python学习(三)scrapy爬虫框架(二)——创建一个scrapy爬虫
在创建新的scrapy爬虫之前,我们需要先了解一下创建一个scrapy爬虫的基本步骤
第一步:确定要爬取的数据
以爬取豆瓣电影数据为例:
每部电影所要爬取的信息有:
- 片名:《头号玩家》
- 导演: 史蒂文·斯皮尔伯格
- 编剧: 扎克·佩恩 / 恩斯特·克莱恩
- 主演: 泰伊·谢里丹 / 奥利维亚·库克 / 本·门德尔森 / 马克·里朗斯 / 丽娜·维特 / 更多…
- 类型: 动作 / 科幻 / 冒险
所以items文件的代码如下:
#items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
movie_name = scrapy.Field()
movie_dir = scrapy.Field()
movie_editors = scrapy.Field()
movie_actors = scrapy.Field()
movie_type = scrapy.Field()
第二步:爬取所需的信息
确定了要爬取的信息后,只要去把所需的信息从网页上爬下来就可以了。
要爬取网页上的信息,我们需要先创建一个爬虫文件,在命令行中输入如下命令(必须在爬虫项目的文件夹里):
scrapy genspider spidername "domain"
#spidername是要创建的爬虫的名字,必须是唯一的,而且不能和爬虫项目名相同
#domain要爬取的url的范围,即你所要爬取的网站的域名,如:www.baidu.com创建好爬虫文件后,打开爬虫项目下的spiders文件夹,就可以看到我们刚刚创建的爬虫文件,用编辑器打开。
文件里已经定义好了start_urls,这是我们要开始爬取的网站链接,注意这是一个列表,可以放入多个url。当爬虫运行时就会把start_urls里的链接一个一个地拿出来,然后将返回的页面作为参数传递给parse函数来对网页中的信息进行提取,示例只爬取一个页面(头号玩家的详情页),代码如下:
# -*- coding: utf-8 -*-
#movieInfoSpider.py
import scrapy
#导入DouBanItem类
from douban.items import DoubanItem
class MovieinfoSpider(scrapy.Spider):
name = 'movieInfo'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/subject/4920389/?from=showing']
def parse(self, response):
#创建DoubanItem类
item = DoubanItem()
item['movie_name'] = response.xpath('//title/text()').extract()[0]
item['movie_dir'] = '导演:' + '/'.join(response.xpath('//div[@id="info"]/span[1]/span/a/text()').extract())
item['movie_editors'] = '编剧:' + '/'.join(response.xpath('//div[@id="info"]/span[2]/span/a/text()').extract())
item['movie_actors'] = '主演:' + '/'.join(response.xpath('//div[@id="info"]/span[3]/span/a/text()').extract())
item['movie_type'] = '类型:' + '/'.join(response.xpath('//div[@id="info"]/span[@property=
yield item提取到所需的信息后,用yield关键字将item传递给pipelines.py进行进一步的处理
第三步:对提取到的信息进行储存
pipelines.py文件获得item后将会调用管道函数来对item进行处理,这里我们只把电影的信息保存为txt文件,代码如下:
# -*- coding: utf-8 -*-
#pipelines.py
class DoubanPipeline(object):
def __init__(self):
self.fo = open('info.txt', 'wb')
def process_item(self, item, spider):
self.fo.write((item['movie_name'] + '\n').encode('utf-8'))
self.fo.write((item['movie_dir'] + '\n').encode('utf-8'))
self.fo.write((item['movie_editor'] + '\n').encode('utf-8'))
self.fo.write((item['movie_actors'] + '\n').encode('utf-8'))
self.fo.write((item['movie_type'] + '\n').encode('utf-8'))
#这里必须返回item,否则程序会一直等待,直到返回item为止
return item
def close_spider(self, spider):
self.fo.close()
#__init__, 和close_spider 函数相当于c++里的构造函数和析构函数
第四步:在setting.py里开启DoubanPipeline管道
这里只截取部分相关的代码:
# Obey robots.txt rules
#是否遵循网站对爬虫的规则,一般设为False,但默认为True
ROBOTSTXT_OBEY = False
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'douban.pipelines.DoubanPipeline': 300,
}
#设置请求头,模拟浏览器
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36'
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'bid=uzUipzgnxdY; ll="118267"; __utmc=30149280; __utmz=30149280.1523088054.4.4.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=223695111; __utmz=223695111.1523088054.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=u46EFxFlzD46PvWysMULc80N9s8k2pp4; _vwo_uuid_v2=DC94F00058615E2C6A432CB494EEB894B|64bbcc3ac402b9490e5de18ce3216c5f; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1523092410%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DFIqLEYPF6UnylF-ja19vuuKZ51u3u5gGYJHpVJ5MRTO-oLkJ_C84HBgYi5OulPwl%26wd%3D%26eqid%3Dd260482b00005bbb000000055ac87ab2%22%5D; _pk_id.100001.4cf6=cbf515d686eadc0b.1523088053.2.1523092410.1523088087.; _pk_ses.100001.4cf6=*; __utma=30149280.1054682088.1514545233.1523088054.1523092410.5; __utmb=30149280.0.10.1523092410; __utma=223695111.979367240.1523088054.1523088054.1523092410.2; __utmb=223695111.0.10.1523092410',
'Host': 'movie.douban.com',
'Upgrade-Insecure-Requests': '1',
}最后:运行爬虫
进入到爬虫项目的文件夹里,执行命令:
scrapy crawl movieInfoSpider结果截图:
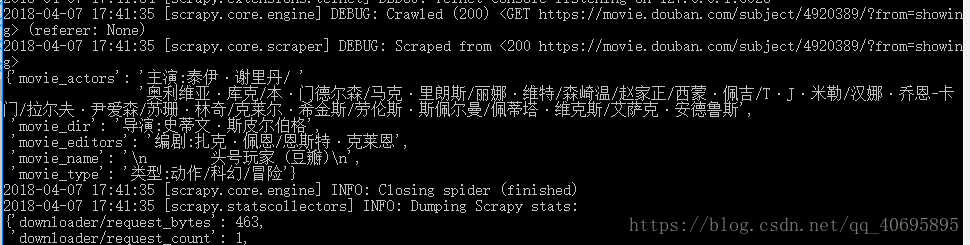
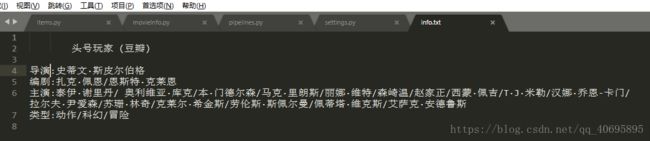
总结:scrapy爬虫构建顺序 items.py–>spiders–>pipelines.py–>settings.py
上一篇:python学习(三)scrapy爬虫框架(一)——scrapy框架简介
下一篇:python学习(三)scrapy爬虫框架(三)——爬取壁纸保存并命名