开源分布式文件系统的对比
工作需要,整理了一份分布式文件系统对比的材料。网上看到过不少类似的材料,大家视角不同,差别不小,这里只是提供大家参考,不对的地方欢迎指导。图片和资料基本来源于官网,不再一一列举。
GlusterFS
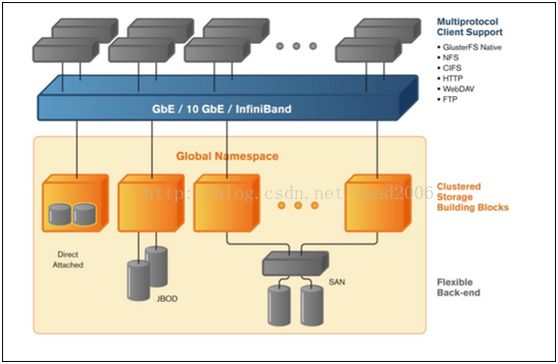

特点1:去中心化的分布式元数据架构
采用DHT的方式将每个file按照filename映射到节点上,
通过Davies Meyer hash函数对filename取hash值
如果file被rename,那么按照新的name计算hash后的新节点上会新建一个pointer,指向原来文件元数据所在节点。
特点2:模块化、协议栈式的文件系统
目前支持三种基本的功能和属性:
Replicator 副本,相当于raid1
Stripe 条带,相当于raid0
Distributed 分布式,相当于DHT
以上任意两个模块可以组合在一起。当时系统一旦选择其中一个属性,后面不能再修改。
目前主要的用法是Distributed+Replicator。选择了Distributed+Replicator后,某个文件就会在Gluster集群的两个节点上各有一份镜像。
其他:
存储节点上支持多种文件系统ext3、ext4、xfs、zfs
存储节点的硬件可以是JBOD,也可以是FC san
NAS集群功能通过CTDB实现
通过一个用户态的轻量级的nfsserver提供NFS接口
CIFS通过linux自带的Samba实现
全兼容Hadoop,可以替代HDFS
Client端提供最新的KVM的补丁,可以为KVM的虚拟机提供存储能力。
商业应用:
最初GlusterFS由Gluster INC提供商业服务。被intel收购后将全部源码开源。也有第三方的存储厂家提供基于GlusterFS的解决方案。
Ceph
Ceph主要架构来自于加州大学SantaCruz. 分校Sage Weil的博士论文。07年毕业后全职投入ceph的开发。12年才有stable版本发布。目前开发者社区是由Inktank公司主导并提供商业支持。
特点1.
采用集中式元数据管理,整体架构包括client(在kernel实现),MDS和OSD。文件目录树由MDS维护。文件被切分为大小相同的object,每个object被hash到不同的OSD(数据节点)上,OSD负责维护具体的文件数据。
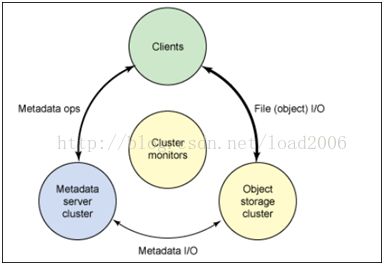
特点2.
支持元数据服务器集群,将目录树动态划分为若干子树,每个子树都有两个副本在两个MDS上提供服务,一个MDS同时支持多个不同的子树:
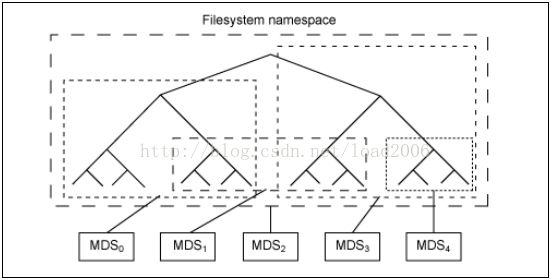
特点3
统一存储架构,支持多种接口。去掉MDS并增加若干Http proxy server后,就是P2P的对象存储,支持S3接口。去掉MDS并增加iSICSI Target Server还可以对外提供block接口。
特点4
Ceph中的一致性通过primary副本来保护。每个对象有一个主副本,客户端只跟主副本打交道,主副本所在的OSD负责把数据写到其他副本。
特点5
虚拟化环境的集成,支持多种元计算框架例如OpenStack、CloudStack、OpenNebula,Ceph已经可以集成到openstack作为cinder(弹性块存储,类似amazon的EBS)的一种实现。
商业应用:
目前ceph被视为一种实验性的文件系统,目前并无大型商业应用。根据Inktank公司公布的调查结果,目前在一些中小型的企业和组织中有商业应用,生产环境尚未有超过1P的案例。目前有些openstack厂家也在验证使用ceph为云计算环境提供虚拟化存储的可行性。
Lustre
Lustre是linux+cluster的缩写。Lustre是一个并行的分布式文件系统,主要应用领域是HPC(high performance compute)。目前Top100的超级计算机中,超过60的都是在使用lustre。

特点1:
传统的体系结构:MDS(元数据服务器) OSS(数据服务器)Client。MDS、OSS分别将元数据信息、数据信息持久化存储到本地文件系统中,本地文件系统采用的是ext4。每个文件会被切分成多个大小相等的object,多个object条带化到多个OSS上。MDS负责存储和管理file跟object映射关系。
特点2:
支持上万个客户端的并发读写。HPC领域的重要应用场景是多个客户端并发读写同一个文件。Lustre通过Distributed Lock Manager解决多客户端并发读写的问题。Lock包括两种,一个种是fileinode的锁,一种是file data的锁。Inode锁由mds统一管理,file data锁则由OSS管理,file data锁支持字节范围的锁。
商业支持发展:
最初组织Lustre开发的公司先被sun收购。Sun被oracle收购后大部分开发人员离开并组织了新公司,目前新公司已经被intel收购。由于lustre本身开源,传统SAN硬件厂家例如HDS、Dell、netapp也将lustre捆绑自己的硬件提供解决方案,并提供lustre技术支持。每年都会召一次全球Lustre用户大会LUG(lustre user group)。
MooseFS
MooseFS本质上是GoogleFS或HDFS的c实现。
集中式元数据管理,元数据服务器主备。
MooseFS的组成说明:
| 角色 |
角色作用 |
| 管理服务器 |
负责各个数据存储服务器的管理,文件读写调 |
| 元数据日志服务器 |
负责备份master 服务器的变化日志文件,文 |
| 数据存储服务器 |
负责连接管理服务器,听从管理服务器调度, |
| 客户机挂载使用 |
通过fuse 内核接口挂接远程管理服务器上所 |
Moosefs的功能特点:
支持snapshot
实现了文件回收站
支持动态扩容
小文件读写优化
Client支持多种操作系统包括:LinuxFreeBSD OpenSolaris和MacOS
商业应用:
中小型企业,学校、web网站。
存放普通文件、img、weblog等分结构化数据。
Web server备份 。
Kvm xen虚拟机镜像文件。
HDFS
HDFS是GoogleFS的开源实现。HDFS1.0版本架构是一种经典的分布式文件系统架构,包括个部分:独立的元数据服务器(name node),客户端(client),数据节点(data node)。文件被切分为大小相同的chunk分布在不同的data node上。Name node维护file与chunk的映射关系以及chunk的位置信息。Client跟data node交互进行数据读写。
这里主要看下HDFS2.0版本的架构改进,主要是亮点:
1. NameNode HA
HDFS1.0中mds是一个单点故障,虽然很多厂家有自己的HA方案,但是并不同意。HDFS2.0版本推出了官方的HA方案,主要思路是主备两个MDS,两个MDS共享一个san,用这个san来存储mds的日志文件。这种HA方案依赖于第三方san的可靠性。
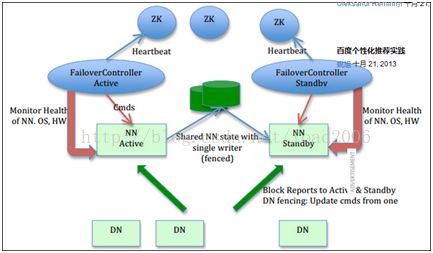
2. MDS federation
相当于MDS cluster。每个namenode都可以单独向外提供服务。每个namenode都管理所有的datanode。缺点是根目录下的某个子目录的所有文件只能位于一个namenode上。跟ZXDFS目前分域的方案实现比较像,只是没主域的概念。Client启动时要扫描所有的MDS以获取根目录下子目录跟namenode的对应关系。
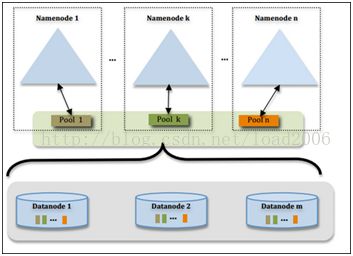
TFS
TFS是淘宝开源出来的专门存储图片的分布式文件系统。
TFS的总体架构也是仿照HDFS,这里看下区别:
1. HDFS中一个file由多个chunk组成。TFS反过来,一个64Mchunk会存放多个file。相当于小文件聚合。
2. TFS的filename包含了很多元数据信息力例如文件的chunkid和fileid,这样显著减轻了MDS的压力。
3. 文件在chunk中的偏移量mds不需要关心,具体维护是datanode来做的,减少了mds维护的元数据信息。
4. 为了防止磁盘碎片,datanode利用ext4的一些特性,例如fallocate,首先利用fallocate为每个chunk文件分配好空间。
5. Mds在为每个新文件分配chunk时,采用的是一致性hash的方法定位新chunk的位置。这样有利于集群的线性扩容。
Fast DFS
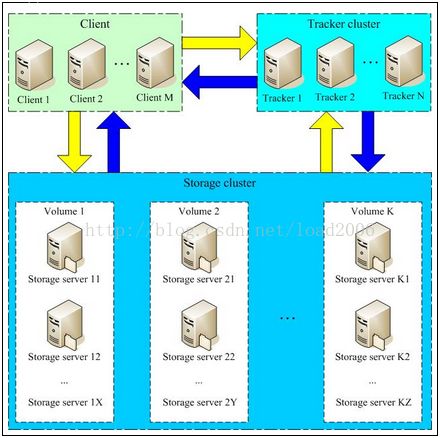
Fast DFS是一种纯轻量级的分布式文件系统,主要有国内开发者贡献。主要特点是结构简单,维护成本低,一般用于小型网站。架构特点:
1. 不维护目录树,client每次新建文件的时候由负载均衡器Tracker Server生成一个file id和path给client
2. 没有file和chunk概念,Tracker server只是负责轮选storage server给client使用。
3. Storage server分成不同的group,每个group之间是简单的镜像关系。
4. 读写文件时tracker负责不同组以及组内的负载均衡。
5. Strage server就是把文件写入到本地的文件系统中。