",
"desc":"汉昭烈帝,人称大耳贼,三国"
}
PUT /tremdb/_doc/3
{
"name":"孙权吴大帝",
"desc":"吴大帝,江东小霸王之弟,三国"
}
我们先前也讲过 keyword 是不会被分词的 那么我们这里可以测试一下
我们以名字作为精确搜索,“帝” 没有结果
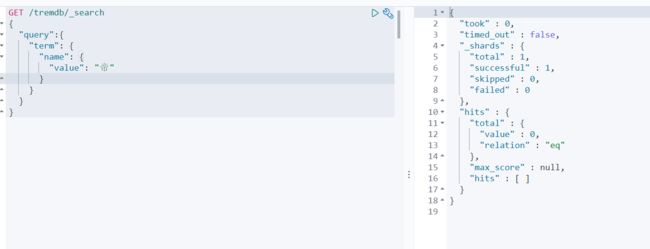
以武帝 作为精确搜索条件----还是未命中
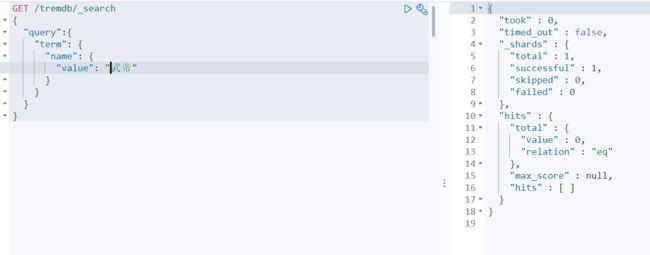
以曹操魏武 为精确搜索条件 ----还是未命中

以曹操魏武帝 为精确搜索条件 ----命中

可以得出结论 字段类型为keyword 的时候 ,其不会被分词器进行解析 只有以完整的值进行查询才会被命中
测试desc text 类型 text 会被分词 包含 帝 所以我们以帝 进行查询 则能获取到结果

精确查询多个

高亮显示
高亮,在搜索网站时 很常见 ,例如,我们的京东 /百度
搜一波 外星人 可以看到 外星人关键字 全部高亮显示了,那么是怎么做到的呢??

高亮!

可以看到 我搜索的小丽 结果 都添加了一个高亮字段 并用 标签包裹起来了,这就是高亮!
可能有人想问,高亮 为什么呢 ?别人都是红色的 ,我也想要!
可以,这个需求可以做的!
自定义高亮颜色
es 高亮 是支持我们自定义颜色的! 如何自定义呢 注意两个json 字段的使用!
"pre_tags": "", 前缀
"post_tags": "", 后缀
设置这两个标签后呢,其搜索的高亮 将会被前后缀包裹
完整查询语句:
注意,我这里定义了 标签,为了在 typora 以及csdn 上直接显示
GET /lei/one/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "小丽"
}
}
]
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"name":{}
}
}
}

小丽

基本的ES 语法差不多就到这里了! 后续随着学习的深度不断添加 !!!