教女朋友学会用win10+yolov3+python训练自己的模型
times:2020/3/23
操作系统:win10
环境:python 3.6
因为我之前把所有内容写在一篇文章里非常的乱,所以本文主线是训练自己的 yolo.h5 去识别图像中的人,所有小细节的操作,我都在文中添加了链接,新手的话需要注意看一下。
// 有任何的问题都可以直接评论,还有资料的话直接留言邮箱,说明问题//
//也可以评论下加下微信询问//
大家一起加油学习yolo,之后我会再出一篇详细介绍yolo代码的文章
新创建的小小交流群:977947271 想要资料的也可以在群里要哦
2020/5/30:
近日每天都有十几个很明显的小号加群,而且有的大号进群竟然打广告和卖不良物品,经我和群友讨论后,加群需要1元钱,但是进群后我会将钱退还给大家,只是为了过滤一些不好的人。
如果你是 yolo 小白,或者环境配置等一直报错,请先参阅上一篇博文:keras-yolov3目标检测详解——适合新手 (环境配置、用官方权重识别自己的图片)
本文目的:
前面有篇文章说的是利用官方的权重直接识别自己的图片,我也展示了识别的效果。
今天我介绍一下如何创建自己的数据集去训练属于自己的 model
前提准备:
1、配置好环境的 python、anaconda 或 pycharm
2、labelimg 软件:下载方法: labelimg的下载与使用
3、准备一些图片,创建训练需要的 VOC 文件
(1) 官方的VOC2007下载链接:voc2007下载链接,可以从这里找需要的图片,或者一些有基础的朋友可以写爬虫去爬一些图片
(2) voc2007百度网盘下载链接:
链接:https://pan.baidu.com/s/18wqRTZDSz5NQEtvq0u0a1g
提取码:hexy
(3) 可以自己准备图片,不过最好准备多一点
.
.
正式训练步骤:
一、准备自己的voc2007数据集
先用 pycharm 或 spyder 打开 keras-yolo3 文件夹,用 pycharm 或 spyder 是为了看文件夹更方便,直接在 anaconda 里运行也是可以的
1、打开文件夹
先按照这篇文章的步骤操作:keras-yolov3目标检测详解——适合新手
完成后打开的文件夹应该是这样的:
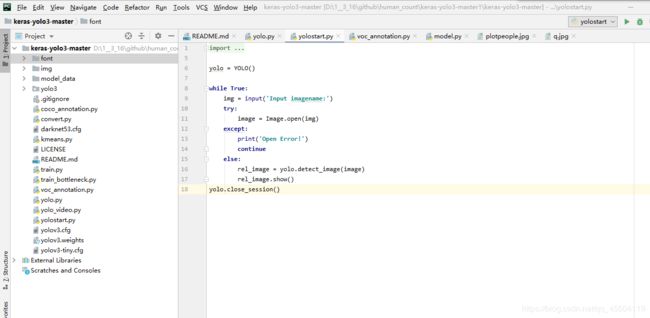
2、新建voc2007数据集(存放自己的图片及标注信息)
新建的文件夹:如下
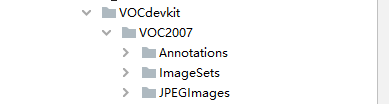
ImageSets 文件夹下还有个名为 Main 的小文件夹
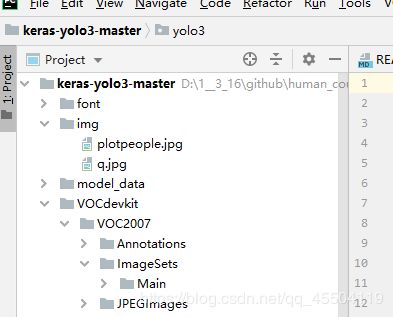
VOCdevkit{
VOC2007{ Annotations
ImageSets{main}
JPEGImages }
}
虽然表达的很丑,但是上面有图,应该还是可以看明白的
注意:文件夹的名称必须和上面展示的一样,这是 yolo 默认的
不然还需要改代码才行
3、用labelimg软件对自己的图片进行信息标注
----labelimg 的使用方法:labelimg 下载和标注 xlm 文件
想要训练自己的模型就要学会 labelimg 的使用,实在不想学的…就评论一下邮箱,我直接把我标注好的 VOC2007 文件夹打包发给你们吧
(1)需要训练的图片放在 JPEGImages 里面:
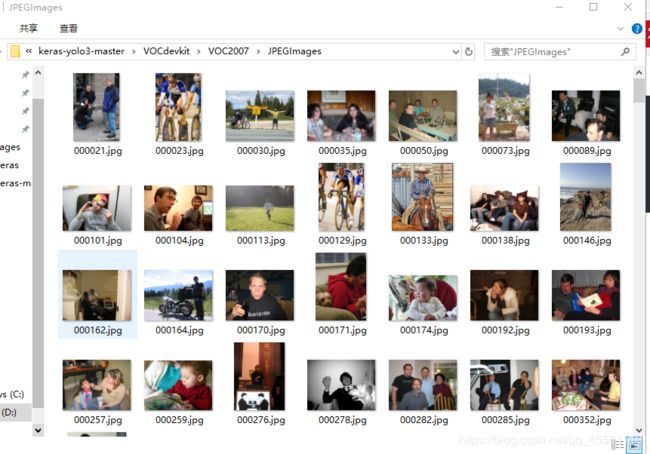
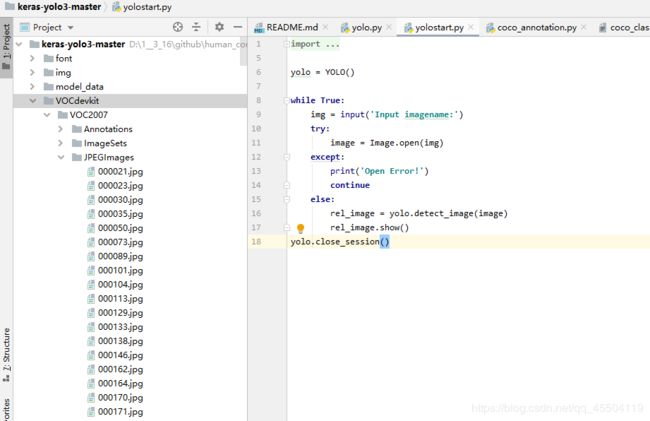
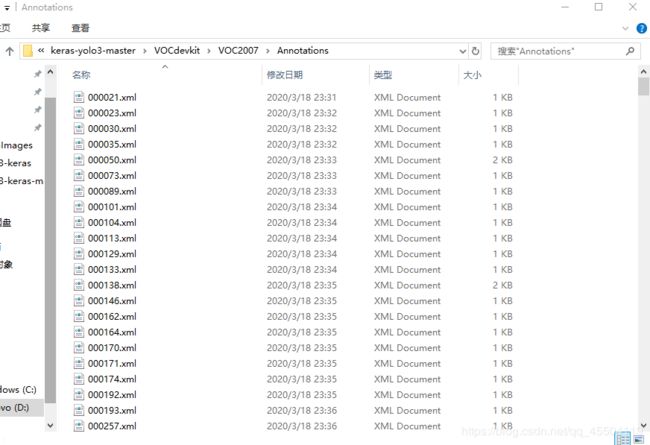
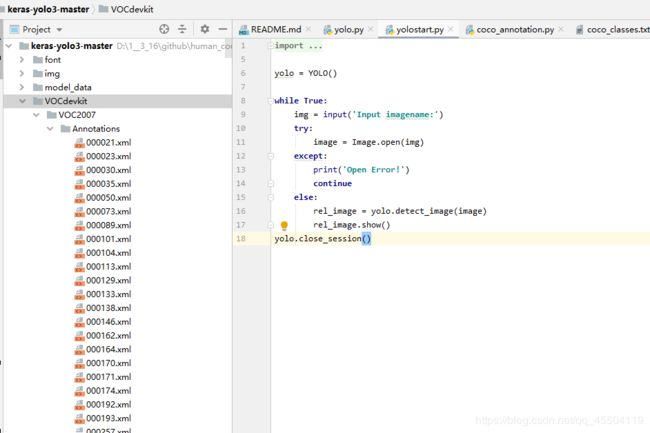
(2)labelimg 标注的 xlm 文件放在 Annotations 里面:
4、在 VOC2007 里新建一个 py 文件
我这里取名 voc.py
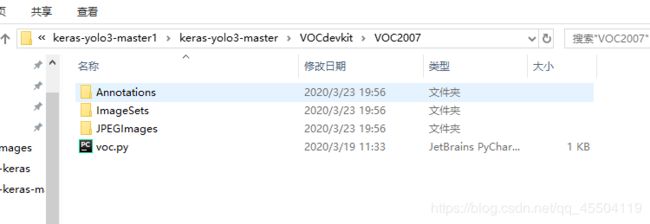
voc.py 的代码:
import os
import random
trainval_percent = 0.2 #测试集占0.2
train_percent = 0.8 #训练集占0.8
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
直接复制以上代码即可
然后运行 voc.py 文件
运行成功的话 mian 文件夹里会多了四个 txt 文件

完成以上所有步骤,VOC 的处理就完成了
.
二、进行训练前的最后准备
1、修改 voc_annotation.py 文件并运行
更改这里的 classes 的数量,你voc2007里标注了哪几种,你就留哪几种就行

比如我的 voc 中只标注了 “person”,那我只留下“person”,然后再运行一下就行
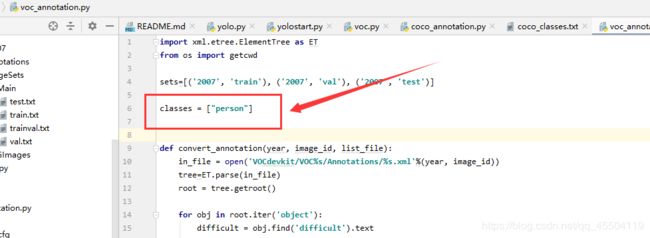
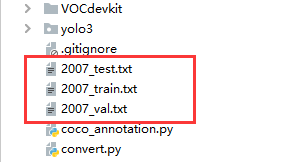
运行完成后会多出这几个 txt 文件
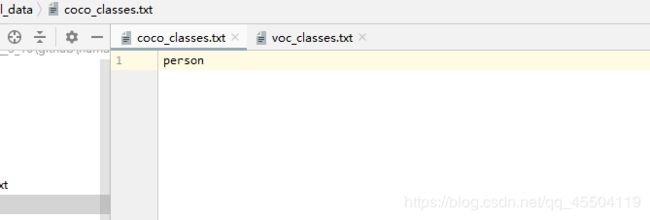
2、修改 model_data
将 coco_classes.txt 和 voc_classes.txt 中也只留下VOC2007 中所标注的那个类型

比如我标注的只有 “person”
那我只留下“person”

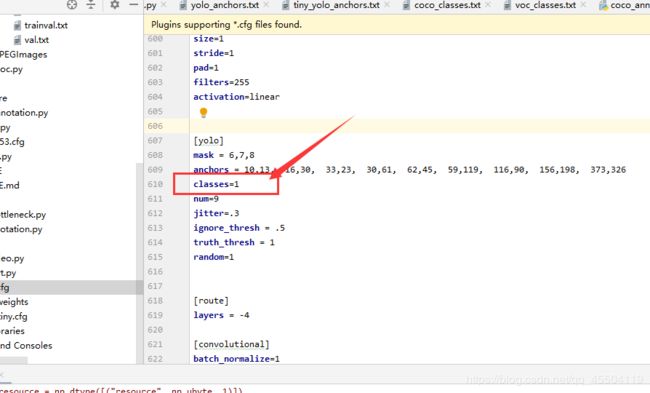
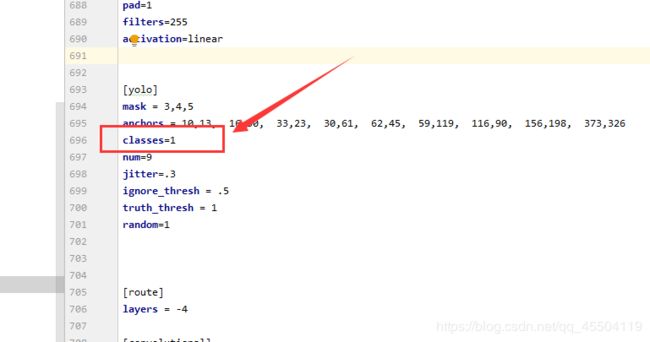
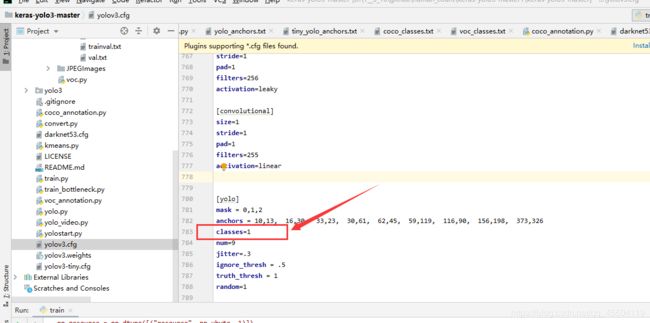
3、修改 yolo3.cfg
大概在 610、696 和 783 行的位置,把 classes 的数值都改为 1
4、添加官方权重
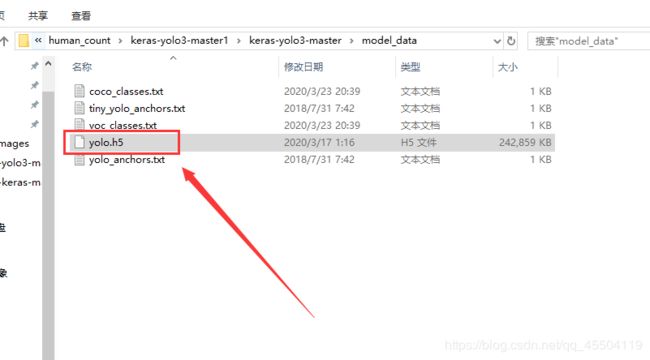
按照上篇博文步骤进行的朋友应该下载好了 yolov3.weights 文件并转为了 yolo.h5 文件
附上上篇博文的链接(里面有下载链接和转化方法):keras-yolov3目标检测详解——适合新手
将 yolo.h5 改名为 yolo_weights.h5

5、新建 logs 文件夹存放训练的 权重文件

6、开始训练
在 keras-yolo3-master 文件夹下新建 一个名为 trainyolo.py 的文件
为什么不用 源文件中的train.py呢??(因为我运行的时候一直出现库的报错…建议按照我的方法来)
trainyolo.py 的代码(直接复制即可):
import numpy as np
import tensorflow as tf
import keras.backend as K
from keras.layers import Input, Lambda
from keras.models import Model
from keras.optimizers import Adam
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from yolo3.model import yolo_body
from yolo3.model import yolo_loss
from keras.backend.tensorflow_backend import set_session
from yolo3.utils import get_random_data
def get_classes(classes_path):
'''loads the classes'''
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def get_anchors(anchors_path):
'''loads the anchors from a file'''
with open(anchors_path) as f:
anchors = f.readline()
anchors = [float(x) for x in anchors.split(',')]
return np.array(anchors).reshape(-1, 2)
def data_generator(annotation_lines, batch_size, input_shape, anchors, num_classes):
'''data generator for fit_generator'''
n = len(annotation_lines)
i = 0
while True:
image_data = []
box_data = []
for b in range(batch_size):
if i==0:
np.random.shuffle(annotation_lines)
image, box = get_random_data(annotation_lines[i], input_shape, random=True)
image_data.append(image)
box_data.append(box)
i = (i+1) % n
image_data = np.array(image_data)
box_data = np.array(box_data)
y_true = preprocess_true_boxes(box_data, input_shape, anchors, num_classes)
yield [image_data, *y_true], np.zeros(batch_size)
def preprocess_true_boxes(true_boxes, input_shape, anchors, num_classes):
assert (true_boxes[..., 4]<num_classes).all(), 'class id must be less than num_classes'
num_layers = len(anchors)//3
anchor_mask = [[6,7,8], [3,4,5], [0,1,2]] if num_layers==3 else [[3,4,5], [1,2,3]]
true_boxes = np.array(true_boxes, dtype='float32')
input_shape = np.array(input_shape, dtype='int32') # 416,416
boxes_xy = (true_boxes[..., 0:2] + true_boxes[..., 2:4]) // 2
boxes_wh = true_boxes[..., 2:4] - true_boxes[..., 0:2]
true_boxes[..., 0:2] = boxes_xy/input_shape[:]
true_boxes[..., 2:4] = boxes_wh/input_shape[:]
m = true_boxes.shape[0]
grid_shapes = [input_shape//{0:32, 1:16, 2:8}[l] for l in range(num_layers)]
y_true = [np.zeros((m,grid_shapes[l][0],grid_shapes[l][1],len(anchor_mask[l]),5+num_classes),
dtype='float32') for l in range(num_layers)]
anchors = np.expand_dims(anchors, 0)
anchor_maxes = anchors / 2.
anchor_mins = -anchor_maxes
valid_mask = boxes_wh[..., 0]>0
for b in range(m):
wh = boxes_wh[b, valid_mask[b]]
if len(wh)==0: continue
wh = np.expand_dims(wh, -2)
box_maxes = wh / 2.
box_mins = -box_maxes
intersect_mins = np.maximum(box_mins, anchor_mins)
intersect_maxes = np.minimum(box_maxes, anchor_maxes)
intersect_wh = np.maximum(intersect_maxes - intersect_mins, 0.)
intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1]
box_area = wh[..., 0] * wh[..., 1]
anchor_area = anchors[..., 0] * anchors[..., 1]
iou = intersect_area / (box_area + anchor_area - intersect_area)
best_anchor = np.argmax(iou, axis=-1)
for t, n in enumerate(best_anchor):
for l in range(num_layers):
if n in anchor_mask[l]:
i = np.floor(true_boxes[b,t,0]*grid_shapes[l][1]).astype('int32')
j = np.floor(true_boxes[b,t,1]*grid_shapes[l][0]).astype('int32')
k = anchor_mask[l].index(n)
c = true_boxes[b,t, 4].astype('int32')
y_true[l][b, j, i, k, 0:4] = true_boxes[b,t, 0:4]
y_true[l][b, j, i, k, 4] = 1
y_true[l][b, j, i, k, 5+c] = 1
return y_true
config = tf.ConfigProto()
config.gpu_options.allocator_type = 'BFC'
config.gpu_options.per_process_gpu_memory_fraction = 0.7
config.gpu_options.allow_growth = True
set_session(tf.Session(config=config))
if __name__ == "__main__":
annotation_path = '2007_train.txt'
classes_path = 'model_data/voc_classes.txt'
anchors_path = 'model_data/yolo_anchors.txt'
weights_path = 'model_data/yolo_weights.h5'
class_names = get_classes(classes_path)
anchors = get_anchors(anchors_path)
num_classes = len(class_names)
num_anchors = len(anchors)
log_dir = 'logs/'
input_shape = (416,416)
K.clear_session()
image_input = Input(shape=(None, None, 3))
h, w = input_shape
print('Create YOLOv3 model with {} anchors and {} classes.'.format(num_anchors, num_classes))
model_body = yolo_body(image_input, num_anchors//3, num_classes)
print('Load weights {}.'.format(weights_path))
model_body.load_weights(weights_path, by_name=True, skip_mismatch=True)
y_true = [Input(shape=(h//{0:32, 1:16, 2:8}[l], w//{0:32, 1:16, 2:8}[l], \
num_anchors//3, num_classes+5)) for l in range(3)]
loss_input = [*model_body.output, *y_true]
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss',
arguments={'anchors': anchors, 'num_classes': num_classes, 'ignore_thresh': 0.5})(loss_input)
model = Model([model_body.input, *y_true], model_loss)
freeze_layers = 249
for i in range(freeze_layers): model_body.layers[i].trainable = False
print('Freeze the first {} layers of total {} layers.'.format(freeze_layers, len(model_body.layers)))
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=False, period=2)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=2, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=6, verbose=1)
val_split = 0.2
with open(annotation_path) as f:
lines = f.readlines()
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
num_val = int(len(lines)*val_split)
num_train = len(lines) - num_val
if True:
model.compile(optimizer=Adam(lr=1e-3), loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
batch_size = 1
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=50,
initial_epoch=0,
callbacks=[logging, checkpoint])
model.save_weights(log_dir + 'trained_weights_stage_1.h5')
for i in range(freeze_layers): model_body.layers[i].trainable = True
if True:
model.compile(optimizer=Adam(lr=1e-4), loss={
'yolo_loss': lambda y_true, y_pred: y_pred})
batch_size = 1
print('Train on {} samples, val on {} samples, with batch size {}.'.format(num_train, num_val, batch_size))
model.fit_generator(data_generator(lines[:num_train], batch_size, input_shape, anchors, num_classes),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=data_generator(lines[num_train:], batch_size, input_shape, anchors, num_classes),
validation_steps=max(1, num_val//batch_size),
epochs=100,
initial_epoch=50,
callbacks=[logging, checkpoint])
model.save_weights(log_dir + 'last1.h5')
然后运行trainyolo.py 的代码
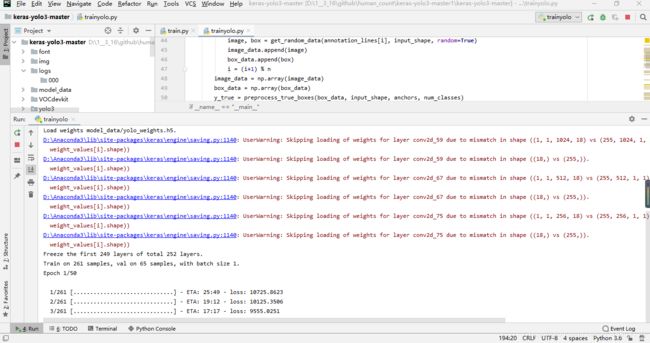
成功开始训练,训练时间比较长,需要耐心等待
.
.
训练完成:
因为我的电脑配置比较差,所以训练了很长很长时间,这是我前几天训练的结果
训练好的权重都放在 logs 文件夹下的 000 文件夹里:
按理说训练会经过两个阶段,且自动从一堆 loss 中选则出 loss最低的文件(应该是 earlystop函数的作用):
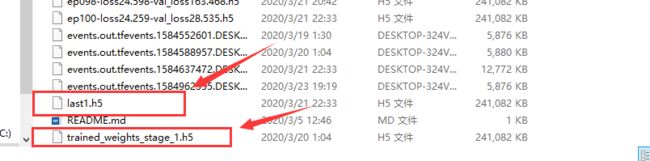
应该就是下面的框选的这两个 h5文件,都可以使用
使用的方法就和前面那篇博文操作一样了(用这个h5权重模型去识别自己图片),下面给大家展示一下我训练的模型的结果吧

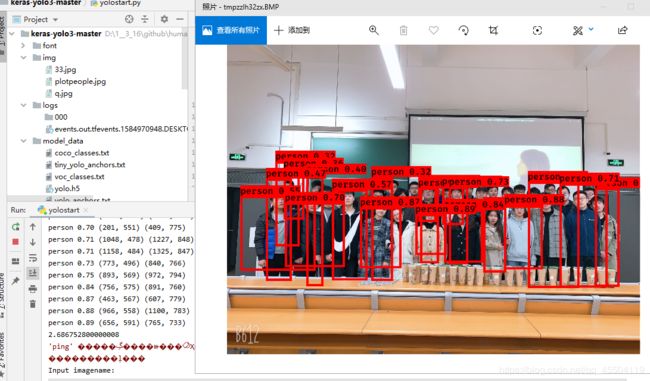
对比使用官方的权重文件来说,我的模型可以仅仅识别出图片中的人体,而且识别效果还不赖,感觉还不错吧 哈哈哈
总结:
以上过程皆为刚刚我亲自操作,全程没有任何问题
如果有朋友对这篇文章的任何内容感到不明白的请及时评论提出问题,我怕时间一久我也会忘,想要资料的直接评论你们的联系方式就行,我有时间会回复的。
这个暂时告一段落,接下来我会在 matlab 中找一些算法去实现同样的功能,有兴趣的朋友可以评论一下一起探讨。